
(10.22更新)軽量・低遅延AIボイスチェンジャー「Beatrice」モデル学習用ツールキット ワンクリック導入法(※非公式)

2024.1022更新
configの設定と追加学習について追記しました。
2024.10.21更新
バッチファイルからnum_workersの値を入力できるようにしました
2024.10.20 更新
暫定的ですが、Beta.2 に対応した内容に修正しました。
まだ不備があるかもしれないので追記修正します。
旧Verを導入している方は新規に導入し直してください。
■Beatriceって何?
↓コレです
超軽量・超低遅延なAIボイチェン「Beatrice」
https://prj-beatrice.com/
AIをつかったボイスチェンジャーです(そのままやん
詳しくは公式を読んでくださいまし。
【注意!】
私はBetrice開発者および関係者ではありません。
このnoteで紹介しているのは、あくまでもBeatrice公式の学習ツールキットを、簡単に導入する方法だけです。
また、ツールキットにバージョンアップや変更があった場合、本記事の方法ではうまく動作しなくなる可能性がありますのでご了承ください。
公式様、今更ですけど勝手にロゴ使ってごめんなさい><
■こんな人向けの記事です
Beatrice用のオリジナルモデルを作りたい
colabではなくどうしてもローカルでやりたい
RVCなどのAI音声学習について最低限の知識がある
自分で学習用音声データを用意することが出来る
出来れば余計なものをインストールしてPCを汚したくない
公式の導入方法で躓いた
はい。全て私のことです。
もしかすると同じような人もいるかもしれないのでnoteに残すことにしました。
■公式のBeatrice Trainer導入方法
https://huggingface.co/fierce-cats/beatrice-trainer
Beatrice公式のリンクからも飛べる導入解説ページです。
わからない部分があっても全て目を通しておいてください。
また、私の導入の仕方および学習までの流れは、あくまでも私が独自に簡易版としてまとめたものなので、正式な方法ではない、ということをご理解ください。
■本記事で紹介する導入方法の特徴
1.PythonとGitのセットアップは不要
PythonやGitなどの開発環境は一切準備しなくてOK。
自動で環境構築します。また、両方ともZip形式でダウンロードして解凍するだけなので、システムドライブに直接インストールしません。
だから自前の開発環境がある場合も競合しません。たぶん。
あ、人によってはMicrosoft Visual Studioのインストールは必要かも。
2.システムドライブが汚れず余計なゴミも残らない
通常、PythonやGitを普通にインストールして開発環境を構築・運用しようとすると、システムドライブの非常にわかりづらい場所にギガ単位のキャッシュや不可視ファイルなどがに大量に分散して保存されてしまいます。
本記事の方法であれば全てのファイルを1フォルダにまとめることができ、管理や削除も容易になります。たぶん。
■学習に使うマシンの推奨スペック
AI関連の学習は基本的にそれなりに高いスペックのマシンを要求されますがBeatrice Trainerも例外ではありません。
公式による発表は特にありませんが、私が独断と偏見で出したおおよその推奨スペックは以下の通りです。
OS:Microsoft Windows10 or 11
(※私のバッチファイルで導入する場合はWindows必須です)
CPU:不明。ここ数年のヤツならたぶん大丈夫!?
メインメモリ:32GB以上が望ましい
(※設定次第では 16GB でもいけるかも!?)
グラフィックカード:NVIDIA製 RTXシリーズ以降 VRAM 12GB 以上
(※設定次第では VRAM 8GB でもいけるかも!?)
ストレージ:SSD推奨 空き容量20GB
NVIDIA製のグラボを搭載した最近のゲーミングPCならわりといけるかもしれない!?という感じですが、その場合ネックになるのはメモリですかね。
普通の人はメモリなんて16GBもあれば問題ないでしょうし。
ただ、これもconfig設定をいじることでなんとかなるかもしれません。
方法については後半で説明します。
■ワンクリ導入してみよう
1.セットアップ用バッチファイルのダウンロード(10.20更新)
上記の setup_XXXX.bat をダウンロード、適当なフォルダを作ってその中に設置してください。あ、もちろんそのフォルダ内に全てインストールされるので、無難にBeatriceTrainerという名前が良いかと。
eng となっているのは英語版です。ただし中身の英文が正しいかどうかは保証しませn
また、フォルダ名は全て英字にして、パスに日本語が入らないようにしてください。
例)D:\App\BeatriceTrainer\setup_XXXX.bat
2.セットアップ
所定の場所に置いたらダブルクリックして起動してみましょう。
たぶんこれが出ます。
ようは、怪しいバッチファイルは開くな!という警告です。
左上の詳細情報という文字をクリックし、[実行] をクリックすると、バッチファイルが起動して各種ダウンロードが始まります。
回線状況にもよりますが、セットアップ完了には早くても5~10分前後かかるかもしれません。のんびり待ちましょう。
↑のように、最後にヘルプが表示されたら無事完了です。たぶん。
バッチファイルの中身は、Python環境はPython公式からPython embeddable版(配布用の超軽量バージョン)をダウンロード、必要な機能を追加して最小構成の環境を構築。GitはGit公式のPortableGitをダウンロード、そのうえで、公式の流れにのっとり学習ツールキットを導入、というのを自動で行うようになっているだけです。
Beatrice公式では仮想環境の構築にPoetryの使用を推してましたが私はvenvを使用しました。理由は『個人的に慣れているから』というだけです。まぁ動いたので問題無しです。
(追記)
と、思っていたのですが、もしかして前回のVerでPytorchがCPU版で導入されてしまう問題ってコレのせいだったりして…
うーん、導入をPoetry版で作り直すかなぁ。
3.学習用音声ファイルを準備しよう
とにかく頑張って用意してください(投げ
ココ読むような人ならまっさきにRVCにも手を出してるでしょ?(偏見
その時に作ったヤツをそのまま使いましょう。
音声編集ソフトとかでちまちま切るのが面倒!って人は、音声スライサーソフトなどを使用してみてください。
RVCなど音声学習に慣れ親しんでる人は、Applioで学習させる際に事前準備でスライスしてくれたwavを使うのが一番簡単かもしれないです。
Applioの場合、データセット前処理作業でlogsフォルダ内に
sliced_audios
sliced_audios_16k
という二つのフォルダが作られるので、16kのほうをそのまま使用しても良さそうな感じですね。ただし、自動スライスなのであまりスライスの精度は良くないのでもしかすると学習に悪い影響が出るかも??
また、音声ファイルの量(合計の長さ)について特に言及がないですが、おそらく最低でも15分前後の長さはあったほうが良いかもしれません。RVCは限定的な再現であれば10分程度の長さでも充分成果が出ましたが。
4.トレーニング用バッチファイルのダウンロード(10.22更新)
train_XXXX.batをダウンロードして、setup_XXXX.batと同じ場所に置いて起動すると、簡易対話型のバッチファイルが起動します。
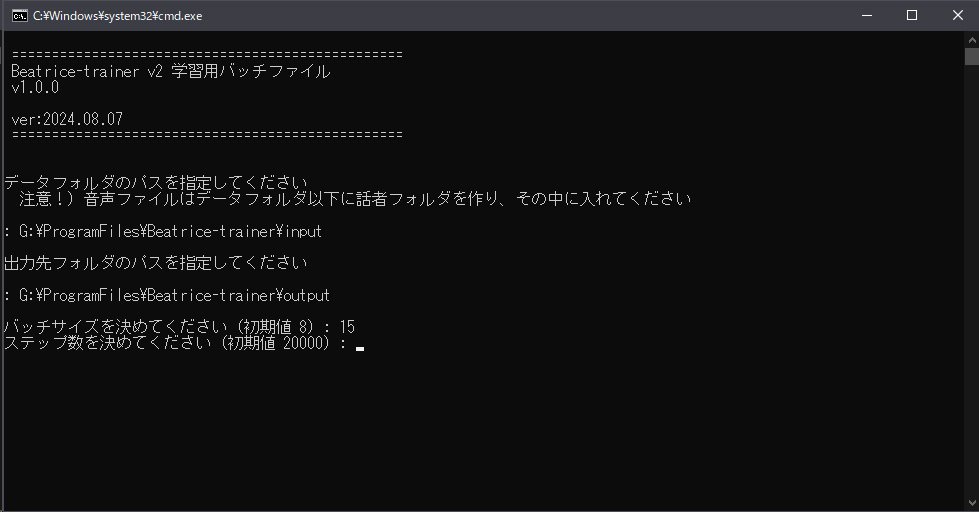
データフォルダのパス、出力先のパスなど色々聞いてくるので、コピペでぽんぽん貼ってエンター押していってください。あ、パスはフルパスでね。
5.config.jsonの設定について
学習時の様々な設定が記述してあるファイルがあるのですが、train.bat では質問形式で数値を入力し、自動でconfigを出力するようにしています。
configファイルには設定できる項目が沢山あるのですが、毎回全て入力するのも面倒ですし、必要そうなものだけ抜粋しました。
現在バッチファイル上から設定できる項目は以下の通りです。
"batch_size": 初期値は 8
バッチサイズです。1ステップごとに処理する学習容量の単位のようなものです。この値が大きいほど、1度に多くの学習データを処理することが出来ますが、比例してVramの使用量も増えていきます。
"num_workers": 初期値は 16
学習工程において、Vramにデータを送る時に使用するメインメモリの割合に関係している項目です。この値を大きくすることで学習データの転送速度が上がるのですが、その代わりメインメモリの使用量が増えていきます。
"n_steps": 初期値は 10000
学習の総ステップ数です。この値の回数分だけ学習工程を繰り返します。
基本的には多く設定するほど学習回数が増えて精度は上がっていくのですが、過剰に多くしてしまうと過学習となってしまって逆に精度が落ちていくこともあります。
"warmup_steps": 初期値は 2000
中間ファイルを何ステップごとに保存していくかという値です。この値が小さいほど沢山の中間ファイルが作られ、結果としてストレージを圧迫していきます。ただ、あまり大きい区切りにしてしまうと、追加学習時に大幅なロスが発生してしまうかもしれません。理由は後述で。
バッチサイズとステップ数の関係についてですが、
バッチサイズ xステップ数 ≒ 学習総量
という理解でざっくりおおよそだいたいあってます、たぶん。
ただ、これも学習させる話者の人数、音声データの総量によって適正値が大きく変動します。数人分をまとめて学習させる場合は、当然のことながらステップ数も大幅に増やす必要があります。
よくわからない人は1人分の音声データにつき10000~20000ステップぐらいの考えで良いのかなと思います、たぶん。
GPUのVramが少ない場合、バッチサイズを減らすことでVram使用量が減るので一応学習自体は可能になりますが
バッチサイズを減らす→学習総量が減る
ということにもなります。
仮にバッチサイズを『8』の半分の『4』に設定した場合は、ステップ数を2倍にするなどして調整してみてください。
(※だからといってバッチサイズ『8』の時と結果が同じになるとは限りません)
また、デフォルトのnum_workersの値のままだと、メインメモリの残り容量によっては、メモリ不足でエラーが起きる可能性が高いです。
その場合は、num_workers の値を『8』か『4』、いっそ『2』ぐらいまで減らしてみてください。
速度は落ちるかもしれないですが、占有メモリが減ることでエラーを回避できるかもしれません。
上記以外のconfig設定を個別に変更した時は、設定が終わってoutputフォルダにconfig.jsonが生成された後、トレーニングを開始する前にメモ帳などで開いて中身を記述してください。
それらが完了したら、最後の質問に『y』を押してエンターで学習開始です。正直、結構時間かかります。
以下は私の環境でのテスト結果です。
GPU:Geforce RTX3060 (VRAM12GB)
メインメモリ:96 GB
音声データ:全1人分 約20分 (約80MB)
batch_size:8
num_workers:16
n_steps:10000
VRAM占有率 9GB前後、かかった時間は 約2時間 でした。
ちなみにRTX4090だと30分程度で終わるとか…
無事学習が終了すると、指定したoutputフォルダ内に色々ファイルが出力されているはずです。
以下公式の説明から抜粋
paraphernalia_(data_dir_name)_(step)
ストリーム変換に必要なファイルを全て含むディレクトリです。
学習途中のものも出力される場合があり、必要なステップ数のもの以外は削除して問題ありません。
このディレクトリ以外の出力物はストリーム変換に使用されないため、不要であれば削除して問題ありません。
checkpoint_(data_dir_name)_(step)
学習を途中から再開するためのチェックポイントです。
checkpoint_latest.pt にリネームし、 -r オプションを付けて学習スクリプトを実行すると、そのステップ数から学習を再開できます。
checkpoint_latest.pt
最も新しい checkpoint_(data_dir_name)_(step) のコピーです。
config.json
学習に使用されたコンフィグです。
events.out.tfevents.*
TensorBoard で表示される情報を含むデータです。
6.完成したモデルを試してみよう
標準設定だとステップ数が10000stepなので
paraphernalia_入力フォルダ名_00010000
という名前のフォルダが最終出力モデルということになります。
このフォルダを まるごとzipで圧縮 しましょう。中身だけじゃなくてフォルダまるごとでOK。
これで学習モデルは完成です。さっそく試してみましょう。
RVCなどでもお馴染みのVC Clientを使わせて頂きます。
VC Client
https://github.com/w-okada/voice-changer/tree/v.2
VC Clientのモデル読み込み時にBeatriceを選択し、先ほど作ったzipファイルを読み込めばOKです。
詳しい使い方についてはVC Clientの公式を参考にしてください。
7.中断したトレーニングの再開
通常、指定ステップまで学習が終了すると、出力先フォルダ内に checkpoint_latest.pt が作成されているはずです。
無い場合(途中で強引に終了したなど)は、一番最新のcheckpointファイルを複製してcheckpoint_latest.ptにリネームしましょう。
そのうえで、train.batを起動し、前回と同じ入出力フォルダを指定します。
出力先フォルダ内にcheckpoint_latest.ptが見つかりました。
中断したトレーニングを再開しますか?(y/n):
と聞かれるので、学習を再開したい場合は y を押してください。
通常学習時と同じようにバッチサイズとステップ数を入力しますが、
前回が10000で中断していて、さらに追加で5000ステップ回したいなら15000といった感じで入力してください。
(追記)
現在の上記の方法で学習再開するとエラーが出てしまうようです。
具体的には、最初にn_stepsで指定した値まで学習が終わったcheckpointは、そこから追加学習はできない、ということのようです。
どうやらn_stepsで指定された値まで学習を行う時、終わる少し前に学習率を減らしていき、完成品にするプロセスを行っているようです。
なので、もしも最初に指定したn_steps分の学習が終わったchekpointに対して追加学習を行う場合は、ひとつ前のcheckpointをcheckpoint_latest.ptにリネームしてから学習再開をする必要があるようです。
デフォルトのconfig設定だと、2000stepごとに中間ファイルを保存するようになっているので、仮にn_stepsを10000に指定して学習が完了した場合、
checkpoint_入力フォルダ名_00008000.pt
というファイルをリネームすることになります。
もしくは、時間に余裕のある方は最初からn_stepsを大きめの値にして学習を開始し、程よいタイミングで手動で止める、というのもアリかもしれませんね。
あとがき
なんだか上級者向けなのか超初心者向けなのかよくわからないチグハグな内容になっちゃいましたが、個人的には生成系AIに興味を持つ方の裾野を広げたいという気持ちがありまして、少しでも導入の手助けになればと思った次第です。
(追記)
Beta.2 になってからまだ少ししか触ってないですけど、コレめちゃすごいのでは…???
以前のノイジーな結果とは大違いでかなりクリアになりましたし。
高音がだいぶきついかな?という印象はありますが、今後事前学習モデルの更新により改善される可能性はありますね。
リアルタイムボイチェン用途であれば、RVCと完全に置き換わるのではないでしょうか。
この記事が気に入ったらサポートをしてみませんか?