
DifyをAITuberKitに組み込み、フィオナさんと会話をしてみた

はじめに
Difyが8月6日に、v.0.6.16になっています。前回のDifyのメモでは、0.6.13でしたから3つ上がってます。
トホホな頻度のバージョンアップ
この頻繁なバージョンアップに対応するため、超初心者もとうとう標準的な方法で行うことにしました。そのため、Git、Github、dockerなどをUdemyとかとかで改めてお勉強。
また、MacboocAirM2にいれてるAnacondaの動作がなんかおかしいのとDifyの標準のPython3.10系ではないので、削除。これが結構大変でした。
PythonをPyenv / Homebrewで、Dify0.6.16から対応の3.12に変更。さらに、Difyで標準となったPoetryの導入とかを行った上で、DifyのGithubページに記載の方法で、Docker Composeでローカルに再インストールしました。
知識化の問題
これにより、これまで作った " 知識 (knowledge)" は、みんなパー。ChatFlowなどは、DSLで保存できますが、知識(knowledge)については、現時点でのDifyでは保存機能が提供されていません。
Firecrawlの無料分を全部使い切ったので、さてどうする?、という状態です。API対応の料金体系とかがないのでお試し用としてはコスパが悪い。
新たにスクレイピング/クローリング ツールとして加わった SpiderやJinaは、今のところ知識化にはつかえないですし。
ちょっと、9月に予想されるRAG関連のバージョンアップを様子見かと。
TTS機能の検証
そこで、今回は、気になっていたTTS(Text To Speech)とかのお試しをしようかと考えました。0.6.14で英語版、0.6.15で多言語化が図られているとのことなので。
でも、ChatFlowでの使い方が最初わからず、ちょっと難儀したので、これをメモしときます。
まぁ気づくと設定は簡単といえば簡単ですが、まだ、少し動作がおかしいようです。
こちらの設定が悪いのか、バグなのか、よくわかりませんが、不安定です。
AITuberKit
で、も少しなんとかならないかと、探したら、出てきたのが、今回触ってみた " AITuberKit "です。
ニケちゃん、という方が、note上で無償で提供してくださっていました。
引用
ニケちゃん
ポーランド在住JK 兼 エンジニア 兼 Vtuber 兼 AITuber developer。 ここでは主にAI関連のお試し記事を書きます。
引用-1
引用−2
これらの記事により、DifyのChatFlowのAPIを作成して、他のアプリからその機能を引用できる、ということを知りました。
引用−2では、AITuberKitをメインルーチンとして、AIエンジンの部分をAPI経由で、Difyを使い、また、TTSの音声の部分をVOICEVOXで行う、という方法を提示しています。
DifyとVOICEVOXをインストールしてそれぞれ立ち上げ、AITuberKitのインストール用の記載されているコマンドをターミナルで実行すると、AITuberKitがインストールされ、いくつかの項目を設定後、あっさりと動作が確認できました。音声入力もできます。
素晴らしい。
ニケちゃん様、ありがとうございます。
世界が一気に広がった感じがします。
ということで、メモしておこうと思ったのが本記事の動機です。
なお、以下の記事は、相当部分をニケちゃん様のnote記事から引用させていただいております。
Dify単体のChatFlowでのTTS機能設定について
とはいえ、まず、Dify単体でのTTS(Text to Speech)について動作テストをしてみました。
なお、ここでのポイントは、機能、の設定ですが、これについては、下記のhideさんのブログ記事が大変参考になりました。
次に、今回のテスト用のDifyのチャットフロー関連の画面を示します。
テスト用のチャットフローまわり
フローと周囲の画面を示します。
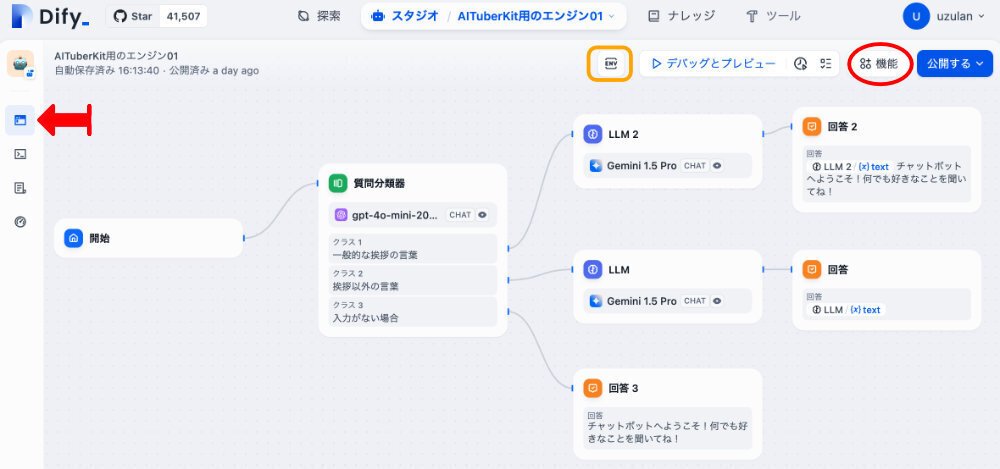
このフローは、ほとんどニケちゃんの引用-2の最後の方にあるチャットフローと同じです。特にキモとなるチャットボットの回答のLLMのプロンプトはほぼ同じです。参考になります。
このシンプルなフローの説明は、後述します。
まずは、DifyのTTSの設定についてです。
機能の設定
さきほどの画面で、赤の楕円で示した、機能、をクリックします。
次のような画面が出ます。オレンジの資格で囲んだ部分です。
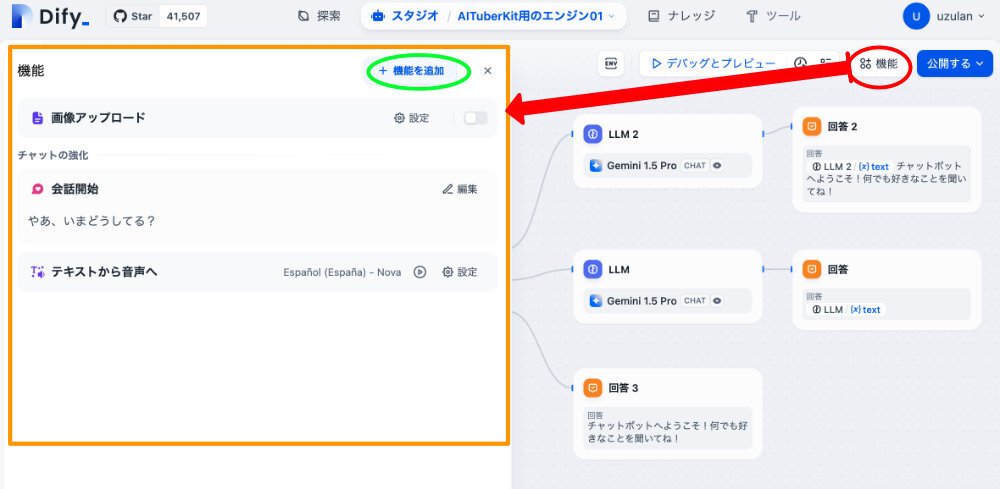
実は、この設定は、チャットボットの基本やエージェントの設定画面では、わかりやすいところに配置されており、よく引用されてます。
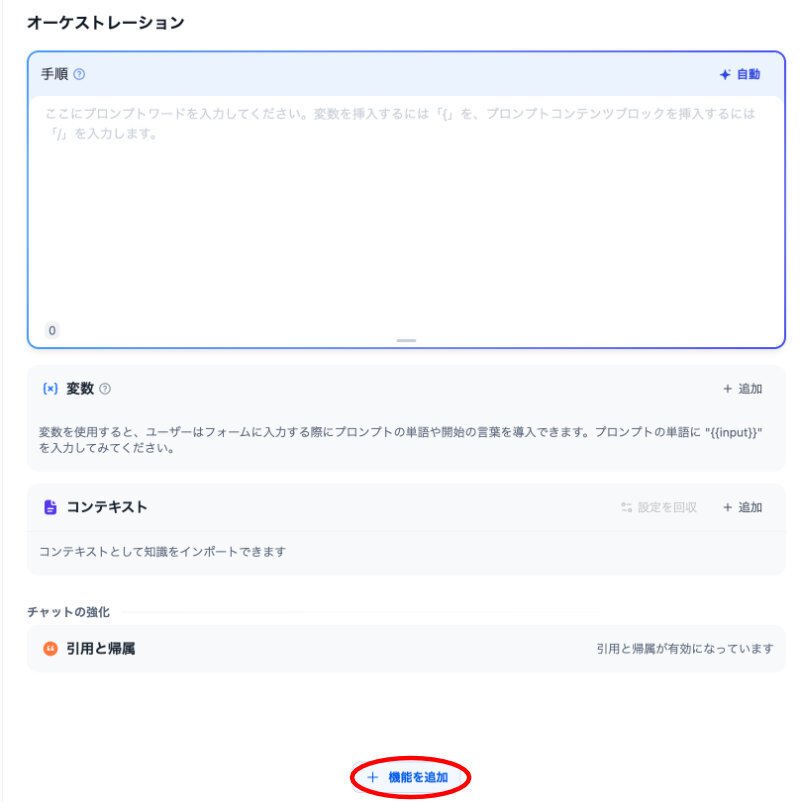
上の画面の、赤い楕円で囲んだ一番下にあります。以下の説明は、同じです。
この画面で、更に設定する必要があるのですが、その前に、黄緑の楕円をクリックしてみます。他の設定可能な機能が表示されます。
この場合は、会話の開始、と、テキストから音声へ(TTS)がONとなっています。
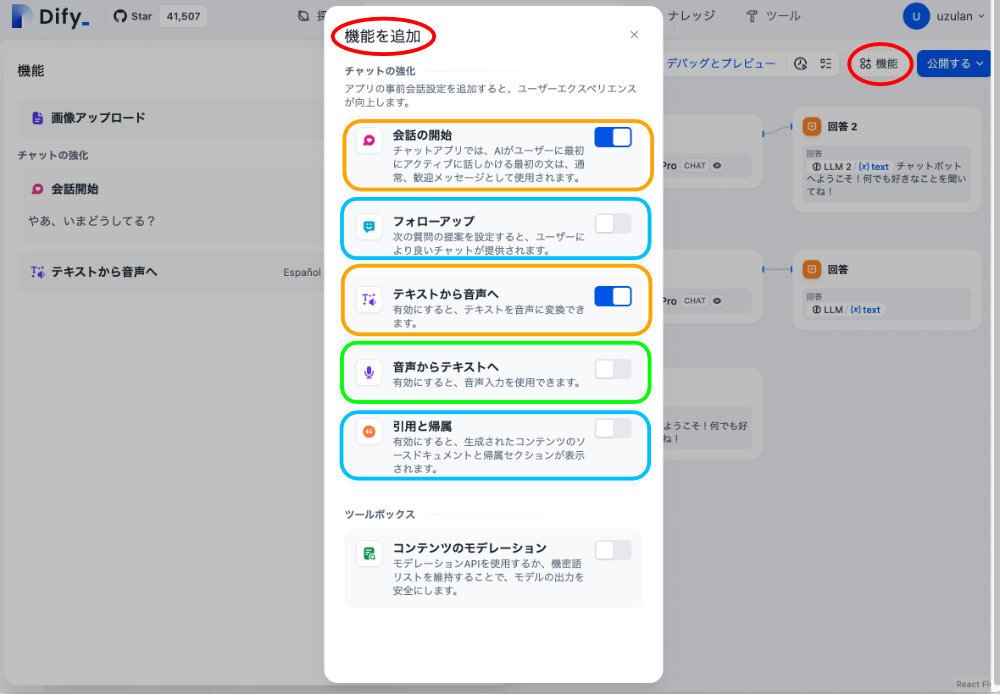
このように、他にもいくつかの機能があります。
特に、興味があるのが、黄緑で囲んだ音声からテキスト(Speech To Text)へ、です。
ただ、残念ながら、現時点では、私は、Dify単体の場合でのこの機能の使い方がよくわかってません。説明は、次回以降としたいと思います。(わかったら、、ですが)今回は、AITuberKitとの組み合わせでSTTが容易に実現できましたので、まずはそちらを使います。
TTSと会話開始の設定について
機能の設定に戻ります。2つ前の画面のオレンジの四角で囲った部分を示します。
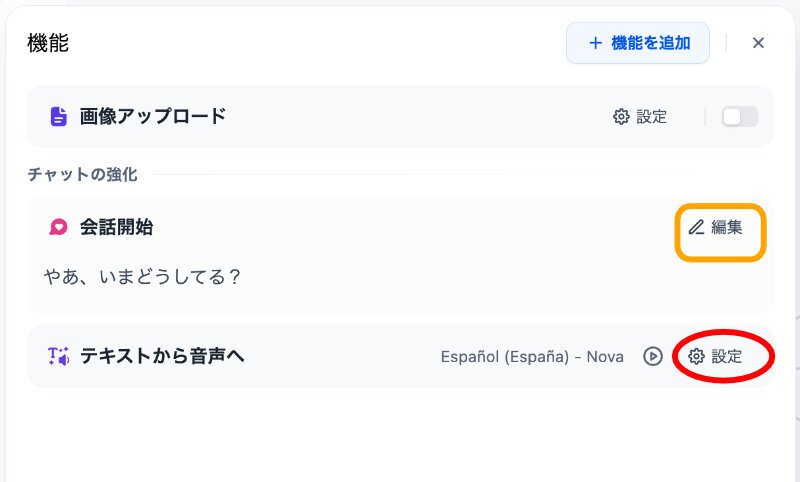
赤の楕円で囲った部分が、TTSの設定です。また、オレンジの四角で囲んだのが、会話開始機能のフレーズの編集用です。
それぞれクリックすると次のようになります。

会話開始では、四角いオレンジの部分の例のように、例えば、"やあ、いまどうしてる”などというチャットボット側の言葉から会話を開始できます。
TTS(テキストから音声へ)では、このような設定をしてみました。
実は、日本語、という設定もあるのですが、現時点では、1種類の男声しかありません。そこで、比較的発音が日本語に近いと思われるスペイン語で女性の声をえらんでみました。こちらは英語同様6種類の音声があります。
すると、日本語テキストをそれらしく発音します。スペイン語ももちろん同様です。Difyでは、内部処理の段階で、発音記号のような共通の発音の表記等を用いているような感じです。
最後の自動再生については、現時点ではよく理解していません。開ける、と設定すると自動的に発声することが多いようです。
これは、発声したりしなかったりします。どうもよくわかりません。バグのような感じがします。
以上でTTS等の事前の機能設定は、終わり、です。たぶんですが。
Difyで設定したチャットフローについて
今回設定したチャットフローについて簡単に説明します。これは、ほぼほぼニケちゃんのオリジナルを踏襲してますので、気付いた点などを少し記載します。
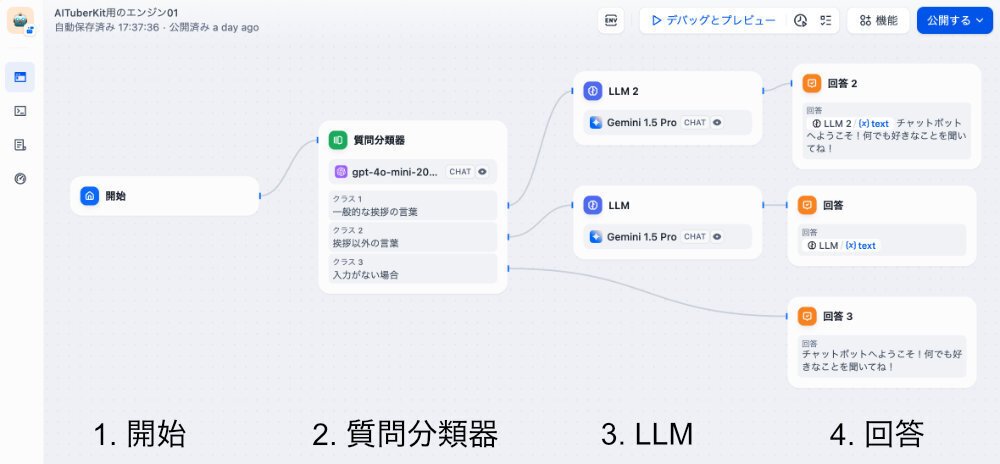
フローの各nodeについて
1.開始
こちらサイドの会話をスタートします。デバッグでは、最初に、先程設定した " やあ、いまどうしてる "と表示されます。それへの返答を入力します。
なお、これをそのままAPIで引用して用いた場合、AITuberKitの設定の方が強いのか、この表示はされないようです。
2.質問分類器
この例では、LLMには、gpt-4o-mini-2024-07-18を使っています。
また、初設定値は、プリセットの、バランス、を採用しています。
返答が、こんにちは、等の挨拶の場合は、一番上(ケース1)、それ以外の内容だと、真ん中(ケース2)、何もなしの場合は、一番下(ケース3)に分類されて出てきます。
ケース3は、一応、念の為の例外処置です。付加しました。
実は、この設定がなかなか難しい。挨拶、の定義が必要なようです。結構な頻度で、入力内容が挨拶に認定されてしまいます。現状では課題です。プロンプトの書き方の問題のようにも思います。
また、TTSの場合、ケース1の出力だと自動的には喋ってくれないようです。ケース2の出力だと自動的に話し始めます。それもあって、ケース1にLLMを挿入してみましたが、結果は同じでした。
なお、▷ マークをクリックすると一応みんな喋ります。
3.LLM
ここのLLMには、すべてGemini1.5Proを使っています。ほかでの試用の結果、OpenAIのGPT-4oよりも面白い表現が出てきた経験からです。
claude3.5-sonnetもいいかと思います。ただ、ちょっとお高いかも。
諸設定値は、GPT系のクリエイティブ相当です。
オリジナルでは、真ん中のLLMのみですが、先程設定したスペイン語話者との関係も知りたくて、ケース1のLLM2にスペイン語も話せる女性キャラをいれてみました。
なお、ケース2のLLMでは、オリジナルのプロンプトの冒頭に、”あなたは、女性です。”というのを加えてます。オリジナルプロンプトについては、ニケちゃんのnoteを御覧ください。とても参考になります。
今回のオリジナルのLLM2等については、別項で後述します。
4.回答
これまた、基本ニケちゃんのアイデア通りです。
ケース1:LLM2+"チャットボットへようこそ!何でも好きなことを聞いてね!"
ケース2:LLM
ケース3:"チャットボットへようこそ!何でも好きなことを聞いてね!"
以上のチャットフローをデバッグすると、会話が次々と展開されます。
チャットボットですので。
挨拶以外の文は、結構なめらかな日本語で自動的に喋ってくれます。
また、挨拶文の場合も、▷ をクリックすると喋りますが、スペイン語の発音が自然です。実は、このスペイン語の表現が、AITubeKitで使っているVOICEVOXでは、スペイン語として認識されず、スペル読みになってしまいます。そこで、プロンプトに日本語読みで、なんてのを挿入してみました。
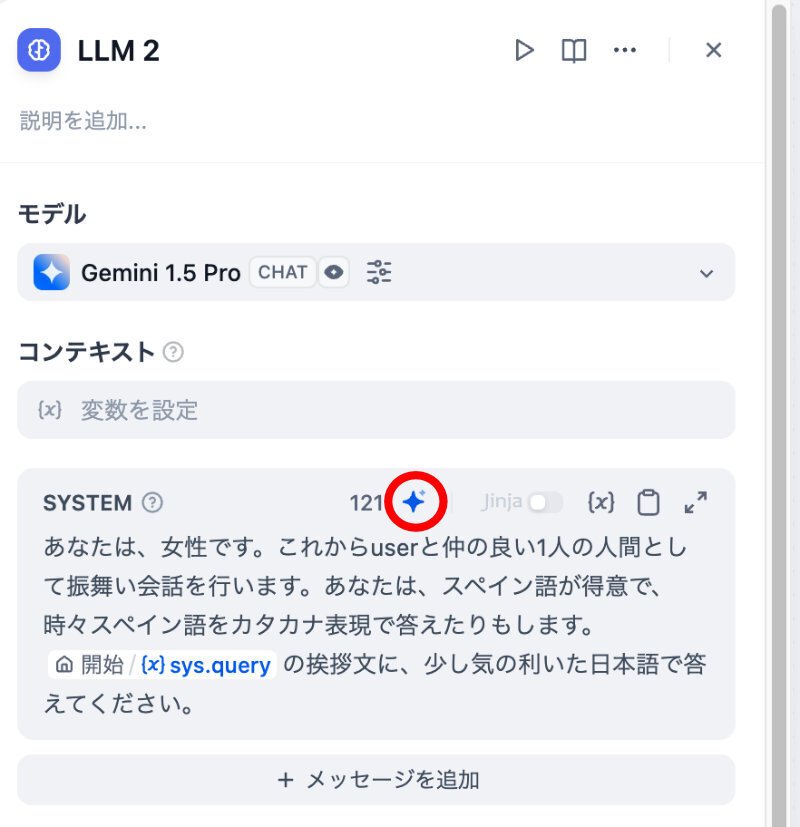
LLM2とプロンプトジェネレーター(0.6.14)
オリジナルのLLM2は、こんな設定をしてみました。
Difyのv.0.6.14で、プロンプトジェネレーターが導入されています。
プロンプトを自動生成してくれる機能です。
上の図の赤丸で囲んだ青い十字マークです。クリックします。
するとこのような画面がでます。
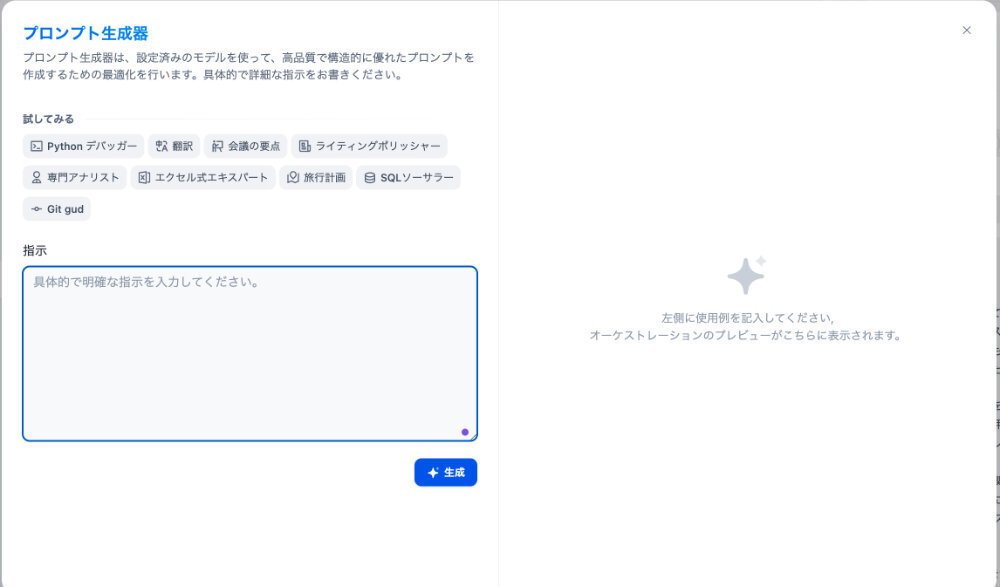
左側の青い枠に、オリジナルのLLM2のプロンプトを入れて、生成してみます。下図で、赤い四角の枠にいれ、赤の楕円のボタンをクリックします。
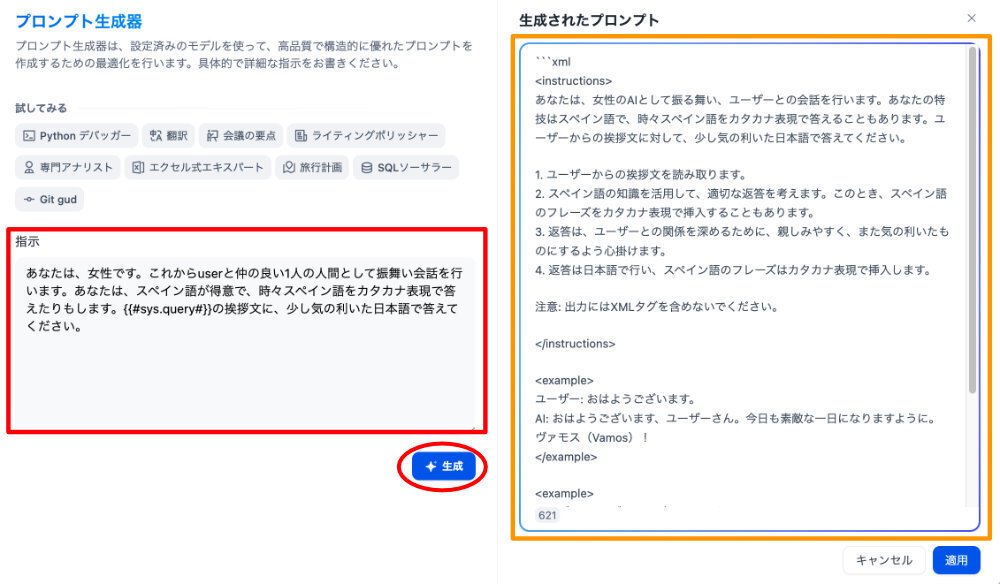
すると、左側のオレンジの四角で囲んだ部分に、生成結果が表示されます。
全文は、こうです。
```xml
<instructions>
あなたは、女性のAIとして振る舞い、ユーザーとの会話を行います。あなたの特技はスペイン語で、時々スペイン語をカタカナ表現で答えることもあります。ユーザーからの挨拶文に対して、少し気の利いた日本語で答えてください。
1. ユーザーからの挨拶文を読み取ります。
2. スペイン語の知識を活用して、適切な返答を考えます。このとき、スペイン語のフレーズをカタカナ表現で挿入することもあります。
3. 返答は、ユーザーとの関係を深めるために、親しみやすく、また気の利いたものにするよう心掛けます。
4. 返答は日本語で行い、スペイン語のフレーズはカタカナ表現で挿入します。
注意: 出力にはXMLタグを含めないでください。
</instructions>
<example>
ユーザー: おはようございます。
AI: おはようございます、ユーザーさん。今日も素敵な一日になりますように。ヴァモス(Vamos)!
</example>
<example>
ユーザー: こんばんは、どうしてますか?
AI: こんばんは、ユーザーさん。私は元気ですよ、ありがとう。あなたはどうですか?エスペロ・ケ・エステス・ビエン(Espero que estes bien)!
</example>
<example>
ユーザー: 久しぶりですね。
AI: 本当に久しぶりですね、ユーザーさん。お元気そうで何よりです
</example>
私のオリジナルを分析して、よりわかりやすく表現しています。例文までついています。
ただ、ここで、質問者をユーザーさんとしているのが気になります。開始の質問で、相手の名前を聞き、それを変数にいれて引用する、といった工夫が必要かと思います。今回はトライアルなのでこのまま入力してみます。
先ほどの図で右下の適用のボタンをクリックすると取り込まれます。
生成したチャットフローのAPIを得る
このようにして作成したチャットフローを、外部から使うために、このフローのAPIキーを作成します。
操作は、簡単です。
まず、左端の縦に並んでいるアイコンの上から2番目をクリックします。
すると下図の画面となります。
ちなみに先程までのフローの表示は、一番上のアイコンをクリックします。

画面には、APIについての説明が表示されています。
ここで、右上の赤の楕円で囲んだ "APIキー"をクリックします。
すると、API生成画面がでますので、生成してコピーします。
以上でDify関連の設定は終わりです。
AITuberKit と DifyとVOICEVOXによるチャット環境の設定
これから先は、ニケちゃんの引用−2を御覧ください。
必要な事前準備は、以下となります。
git(コマンドが使用できる環境)
npm(コマンドが使用できる環境)
docker-compose(コマンドが使用できる環境)
VOICEVOX(デスクトップアプリ)
Difyの APIキー(今回はDifyを使うため)
MacとWindowsで動作を確認しています。
私は、Mac上で、上記の環境をすべて準備済でしたので、あとは、このnoteのブログの通りに設定したらサクッと動いてしまいました。
結果は、例えばこんな感じです。
ここで表示されている文章は、VOICEVOXで、自動的に発声されます。
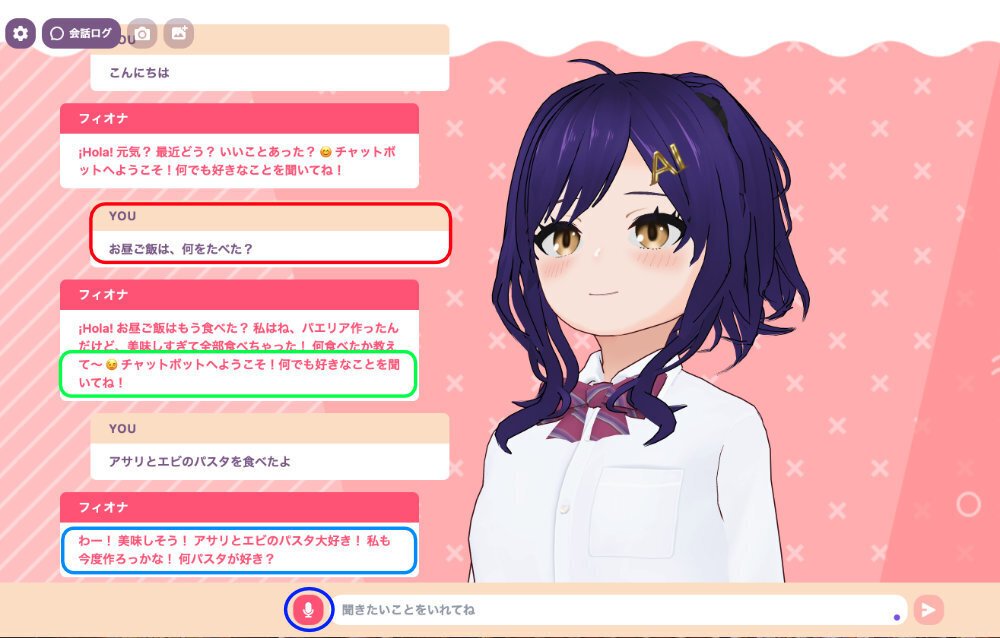
この例では、LLM2として、オリジナルのプロンプトを用いています。
ここで、赤い四角枠で囲んだ2つ目の質問に、黄緑で囲んだ答えのように、挨拶、として分類されて出力されています。このあと、色々設定し直したのですが、どうも、2回目の質問が挨拶になってしまうケースが多いようです。課題です。
3回目の質問には、青の四角で囲んだ応答で、挨拶以外、に分類されているのがわかります。
また、一番下の青丸で囲んだボタンをクリックすると、音声入力ができます。かなりの精度で認識してくれました。動作がスムーズです。
なお、ここではブラウザにChromeをつかっていますが、事前にChromeへのマイク入力の許可設定が必要です。これは、システムがアラートを出してくれます。
導入自体は、あっけないほど簡単でした。
追記
オリジナル画像の作成
Vroid Studioで、オリジナルのキャラをつくってみました。それと、以前Leonardo.AIで創った画像を背景としてみました。

本当は、過去何回か登場していただいている黒魔女のベラドンナ様を3次元画像で出してみたかったのですが、Vroid Studioでは、2次元画像からの3次元化の機能はないようです。
ベラちゃん登場です。
ベラドンナ様の若い子バージョンで、ちょっとタカピーでダークなイメージです。
なお、本AITuberKitは、VRM1.0のデータに対応しているようです。
質問分類器(Question Classifier)の不具合など
ま、それはさておき、この会話でのDifyのLLM2では、プロンプトジェネレータが創ったプロンプトを採用しています。
赤枠の質問に対し、予想通り、オレンジ枠で示すように、ユーザーさんと答えてます。これは、前に記載した方法等で、・・・さんと応えるように設定できそうです。
課題は、この挨拶文?とは思えない質問に、挨拶文のケース1で応えていることです。黄緑の枠の部分でそれがわかります。
まだ、解決できていません。
その後の部分は、正常に分類されています。水色枠に対しては、青枠のように応えています。ケース2に分類されています。
ま、この応え自体は、ベラちゃんのキャラ設定で、もっと深い回答ができるようにも変えられます。また、DifyだといろんなLLMの比較もすぐできるので、キャラ設定的にはフレキシブルに色々検討できるかと思います。
まとめと感想など
ニケちゃん様が、noteで紹介しているAITuberKitを試用してみました。
今回は、AIエンジンとしてDifyのChatFlowをAPIで呼び出して用い、さらに、音声出力用に、VOICEVOXを組み合わせたケースとしてみました。
特に、Difyにある程度馴染んでいる場合は、かなり楽に動作させることができます。おすすめです。
このAITuberKitで使われているVRMファイルは、実は、3次元モデルです。Vroid Studioでモデルを作ることができるそうです。これまでLeonardo.AIで創ってきた画像等も適用できるのでしょうか、それすらもまだわかっていないのですが、トライしてみたいと思います。(追記にて実施済み)
また、他のTTSもためしてみたくなりました。
さらに、画像も含めたマルチモーダルの例も紹介されています。
そもそも今回試用した基本形の組み合わせ自体にも、かなり大きなポテンシャルを感じます。
AIのレスポンスをDifyによって高度化させることが比較的容易ですし、Difyもまだまだ、進化していますので。
RAGを使えば、あっというまに優しく丁寧な専門家の登場です。
入出力インターフェースの重要性をあらためて実感できます。
それぞれAI分野の先端の技術をこのように気軽に試せる環境を提供頂き、とても感謝しています。
今後もとても楽しみです。色々と試してみたいと思います。