
DifyによるAIアプリの各node(Chat Flow)----黒魔女ベラドンナ様の人生相談02

はじめに
先日、Difyに関する記事をアップしました。
本記事は、それに続くもので、DifyのChatFlowを用いてAIアプリを創ったときに、疑問に感じたり、調べたことなどのメモです。
具体的には、それぞれのnodeについて、その設定した内容を示していきたいと思います。
nodeというのは、たとえば、下記のワークフローの中の四角のブロックのことです。ワークフローのキーコンポーネントと言えます。
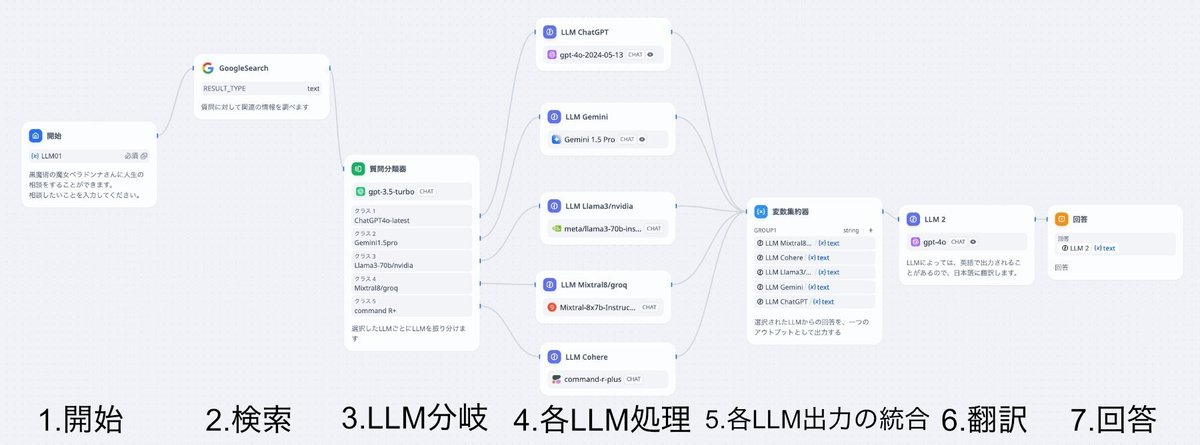
各nodeそれぞれの機能と設定についてメモって置きたいと思います。
Difyの基本ルール等
まず、事前説明として上記で用いたChatFlow関連のいくつかの事項について説明します。
Difyワークフローの2つのタイプ
ワークフローというのは一般用語ですが、Difyには、アプリケーションの用途に対応して、この手法を用いた2つのタイプがあります。
以下、引用します。
Chatflow : 顧客サービス、セマンティック検索、応答の構築に複数ステップのロジックを必要とするその他の会話型アプリケーションなどの会話型シナリオ向け。
Workflow: 自動化およびバッチ処理のシナリオ向けで、高品質の翻訳、データ分析、コンテンツ作成、電子メールの自動化などに適しています。
これらの用途の違いに応じて、Chat Flow には、回答(Answer)node
で、終わり、かつ、LLMなどのnodeにメモリーが自動的に設定されます。
それに対し、Work Flowでは、終了(End) nodeで、終わります。また、各nodeにメモリー機能は設定されていません。
2つの比較表を引用します。

nodesについて
以下、Difyから少し改変して引用します。ここでは、nodeを、大別してブロックとツールの2つに分けて説明します。
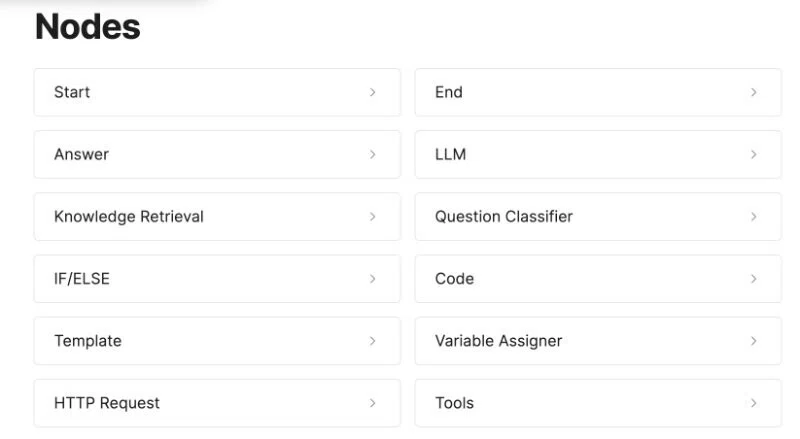
ノードはワークフローの主要コンポーネントです。異なる機能を持つノードを接続することで、ワークフロー内の一連の操作が実行されます。各ノードはタイプ別に下記のように分類されます。
現時点(2024/06/13)でヘルプ上で公開されているのは、12種類のブロックと、多数のツール群となります。ただ、ヘルプの記載が改訂に追いついていないようで、実際の状況とはやや異なります。
1.ブロック
基本ノード:開始、終了、回答、LLM、知識検索、アプリケーション(近日公開予定)
質問理解:質問分類、質問書き換え(近日公開)、サブ質問分割(近日公開)
ロジック処理:IF/ELSE、マージ(近日対応)、ループ(近日対応)
変換:コード、テンプレート、変数割り当て、関数抽出(近日公開予定)
その他:HTTPリクエスト
先に述べたように、ChatFlowは、回答nodeのみ、Workflowは、終了nodeのみとなります。
また、0.6.9では、下記の3つが追加もしくは改良されています。
Iteration:リストオブジェクトに対して複数のステップを実行し、すべての結果が出力されるまで繰り返します。
Parameter Extractor:LLMを使用して自然言語から構造化されたパラメータを抽出し、ワークフローでのツールの使用やHTTPリクエストを簡単にします。
Variable Aggregator:Variable Assignerが改良され、より柔軟な変数選択をサポート。さらに、ノードの接続方法が改善され、ユーザーエクスペリエンスが向上しました。
2.ツール
組み込みツール
カスタムツール
現在、41の組み込みツールが用意されています。
ただし、たとえば、Google Searchなどのように、APIを設定する必要があるものも含まれています
一覧表を引用します。
現在、Variable Assignerは、 Variable Aggregator に名称が変わっています。また、Iterationが追加されています。
変数について
ChatFlowを使うにあたって、大事なのが、変数です。
最初、この変数の使い方がよく分からず、悩みました。
どうやら、バージョンアップで、最近、表現の仕方が変わったようです。
参考にしたYouTube動画は、初期バージョンを用いており、古い表現が多かったというためもあったかと思います。
ChatFlowは、機能が定義されたnodeをつなげることによって、全体がチャットボットとしてのAIアプリを、プログラムレスで定義できるわけです。
そのためには、それぞれのnodeへの入力の受け渡しと処理結果の出力とを、node間でやり取りする必要があります。
それに変数を使います。この時、形式は2種類あります。
1.{{変数}}
2.node内で、" / " を入力すると表示される変数リストからの選択。
現在は、こちらの使い方が標準的かと思います。
選択すると、" node名/変数名 型 "、のように表示されます。
これについては、後述する実際のnodeの説明で、示します。
参考資料
今回の作成にあたって、特に参考になったYouTube動画をご紹介します。たとえば、下記の、いしださんの動画です。
各ブロックについて具体的に突っ込んで説明しています。また、実務派として、オペレーションが見事で、テンプレートの使い方など、開発時の時間ロスの低減に直結する方法などをさらっとレクチャーしてくれます。
ちょっと軽めの独特な口調ではありますが、経験に裏打ちされた直感的な理解力が素晴らしいと思います。内容はとても勉強になりました。
今回のAIアプリの説明
さて、やっと本論です。
今回のAIアプリの "黒魔女ベラドンナ様の人生相談" の構成に沿って、各設定を示していきたいと思います。
具体的には、1から7までの各nodeの説明となります。
1.開始(Start)
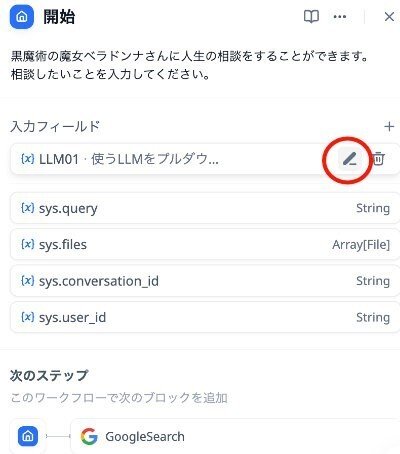
フローの中の開始nodeをマウスでクリックして選択すると、右側に下図のような詳細画面が拡大されて表示されます。
開始の太字の下の文章は、自分用の備忘録です。システム上は表示されません。これは、できれば、どこかに表示できたほうがいいように思います。
" 黒魔術の魔女ベラドンナさんに人生の相談をすることができます。
相談したいことを入力してください。"

ここで、青で囲んだ部分が、システムに事前にセットされている値です。ここで一番上の変数である" {x}sys.query "に、これがスタートしたときに、質問として入力された文言が入ります。
つまり、開始nodeは特に何もしなくても、質問入力画面が表示されるようになっています。
ただし今回は、複数のLLMから一つを選択するための情報入力を追加します。
それが赤で囲んだ部分です。これについては、別途設定が必要です。
赤枠の右側の必須とある部分にカーソルを移動すると、ペンのようなマークがでるので、クリックします。下図の赤丸の部分です。
すると、下図のような、この独自の変数の編集画面が表示されます。

番号に従って、説明します。
変数の入力方法です。ここでは、選択、を選んでいます。
つまり、入力の例を表示して、選んでもらうという方法です。変数名を入れます。ここでは、LLM01としました。
ラベル名です。これは、実際にRunさせた場合に表示されます。初期値として変数名が表示されますが、わかりやすく簡単な説明にしたほうがいいと思います。
オプション、これは、④の位置に+マークがあるので、これをクリックするとその上の表示入力となります。今回用意した5種類のLLM名を入れました。
必須、このスイッチをいれるとこの入力項目は必須となります。パスできません。
デバッグ画面
ChatFlowの気に入っている一つは、node単位でデバックができることです。
この開始nodeをデバッグしてみます。
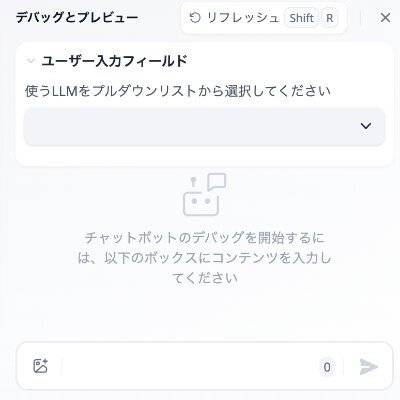
この画面が最初にでました。
実際にRunさせると、まず、上のみが表示され、入力すると、次に下の入力画面が表示されます。下に相談内容を入力します。
なお、プルダウンリストをクリックすると次のように、表示されます。
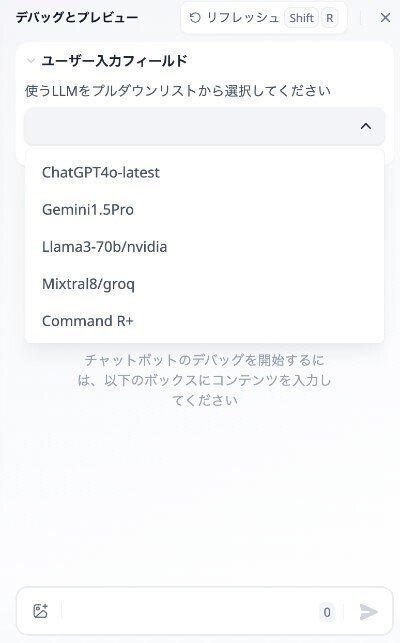
以上、開始の設定でした。
2.検索(GoogleSearch):ツール
2番目は、Google検索のツールnodeです。
Difyのツール一覧のGoogle Searchに次のような説明があります。
ツールの説明
A tool for performing a Google SERP search and extracting snippets and webpages.Input should be a search query.
Google SERP検索を実行し、スニペットとWebページを抽出するツール。入力は検索クエリであるべきです。
APIは、SerpAPIを入力するとつかえるようになります。
それはいいのですが、この検索クエリというのがよくわかっていません。
現時点では、質問、つまり文章をそのまま検索用クエリとして、入力していますが、Google検索の場合、それでは良い結果は出てこないように、思います。文章からキーワードを抽出して、それぞれを検索する、というプロセスが必要なのではないかと思います。今後の課題です。
現在の設定を以下に示します。フローのnodeをクリックすると右側に拡大されて表示されます。

順番に説明します。
1.入力変数
ここでは、上記のように、質問をそのままいれています。
2.Result Type
結果をtextか、Linkかで指定できるようです。textをえらんでいます。
3.出力変数
ここをクリックすると、2つの変数が出力されています。
textとfiles(配列)です。後では、textを使っています。
4.次のステップ
次は、質問分類器です。
3.質問分類器(Question Classifier)
本nodeと使い方の説明
Difyの日本語設定だと質問分類器、Google翻訳だと質問分類子と訳されます。想定されている普通の使い方は、入力された質問を事前に分類して、質問内容に対してより適切に対応できるようにする、ということのようです。
そのため、LLMを使って、ここで振り分けに設定する各クラスへのマッチ度を検討させます。ちなみに、その場合、想定したクラス分け以外の場合の対応を必ず準備する、ということが大事なようです。
YouTube動画では、皆さん必ず例外処理を準備しています。
それをしていないと、ここでフリーズしてしまう可能性があるからです。
今回の事例では、単純にCase文のような使い方をしています。
変数の入力には、選択を設定しているので、例外処理の設定は不要です。
つまり、入力変数として、同時に設定したLLM01を使い、それに入っているLLMの名前の情報に基づき、分類して、次にそれぞれのLLMに処理をさせています。従って、このnodeのLLMは、ほとんど仕事をしていません。
一種のロジック処理として使っているわけです。
これは、If else を複数使ってもできますが、5つの分類となると、ちょっとごちゃごちゃしてしまいます。
具体的な設定は次のようになります。ちょっと縦に長いので、3分割して表示します。
設定画面-1
下記の1、2、3について、以下説明します。

1.入力変数
開始nodeで独自に設定した変数のLLM01を使います。
下記の5つのLLMのどれかが入力されています。

2.モデル
特に理由はないのですが、gpt3.5-turboを使っています。
ここでの用途には、十分です。
設定画面-2(続き)

3.クラス
分類項目を設定します。ここでは、変数LLM01と同じ名称を入れています。
なお、ChatGPT4oは、現時点で、最新版が4o-2024-05-13です。いちいち書き換えるのも面倒なので、4o-latestという名称にしています。
設定画面-3(続き)

4.出力変数
このnodeの出力変数は、class_nameですが、今回は、この変数は後段
では、使っていません。
5.次のステップ
次のステップはそれぞれのクラスにアサインされた各LLMとなります。
続く・・・
またまた、長くなってしまいましたので、一旦ここで区切ります。
次は、各LLMの設定画面となります。
また、このAIアプリの質問の例と、その出力もご紹介したいと思います。
結構LLMによって個性があるようです。
この記事が気に入ったらサポートをしてみませんか?