「Aidemy成果物」東京都23区駅から徒歩20分以内最上階中古マンションの最もお買い得の物件予測

背景
普段上階からの騒音のせいで、仕事や学習に集中力できなかったり、睡眠時間や睡眠品質への影響もかなりあったりするので、ずっとマンションの最上階に憧れている。
ちょうど現在pythonを勉強しているので、東京都23区中古マンションの最上階物件を調べ販売価格を予測し一番価値がある物件を探したいと思う。さらに、物件の価値を考えて、電車駅から徒歩20分以内のマンションにこだわっている。
目的
今回の目的はpythonを使い、23区の中で一番お買い得感がある物件が見つかることである。
今回はお買い得感の言葉の意味合いをsuumoさんが売り出し価格として提示している価格から数値で表せる情報のみで予測を行い、その予測価格と売り出し価格に差分があるほどお買い得か感があると表現する。
今回の分析においてはそのほか売上価格に関わってくるであろう情報は一旦無視するものとする。
方法
今回お買い得を求める方法は回帰モデル(重回帰分析とランダムフォレスト回帰)で予測価格を導き出し、それを実際の売出価格と比較する。「売出価格÷予測価格」で計算し、低い方がお得と推測している。
また、予測価格にかかわる重要な客観条件の物件の立地(区や駅)や築年数、広さ(専有面積)などを説明変数としてピックアップした。
作業環境
Google Colaboratory
Windows
作業手順
1、準備段階
2、データ収集
3、前処理
4、データ可視化
5、予測モデル構築
6、予測
参考資料
SUUMO の中古物件情報を Tableau で分析してみる ~データ収集編~
SUUMO の中古物件情報を Tableau で分析してみる ~データ分析編~
SUUMO の中古物件情報を Tableau で分析してみる ~データ予測編~
【Python】東京23区の中古マンション販売価格予測をやってみた
1.準備:パッケージインポートなど
1.1 Google Driveへのマウント、パッケージのインポート
まず、Google ColaboratoryからGoogle Driveへファイル書き出し、読み込みをするための準備や、今回使うパッケージのインポートを行う。
#ドライブ設定
PATH_GMOUNT='/content/gdrive'
PATH_MYDRIVE=PATH_GMOUNT+'/My Drive'
#GDriveマウント #以下を実行するとGoogleDriveへのマンウント許可を求められるので 、許可する
from google.colab import drive
drive.mount(PATH_GMOUNT)
#Google colab上でグラフで日本語表示するためにインストール
!pip install japanize-matplotlib
#必要なライブラリのインポート
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import requests
import re
import time
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
import lightgbm as lgb
from sklearn.model_selection import train_test_split1.2 データ加工用の関数群
スクレイピングしてきたデータを加工するための関数群を定義しておく。
#データ加工用の関数群
def identify_floor_plan(floor_plan):
# ワンルームを1Kに変換する
if floor_plan.find("ワンルーム") > -1:
floor_plan = "1K"
# floor_planに格納されている文字列の中にプラス記号("+")が含まれている場合、そのプラス記号以降を取り除く
if floor_plan.find("+") > -1:
floor_plan = floor_plan[:floor_plan.find("+")]
# LKをLDKに変換する
if floor_plan.find("LK") > -1:
floor_plan = floor_plan[0:1] + "LDK"
# floor_planに含まれる文字列が "LL" もしくは "DD" もしくは "KK" のいずれかを含んでいる場合に、"LDK" に置き換える
if floor_plan.find("LL") > -1 or \
floor_plan.find("DD") > -1 or \
floor_plan.find("KK") > -1:
floor_plan = floor_plan[0:1] + "LDK"
return floor_plan
def convert_price(price):
# 一億円以上の処理
if price.find("億") > -1:
# 何億円ジャストの物件の処理
if price.find("万") == -1:
price = int(price[:price.find("億")]) * 10000
# 何億円何万円の物件の処理
else:
oku = int(price[:price.find("億")]) * 10000
price = oku + int(price[price.find("億") + 1:-2])
# 一億円未満の処理
else:
price = int(price[:price.find("万")])
return price
def remove_brackets(data):
# m2以降を除去
if data.find("m2") > -1:
data = data[:data.find("m")]
# ()を除去、「69.98m2(登記)」(登記)のような表記
if data.find("(") > -1:
data = data[:data.find("(")]
return data
def get_line_station(line_station):
# JRをJRに変換
if line_station.find("JR") > -1:
line_station = line_station.replace("JR", "JR")
# 徒歩の時間を取得
walk_time = line_station[line_station.find("徒歩") + 2 : line_station.rfind("分")]
# 沿線と駅を取得
line = line_station[ : line_station.find("「") ]
station = line_station[line_station.find("「") + 1 : line_station.find("」")]
return line, station, walk_time2.データ収集: 東京都23区駅から徒歩20分以内中古マンション最上階物件売出情報をスクレイピング
もともとathomeさんの情報を利用したいと思ったが、利用規約の関係で、SUUMOさんから東京都23区駅から徒歩20分以内中古マンション最上階物件売出情報をスクレイピングしてみる。
2.1 ページを取得
# 東京都23区駅から徒歩20分以内中古マンション最上階売出物件のurl
url = "https://suumo.jp/jj/bukken/ichiran/JJ012FC001/?jj012fi20202Kbn=4&initKbn=1&displayClass=dn&disabledClass=false&ar=030&bs=011&ta=13&scTemp=13101&scTemp=13102&scTemp=13103&scTemp=13104&scTemp=13105&scTemp=13113&scTemp=13106&scTemp=13107&scTemp=13108&scTemp=13118&scTemp=13121&scTemp=13122&scTemp=13123&scTemp=13109&scTemp=13110&scTemp=13111&scTemp=13112&scTemp=13114&scTemp=13115&scTemp=13120&scTemp=13116&scTemp=13117&scTemp=13119&ekTjCd=&ekTjNm=&tj=0&kr=A&jc=046&cnb=0&cn=9999999&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&sc=13106&sc=13107&sc=13108&sc=13118&sc=13121&sc=13122&sc=13123&sc=13109&sc=13110&sc=13111&sc=13112&sc=13114&sc=13115&sc=13120&sc=13116&sc=13117&sc=13119&kb=1&kt=9999999&mb=0&mt=9999999&et=20&et=20&fw2="
r = requests.get(url)
soup = BeautifulSoup(r.text)
hit_count = soup.find("div", class_="pagination_set-hit").text
r.close()
#ページ数を取得
body = soup.find("body")
pages = body.find_all("div",{'class':'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
pages_split0 = pages_split[0]
pages_split1 = pages_split0[-3:]
pages_split2 = pages_split1.replace('>','')
pages_split3 = int(pages_split2) #これがページ数
#URLを入れるリスト
urls = []
#1ページ目を格納
urls.append(url)
#2ページ目から最後のページまでを格納
for i in range(pages_split3-1):
pg = str(i+2)
url_page = url + '&pn=' + pg
urls.append(url_page)2.2 売出情報をスクレイピング
SUUMOさんのサイトでは以下のような中古マンション販売情報が閲覧できる。

ここから物件名、販売価格、所在地、沿線・駅、専有面積、間取り、バルコニー、築年数の情報を取得した。
#SUUMOのHPからスクレイピング
cols = ["price", "name", "address", "ward", "line_station", "line", "station","walk_time", "area", "balcony", "floor_plan", "age"]
df = pd.DataFrame(index=[], columns=cols)
data = {}
for url in urls:
r = requests.get(url)
soup = BeautifulSoup(r.text)
r.close()
summary = soup.find_all('div', 'property_unit-content')
for s in summary:
#print (s.find_all('dl'))
s_2 = s.find_all('dl')
#物件名
data['name'] = s_2[0].find('dd').text
#販売価格
data['price'] = s_2[1].find('span').text
#所在地 :住所と区を取り出す
address = s_2[2].find('dd').text
data['address'] = address
data['ward'] = address.replace('東京都','').split('区')[0] + '区'
#沿線・駅 :沿線、駅名、徒歩時間を取り出す
data["line_station"] = s_2[3].find('dd').text
#専有面積
data['area'] = s_2[4].find('dd').text
#間取り
data['floor_plan'] = identify_floor_plan(s_2[5].find('dd').text)
#バルコニー :
data['balcony'] = s_2[6].find('dd').text
#築年数
data['age'] = s_2[7].find('dd').text
header = s.find('h2').text
if len(data) >=1:
df = df.append(data, ignore_index=True)
data = {}
#スクレイピング時のマナーとして 、プログラムを停止する
time.sleep(5)3.前処理:販売価格予測モデルのための学習データの前処理
3.1 データの前処理
ここから、データの前処理を行う。
#データの前処理
#indexを振り直す
df = df.reset_index(drop=True)
#販売価格 :「億」や「万円」をリプレイスして、int型に
for i,price in enumerate(df['price']):
df.loc[i,'price'] = convert_price(price)
#沿線・駅 :沿線、駅名、徒歩時間を取り出す
for i,line_station in enumerate(df['line_station']):
line, station, walk_time = get_line_station(line_station)
df.loc[i, "line"] = line
df.loc[i, "station"]= station
df.loc[i, "walk_time"] = walk_time
#専有面積
for i,area in enumerate(df['area']):
df.loc[i, 'area'] = float(area[:area.find("m")]) #「m」より前を削除して、float型に
#バルコニー
for i,balcony in enumerate(df['balcony']):
if re.search(r'\d+',balcony):
if balcony.find('㎡') > -1:
df.loc[i, 'balcony'] = float(balcony[:balcony.find("㎡")]) #「㎡」より前を削除して、float型に
else:
df.loc[i, 'balcony'] = float(balcony[:balcony.find("m")]) #「m」より前を削除して、float型に
else:
df.loc[i, 'balcony'] = float(0) #数字以外 (「-」など)が入っているときには、ゼロ(float型)にした
#築年数
for i,age in enumerate(df['age']):
df.loc[i, 'age'] = 2023 - int(age[:age.find("年")]) #年だけを取り出し 、築年数を計算
#数値型へ変換
df = df.astype({'price': 'int32', 'area': 'float32', 'balcony': 'float32', 'age':'int8'})ここまでで取得したデータを確認してみる。
display(df.head())
display(df.describe())
display(df.describe(exclude='number'))
データ件数は1,769件で、売出価格の最大値は9.9億円で、最小値は750万円である。
3.2 重複データの削除
異なる不動産屋さんが同じ物件情報を入力するなど重複情報を削除してみたが、重複情報がない模様。
#重複行の削除 ※0件以上が削除された
df = df.drop_duplicates(ignore_index=True)3.3 駅名の取得
SUUMOさんから取得したデータの駅名(348駅)を抽出した。
station_df = pd.DataFrame(df['station'].unique(),columns=['station_name']) display(station_df)4.データ可視化
4.1 販売価格の分布
plt.figure(figsize=(15,5))
plt.title('販売価格のヒストグラム')
sns.distplot(df['price'])
5000万円~1億円の物件が最も多い模様。
4.2 専有面積の分布
plt.figure(figsize=(15,5))
plt.title('専有面積のヒストグラム')
sns.distplot(df['area'])
ほとんどの物件の面積は30平米~110平米の模様。
4.3 築年数の分布
plt.figure(figsize=(15,5))
plt.title('築年数のヒストグラム')
sns.distplot(df['age'])
築40年~45年の物件が一番多い模様。
4.4 区別の物件販売数
#日本語表示
japanize_matplotlib.japanize()
#区別の物件数を確認
plt.figure(figsize=(15,5))
plt.title('区別物件販売数')
sns.countplot(y='ward', data=df, order = df['ward'].value_counts().index) 
物件数はTOP3が世田谷区、大田区、新宿区の順になっている一方、荒川区の物件数が最も少ない。
4.5 区別の販売価格
order_index = df.groupby('ward').median()['price'].sort_values(ascending=False).index
plt.figure(figsize=(8,8))
plt.title('区別販売価格の箱ひげ図')
sns.boxplot(x="price", y="ward", data=df, order = order_index)
港区の物件の販売価格が圧倒的に高い模様。渋谷区と目黒区も相当高い。千代田区も非常に高いはずだが、売出物件数が少ない。
4.6 築年数別の販売平均価格
plot = df.groupby('age', as_index=False).mean()
plt.figure(figsize=(15,5))
sns.barplot(x='age', y='price', data=plot)
新築マンションの価格は間違いなく非常に高いが、築年数が上がるとともに、販売平均価格も下がる傾向にある模様。
4.7 専有面積・築年数・販売価格
sns.relplot(data=df, x="area", y="price", size="age", hue="age")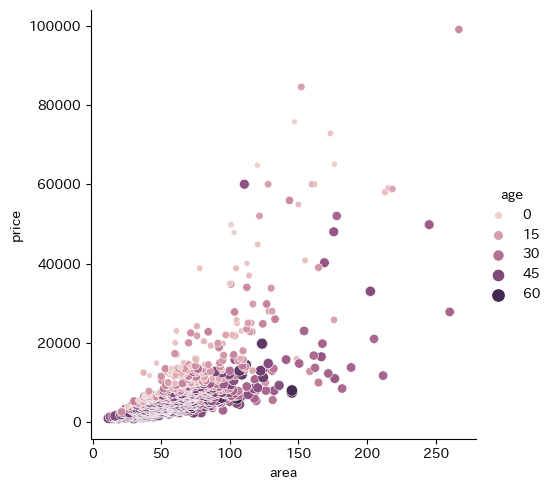
専有面積と販売価格の関係が大体正比例と言える。
5.予測構築:中古マンションの販売価格予測モデルの構築
今回は重回帰分析、ランダムフォレスト回帰でモデルを構築してみた。
5.1 学習データの準備
まず、学習に使うデータを準備しておく。
今回は最寄駅までの徒歩時間、専有面積、バルコニー面積、築年数として、販売価格を予測し、行政区と路線はダミー変数化して使う。
#学習データの準備 #display (df.head())
X = df[["walk_time","area", "balcony", "age", "ward", "line"]]
y = df['price']
# 区と路線をダミー変数化(One-Hot_Encodingで変換)
X = pd.get_dummies(X, columns= ["ward", "line"])
#訓練データ検証データに分ける (9:1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.1, random_state=0)
5.2 重回帰分析
model = LinearRegression()
model.fit(train_X, train_y)
#訓練データと検証データでの決定係数を確認
print('LinearRegression train score : {}'.format(model.score(train_X, train_y)))
print('LinearRegression test score : {}'.format(model.score(test_X, test_y)))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
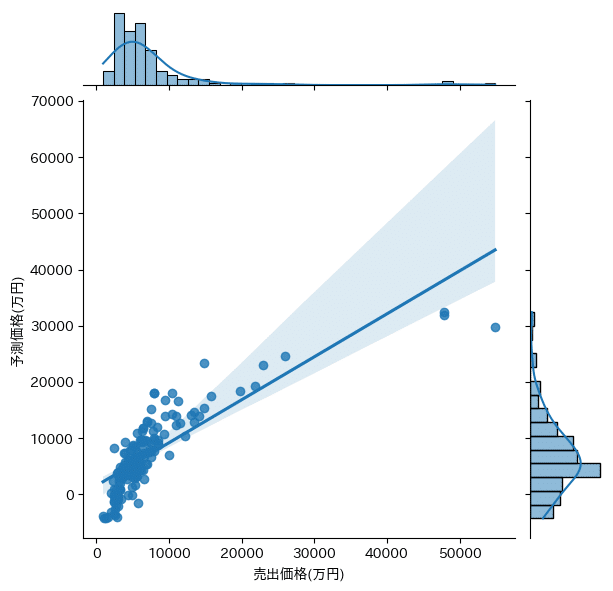
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.xlabel("売出価格(万円)")
plt.ylabel("予測価格(万円)")
plt.show()
出力結果は以下の通り。縦軸が予測値、横軸が実際の売出価格のプロット図。
LinearRegression train score : 0.6857852137735271
LinearRegression test score : 0.7068744631550494
5.3 ランダムフォレスト回帰
# モデル作成
rfr = RandomForestRegressor(random_state=0)
model = rfr.fit(train_X, train_y)
#訓練データと検証データでのスコアを確認
print('RandomForest train score : {}'.format(model.score(train_X, train_y)))
print('RandomForest test score : {}'.format(model.score(test_X, test_y)))
# 特徴量の重要度を確認
fti = rfr.feature_importances_
print('Feature Importances:')
for i, feat in enumerate(train_X.columns):
if fti[i] >= 0.01:
print('\t{0:10s} : {1:>.6f}'.format(feat, fti[i]))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
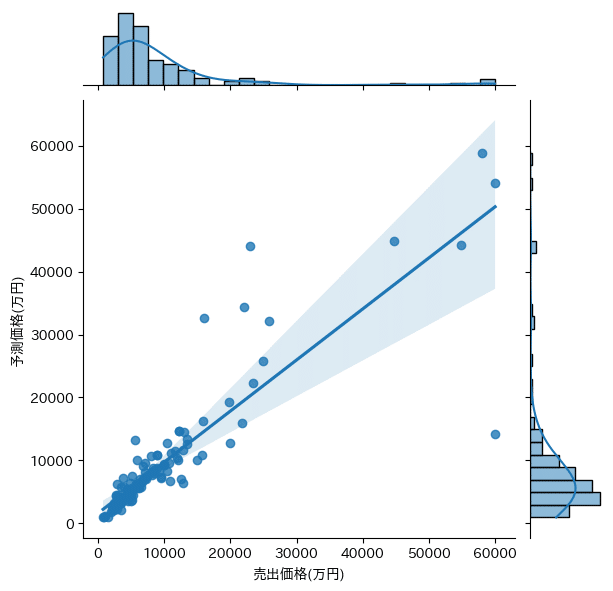
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.xlabel("売出価格(万円)")
plt.ylabel("予測価格(万円)")
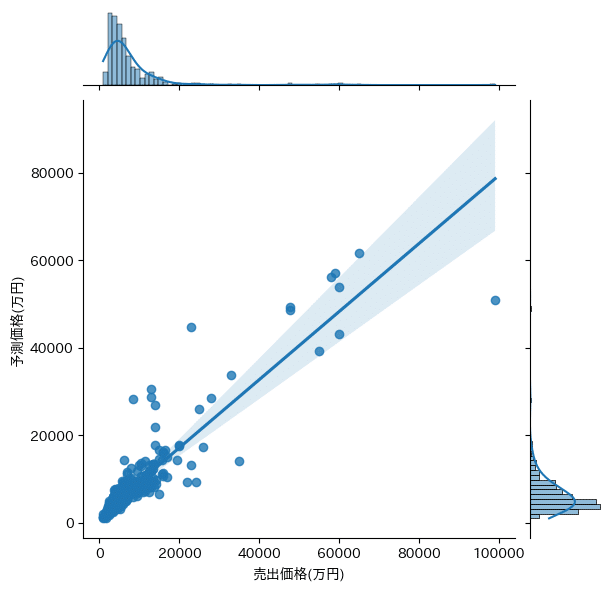
plt.show()出力結果は以下の通り。専有面積の重要度が圧倒的に高い。ついで築年数。また、駅からの徒歩時間や、バルコニー、渋谷区、港区の重要度も割と高い。
RandomForest train score : 0.9626617425060959
RandomForest test score : 0.8591603270367766
Feature Importances:
walk_time : 0.016518
area : 0.608831
balcony : 0.025528
age : 0.213756
ward_渋谷区 : 0.013472
ward_港区 : 0.046805
6.予測結果
6.1 ランダムフォレスト回帰による予測
#元データに予測値を結合
pred_y = pd.DataFrame(model.predict(X) ,columns=['pred'])
df_price_pred = pd.concat([df, pred_y], axis=1)
#お買い得度を 「売出価格÷予測価格」で計算。低い方がお得
df_price_pred['price_value'] = df_price_pred['price'] / df_price_pred['pred']
df_price_pred = df_price_pred.sort_values(['price_value'])
display(df_price_pred[['name', 'price', 'pred', 'price_value']].head())
重回帰分析よりランダムフォレスト回帰の方の誤差が少ないので、ランダムフォレスト回帰により予測してみた。
下記は結果。
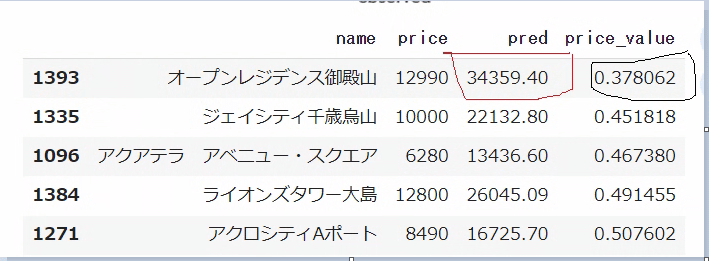
この表によると、御殿山の12990万円の物件が明らかに一番お得感がある。
その理由は、suumo内では34359.40万円の値が予測されている一方、実際の売出価格が12990万円である。予測価格と売り出し価格に差分がなんと二億円以上があるので、一番お得感がある物件である。
以下は上記の5物件の資料で、駅からの徒歩時間と築年数を考えると、御殿山の12,990万円の物件と大島の12,800万円の物件の価値が一番高いようで、特に御殿山のお買い得度(0.378062)が最も高いので、今回はこの御殿山の物件に注目したいと考えている。




6.2 訓練と検証割合7:3も試し(ランダムフォレスト回帰による予測)
予測結果を工夫するため、訓練データと検証データの割合を7:3に変更しもう一回ランダムフォレスト回帰による予測をした。
#学習データの準備 #display (df.head())
X = df[["walk_time","area", "balcony", "age", "ward", "line"]]
y = df['price']
# 区と路線をダミー変数化(One-Hot_Encodingで変換)
X = pd.get_dummies(X, columns= ["ward", "line"])
#訓練データ検証データに分ける (7:3)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=0)
# モデル作成
rfr = RandomForestRegressor(random_state=0)
model = rfr.fit(train_X, train_y)
#訓練データと検証データでのスコアを確認
print('RandomForest train score : {}'.format(model.score(train_X, train_y)))
print('RandomForest test score : {}'.format(model.score(test_X, test_y)))
# 特徴量の重要度を確認
fti = rfr.feature_importances_
print('Feature Importances:')
for i, feat in enumerate(train_X.columns):
if fti[i] >= 0.01:
print('\t{0:10s} : {1:>.6f}'.format(feat, fti[i]))
# 予測値と実際の値を可視化して確認
pred_y = model.predict(test_X)
plot_data = pd.DataFrame()
plot_data['observed'] = test_y[:]
plot_data['predict'] = pred_y[:]
plt.figure(figsize=(10,10))
sns.jointplot(x='observed', y='predict', data=plot_data, kind='reg')
plt.xlabel("売出価格(万円)")
plt.ylabel("予測価格(万円)")
plt.show()結果は以下。
RandomForest train score : 0.954277374376507
RandomForest test score : 0.641550445002697
Feature Importances:
walk_time : 0.023558
area : 0.608724
balcony : 0.024086
age : 0.202963
ward_渋谷区 : 0.015793
ward_港区 : 0.052554
残念ながら、7:3より9:1の方の精度がに高い模様で、今回は最初の7:3の予測を無視する。
結論
今回はpythonを使用して、東京都23区中古マンション最上階物件の中で一番お買い得感がある物件を探してみた。
結論というと、御殿山の12990万円の物件が一番お得感がある。
なぜかというと、本来suumo内では34359.40万円の値がつけられるはずが、実際は12990万円で販売されているため、予測価格と売り出し価格に差分がなんと二億円以上があるので、一番お得感がある物件である。
ただし、今回説明変数に使用しなかった条件(数値で表せない何らかの痂疲がある等)の影響を受けている可能性があるため、購入する際は注意する必要がある、といったことは言えるかと思う。
この記事が気に入ったらサポートをしてみませんか?