メール自動処理システムの開発

プロジェクト背景
多くの企業で共通する課題として、メールの効率的な管理と迅速な返信対応が挙げられます。特に、担当者が不在の場合や、個別のメールが見落とされるリスクは大きな問題です。私の勤務先では、顧客からのFAXをPDFで管理するためにCanonのImageWareを導入していますが、同様に顧客からのメールもPDF化して一元管理するニーズが高まっていました。
システム概要
このプロジェクトでは、顧客からのメールを自動でPDF化し、それをシステムにドラッグアンドドロップすることで以下のプロセスを自動化するシステムを開発しました:
PDFのテキスト抽出: ドラッグアンドドロップされたPDFからテキストを抽出し、その内容を解析します。
メールの選定: 抽出したテキストに基づき、該当するメールをCybozu Officeのメールボックスから検索します。
自動返信: 特定の条件に基づいて、適切なフォーマットで自動返信を行います。
成果と影響
業務効率の向上:
営業担当者数名が対応する月間600~700通の見積依頼や注文依頼のメールを、担当者の垣根を超えて全員で処理できるシステムが完成しました。
これにより、メールの処理が迅速化し、対応漏れや遅延が大幅に減少しました。
コスト削減:
システム導入により、メール対応時間が1通あたり平均5分短縮され、月間で約50時間の業務時間が削減されました。
この時間短縮により、他の重要業務に時間を割けるようになり、全体の業務効率が向上しました。
顧客満足度の向上:
顧客からの問い合わせや依頼に対して、迅速かつ正確に対応できるようになりました。
これにより、顧客満足度が向上し、リピート注文の増加につながっています。
ストレス軽減:
担当者が休暇をとっても、メール対応を気にする必要がなくなり、心労が軽減されました。
社員が安心して休暇を取れるようになり、ワークライフバランスの向上にも貢献しました。
開発の経緯とモチベーション
私は営業担当でありながら、独学でPythonを学び、業務実務者ならではの視点で今回の課題を解決しました。このシステムの開発を通じて、メール処理の効率化と担当者不在時の業務継続性を確保することができました。PDF化されたメールを用いることで、メールのセキュリティやアクセス制御も強化され、企業の情報管理の質も向上しました。
このプロジェクトは、私自身のプログラミングスキルの向上にも大きく寄与しました。学んだ技術は他の業務プロセスにも応用可能であり、さらなる業務効率化を実現するための基盤となっています。今後もシステムの改良を続け、より多機能で高効率な自動化ツールの開発を目指していきます。
開発期間
初期開発: 2週間
定期的なアップデートを含む最終完成: 約3か月
私の役割
業務プロセスの課題を特定し、効率化を図るためのシステムを設計。
Pythonを独学し、全てのコーディングとシステム開発を担当。
セキュリティとユーザビリティを考慮したシステムの実装。
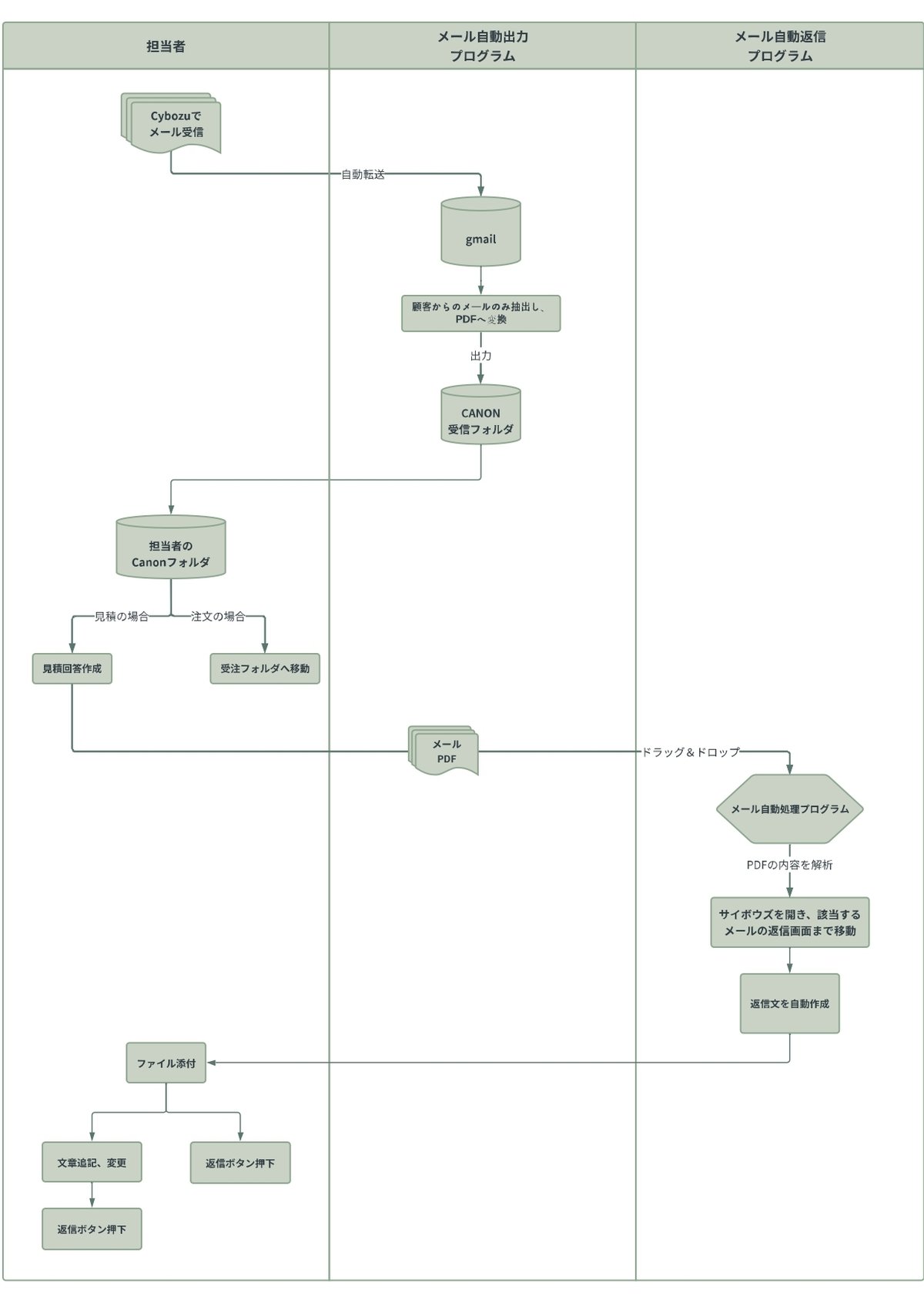
処理フロー
処理のフローをLucid Chartで作成しました。
メールのPDF出力〜自動処理〜最終処理までの流れを解説しています。
コード解説
PDFのテキスト抽出
まず、ドラッグアンドドロップされたPDFからテキストを抽出します。
def clean_body_text(body_text):
"""
入力された本文テキストから漢字、ひらがな、カタカナ、および特定の特殊文字を削除します。
引数:
body_text (str): クリーンアップするメールテキスト。
戻り値:
str: 指定された文字が削除されたクリーンなメールテキスト。
例外:
SystemExit: テキストの置換中にエラーが発生した場合、エラーを表示し、プログラムを終了します。
"""
kanji = u'[一-龥]'
hira_kata = u'[ぁ-んァ-ン]'
try:
replaced_body = re.sub(kanji, "", body_text)
replaced_body = re.sub(hira_kata, "", replaced_body)
replaced_text = replaced_body.replace("<", "").replace(">", "").replace('"', "")
except Exception as e:
print(f"bodyの変換に失敗しました。エラー内容:{e}")
sys.exit()
return replaced_textメールの宛名情報より、受信者のサイボウズIDを取得
※IDは暗号化されたiniファイルで管理
def return_id(replaced_split):
"""
指定されたリストからIDを探して返します。
この関数は、ID辞書のキーを `replaced_split` リスト内で探し、
見つかった場合にいくつかのグローバル変数を更新し、
最も近いIDのキーを返します。
引数:
replaced_split (list): 分割されたテキストのリスト。
戻り値:
int: 最も近いIDの距離のキー。
グローバル変数の更新:
download_mail_add (str): 見つかったIDを格納します。
login_id (str): 見つかったIDに対応するログインIDを格納します。
distance_id_dict (dict): 距離をキーとし、IDを値とする辞書を更新します。
distance_pic_dict (dict): 距離をキーとし、姓を値とする辞書を更新します。
処理の流れ:
1. `id_dict` の各キーを `replaced_split` リスト内で探します。
2. キーが見つかった場合、そのキー (`IDS`) と対応する値 (`id_dict[IDS]`) を取得します。
3. `replaced_split` リスト内で、`IDS` と `"To:"` のインデックスを探し、それらのインデックスの合計を計算します。
- `distance_to = replaced_split.index(IDS) + replaced_split.index("To:")`
4. 計算された距離をキーとして、対応するIDと姓をそれぞれ `distance_id_dict` と `distance_pic_dict` に格納します。
5. 最も小さい距離のキーを返します。
"""
global download_mail_add, login_id
for IDS in id_dict.keys():
if IDS in replaced_split[0]:
download_mail_add = IDS
login_id = id_dict[IDS]
distance_to = replaced_split.index(IDS) + replaced_split.index("To:")
distance_id_dict[distance_to] = id_dict[IDS]
distance_pic_dict[distance_to] = last_name_dict[IDS]
return min(distance_id_dict.keys())受信者のサイボウズのパスワードを取得
※PASSは暗号化されたiniファイルで管理
def return_pass(replaced_split):
"""
指定されたリストからパスワードを探して返します。
この関数は、パスワード辞書のキーを `replaced_split` リスト内で探し、
見つかった場合にいくつかのグローバル変数を更新し、
最も近いパスワードのキーを返します。
引数:
replaced_split (list): 分割されたテキストのリスト。
戻り値:
int: 最も近いパスワードの距離のキー。
グローバル変数の更新:
login_pass (str): 見つかったパスワードを格納します。
distance_pass_dict (dict): 距離をキーとし、パスワードを値とする辞書を更新します。
処理の流れ:
1. `pass_dict` の各キーを `replaced_split` リスト内で探します。
2. キーが見つかった場合、そのキー (`PASS`) と対応する値 (`pass_dict[PASS]`) を取得します。
3. `replaced_split` リスト内で、`PASS` と `"To:"` のインデックスを探し、それらのインデックスの合計を計算します。
- `distance_pass = replaced_split.index(PASS) + replaced_split.index("To:")`
4. 計算された距離をキーとして、対応するパスワードを `distance_pass_dict` に格納します。
5. 最も小さい距離のキーを返します。
"""
global login_pass
for PASS in pass_dict.keys():
if PASS in replaced_split[0]:
login_pass = pass_dict[PASS]
distance_pass = replaced_split.index(PASS) + replaced_split.index("To:")
distance_pass_dict[distance_pass] = pass_dict[PASS]
return min(distance_pass_dict.keys())メール処理メイン関数 ※一部を公開
def mail_process():
"""
メールの処理を行う関数です。
この関数は、指定されたウェブページからメール情報を取得し、ユーザーIDとパスワードを使ってログインし、
メールの本文を解析して特定の条件に基づいて返信またはダウンロードを行います。
グローバル変数:
var: モードを示す変数。0は返信モード、1はダウンロードモード。
body_text: メールの本文テキスト。
mail_index_title: メールのタイトル。
split_text: 分割されたテキスト。
ratio_dict: マッチング率を保持する辞書。
flg: 処理の進行状態を示すフラグ。
fixed_flg: 時刻の調整が必要かどうかを示すフラグ。
cus_name: 顧客の名前。
distance_id_dict: IDを保持する辞書。
distance_pass_dict: パスワードを保持する辞書。
distance_pic_dict: 担当者を保持する辞書。
distance_from_dict: 送信者を保持する辞書。
last_name_dict: 苗字の辞書。
min_id: 最小インデックスの合計を持つID。
min_pass: 最小インデックスの合計を持つパスワード。
mail_title_sub_flg: メールタイトルのサブフラグ。
max_dict: マッチング率が最大の辞書。
attached_pass_index: 添付ファイルのパスワードインデックス。
detected_mail: 検出されたメール数。
処理の流れ:
1. 変数と辞書をリセット。
2. メールのログインページを開く。
3. メールの本文テキストをクリーンアップし、分割。
4. 最小インデックスの合計を持つIDとパスワードを取得。
5. ログイン処理を行う。
6. メールの送信者情報を取得。
7. メール本文を解析し、返信またはダウンロード処理を行う。
エラー処理:
- メール本文のクリーンアップやID/PASSの取得に失敗した場合、エラーメッセージを表示し、プログラムを終了する。
- メールが見つからない場合やメールが読み取れない場合も、エラーメッセージを表示し、プログラムを終了する。
返信モード:
- 見つかったメールに対して返信を行う。必要に応じて、代理での返信を行う。
ダウンロードモード:
- 見つかったメールに添付されたファイルをダウンロードする。
"""
global var, body_text, mail_index_title, split_text
global ratio_dict, flg, fixed_flg, cus_name
global distance_id_dict, distance_pass_dict, distance_pic_dict, distance_from_dict
global last_name_dict, min_id, min_pass, mail_title_sub_flg, max_dict, attached_pass_index
global detected_mail
detected_mail = 0
ratio_dict = {}
distance_pic_dict = {}
distance_from_dict = {}
cus_name = ""
download_flg = False
mail_title_sub_flg = False
flg = None
min_from = None
subject = None
driver = webdriver.Chrome(service=chrome_service, options=options)
wait = WebDriverWait(driver, 3)
driver.get('https://********.cybozu.com/o/ag.cgi?page=MailIndex#fid=inbox')
user_name = driver.find_element(By.ID, "username-:0-text")
password = driver.find_element(By.ID, "password-:1-text")
login = driver.find_element(By.CLASS_NAME, "login-button")
replaced_split = clean_body_text(body_text).split()
try:
min_id = return_id(replaced_split)
min_pass = return_pass(replaced_split)
except ValueError as e:
driver.close()
show_error("エラー発生", e)
try:
user_name.send_keys(distance_id_dict[min_id])
password.send_keys(distance_pass_dict[min_pass])
except Exception:
messagebox.showinfo("メールアドレス不明", "ユーザー情報にてログインを実施します。")
user_name.send_keys("*******")
password.send_keys("********")
handle_array = driver.window_handles
driver.switch_to.window(handle_array[0])
login.click()
distance_id_dict = {}
distance_pass_dict = {}
# メールの返信処理
if var.get() == 0:
reply_button = wait.until(EC.presence_of_element_located((By.PARTIAL_LINK_TEXT, "全員に返信")))
reply_button.click()
handle_array = driver.window_handles
driver.switch_to.window(handle_array[1])
try:
pyautogui.hotkey("shift", "tab")
pyautogui.hotkey("shift", "tab")
pyautogui.hotkey("ctrl", "home")
pyperclip.copy("【返信】")
pyautogui.hotkey("ctrl", "v")
pyautogui.press("tab")
pyautogui.press("tab")
pyperclip.copy(sentence)
except Exception:
messagebox.showerror("エラー発生", "文章が貼り付けられませんでした")
pyautogui.hotkey("ctrl", "v")
# 添付ファイルのダウンロード処理
elif var.get() == 1:
max_dict.click()
try:
download_link = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,
"#view_mail > table:nth-child(2) > tbody > tr.view_content > td > div.vr_viewContentsAttach > div:nth-child(1) > div > a")))
download_link.click()
except NoSuchWindowException as e:
show_error("エラー", f"エラー内容:{e} 添付ファイルが見つかりません。プログラムを終了します。")エラーメッセージの表示
def show_error(title, error):
"""
エラーメッセージをメッセージボックスに表示し、移動をリセットし、イベントをクリアして、ルートアプリケーションを終了します。
引数:
title (str): エラーメッセージのタイトル。
error (str): 表示するエラーメッセージ。
戻り値:
None
"""
messagebox.showinfo(f"{title}", f"{error}")
Event.clear()
root.quit()ドラッグ&ドロップ機能
def drop(event):
"""
ドラッグ&ドロップされたファイルを処理する関数です。
この関数は、ドラッグ&ドロップされたPDFファイルを読み込み、その内容をテキストに変換して
メール処理スレッドを開始します。
引数:
event: ドラッグ&ドロップイベント。
グローバル変数:
var: モードを示す変数。
file: ドラッグ&ドロップされたファイルのパス。
thread1: メール処理を行うスレッド。
thread2: 予備のスレッド。
thread_flg: スレッドが実行中かどうかを示すフラグ。
split_text: 分割されたテキスト。
body_text: PDFから抽出された本文テキスト。
mail_title: メールのタイトル。
text: ドラッグ&ドロップされたファイルパスを表示するためのテキストオブジェクト。
処理の流れ:
1. ドラッグ&ドロップされたファイルパスを取得し、`file` 変数に格納します。
2. PDFファイルを読み込み、テキストに変換します。
3. テキストを分割して `split_text` 変数に格納します。
4. メール処理スレッドを開始します。
"""
global file, thread1, split_text, body_text
text.set(event.data)
file = event.data.strip("{}")
fp = open(file, "rb")
outfp = StringIO()
rmgr = PDFResourceManager()
lprms = LAParams()
device = TextConverter(rmgr, outfp, laparams=lprms)
iprtr = PDFPageInterpreter(rmgr, device)
try:
for page in PDFPage.get_pages(fp):
iprtr.process_page(page)
except Exception as e:
print(e)
body_text = outfp.getvalue()
outfp.close()
device.close()
fp.close()
split_text = body_text.split()
if not thread_flg:
thread_flg = True
root.after(200, thread1.start())
else:
thread1 = threading.Thread(target=mail_process)
root.after(200, thread1.start())開発の経緯とモチベーション
このプロジェクトは、日々の業務の中で繰り返し発生する手動作業を減らし、効率を向上させることを目的として始めました。特に、メールの処理やファイルのダウンロードは時間がかかり、ミスが起こりやすい部分でもありました。これを自動化することで、より迅速かつ正確な処理が可能となり、業務全体の生産性向上に繋がりました。
また、Pythonを学びながら実際に業務に応用することで、プログラミングのスキルを実践的に磨くことができました。これにより、より高度な自動化ツールを開発するための基盤が築かれました。
今後も、このプロジェクトをさらに改良し、新たな機能を追加することで、業務のさらなる効率化を目指していきたいと考えています。
この記事が気に入ったらサポートをしてみませんか?