【画像班】画像水増し方法について

※本記事は研究室内向けに記述しております
著作物のため本コードはフルコードの記載は控えております
※追記(2022/5/18)
水増し数値データの水増し方法について、本研究室の研究生の助力によりPythonを用いて数値データの処理が可能になったため、新たに追記します。
本記事では、水増し画像作成用のプログラム
mizumashi_2021.py
を用いて、水増し画像加工についてのプログラムを書いていきたいと思います。
①水増し画像(Data Augmentation)を作成する理由
日本では、一般的に「水増し」というとネガティブな表現ですが、英訳「Data Augmentation(データ拡張)」と呼ばれます。データ拡張と呼ばれれば、研究的な表現ですね。(論文では、データ拡張と表現することをお薦めします。)
本研究で用いるLED断面画像データは、156枚と数が少なく学習に対して不十分な量であるため本研究では水増し加工を施し学習を進めていきます。
②作成方法(画像)
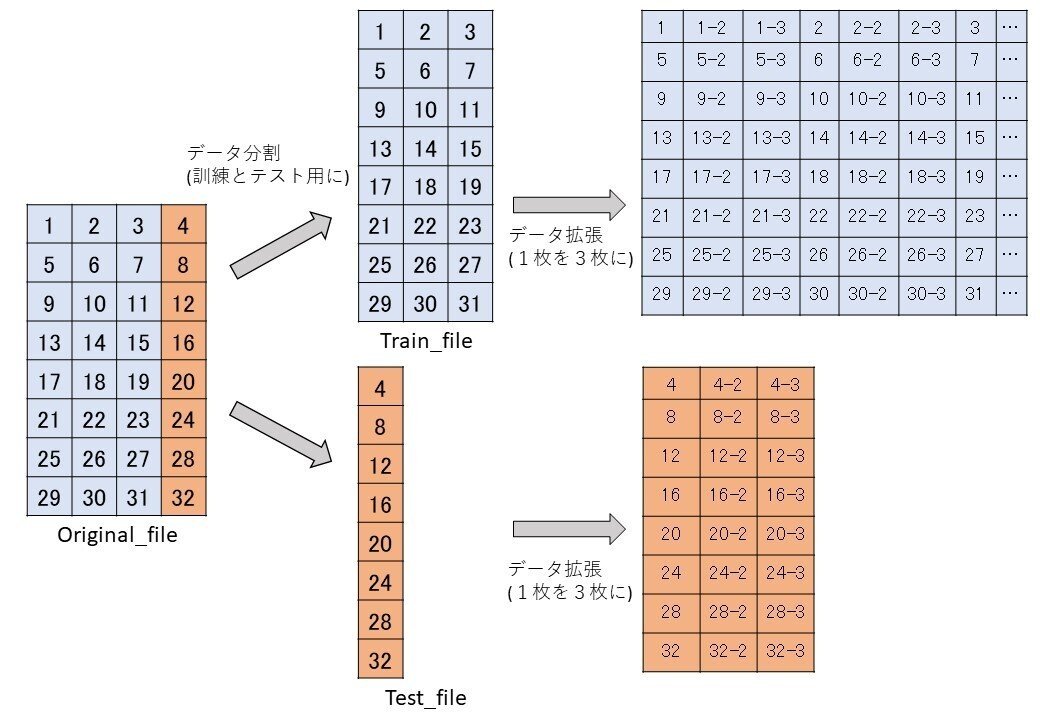
[0] データ加工前の下準備
元データを任意の割合(ex. テストデータ 25% : 訓練データ 75% ←本研究で用いた割合)にファイルを分割する。
それらで分割したファイルを丸ごと下記のプログラムでデータ拡張することになります。
本記事内のプログラムは、CNN班の共有ドライブ内の"2021_CNN"→"mizumashi_2021.py"を参照して下さい。
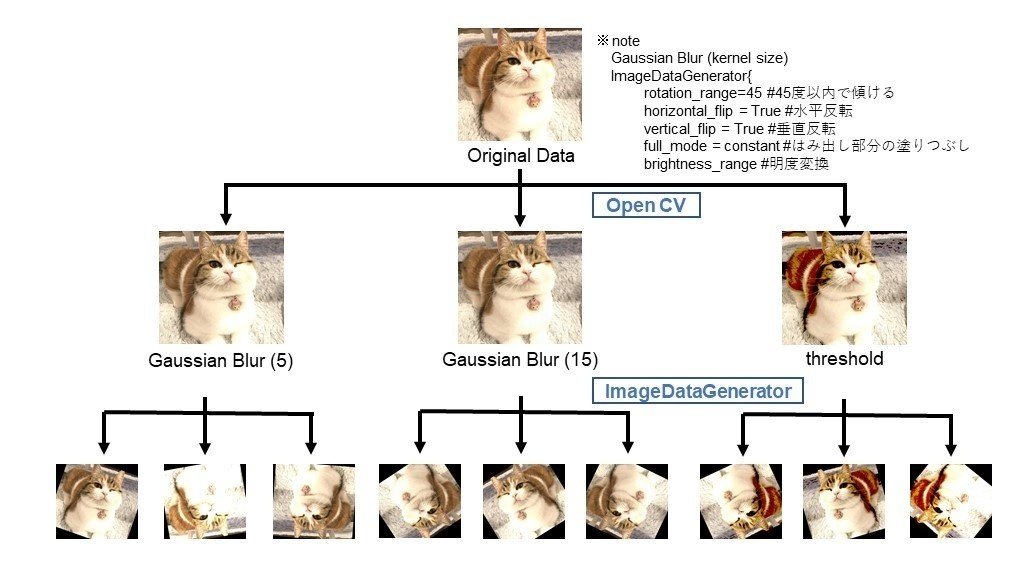
本プログラムでは、下記画像に示すようにOpenCVを用いた「ぼかし加工」と「閾値加工」を行い、
その後、KerasのImageDataGeneratorを用いた学習画像の水増しを行います。
[1] データ参照→アドレス取得
水増し加工を行うOriginal Dataの入っているデータを下記コードにて、アドレスを"paths_mizumashi"内にリスト参照する。
base_path = "C:\\User\\~~\\data\\"
#水増しする画像の参照
paths_mizumashi=natsorted(glob.glob(base_path + "*.jpg"))
print(paths_mizumashi)[2] 従来のデータ加工方法
従来の研究データ(2020年以前)の水増し方法(回転、ぼかし、閾値加工)を、引き継ぐため本プログラムでは、元データに対してあらかじめぼかし加工と閾値加工を行い従来のデータ加工の再現を行う。


それらの従来加工を下記のコードで行う。
for path_mizumashi in paths_mizumashi:
img = cv2.imread(str(path_mizumashi))
ftitle, fext = os.path.splitext(path_mizumashi)
#フィルタ加工 (ぼかし)
filter_para = [5,15]
for i,para in enumerate(filter_para):
img_filter = cv2.GaussianBlur(img, (para, para), 0)
fileName=os.path.join(base_path , ftitle + "_filter_" + str(i+1) +".jpg")
cv2.imwrite(str(fileName),img_filter)
# 閾値加工
img_thr = cv2.threshold(img , 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(base_path , ftitle + "_thresh" +".jpg")
cv2.imwrite(str(fileName),img_thr)[3]Image Data Generator
次にkerasのライブラリの一つである"Image Data Generator"を用いてランダムに画像を生成していきます。
Image Data Generatorは多くの変更パラメータを持ちます。本プログラムでは、下記を用いて作成を行います。
回転加工
45度以内の回転加工を行っています。これは、本研究が分類問題を行うものではなく、線形回帰予測の問題であるため画像内に含まれる情報がとても重要なあるため、素子がはみ出ない範囲での回転加工を行っています。水平加工、垂直加工
LED素子は、垂直加工・水平加工を行う(つまりLEDの向きを変える)場合でも明るさは変わらないため取り入れています。fill_mode
回転加工等行い画像のはみ出た部分の加工をどうするかという項目。
学習に影響のないように本プログラムでは、すべて黒塗りとした。明度変更
素子の情報が欠損しない程度に数値指定した。
datagen = ImageDataGenerator(
rotation_range=45,
#channel_shift_range=100,
horizontal_flip=True,
vertical_flip=True,
fill_mode='constant',
brightness_range=[0.5, 1.5])
filename = ftitle + "_generate_" + str(i+1) +".jpg"
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save(filename)ImageDataGeneratorのその他加工パラメータに関しては下記サイトを参照してください。
なお、本プログラムで作成できる画像の総枚数は、
総枚数=元画像 × 4(従来の加工方法) × (69行目のrangeの値 + 1)
です。作成時には参考にして下さい。
③作成方法(数値データ)
数値データ作成用のプログラムは、本研究室生であるK氏の助力によるものである。
初めにグーグルドライブ内の「2022_CNN」→「make_csv.py」を参照して下さい。
6~10行目で画像Noと画像に対する真値を取得
No = []
No = csv.iloc[:,10].values
lm = []
lm = csv.iloc[:,11].values14行目と19行目のrangeの値は、
rangeの値=(mizumashi_2021.pyの69行目の値+1) × 4(従来の加工方法)
を設定して下さい。
↑上記の内容は、1枚の画像を何枚に増やすかという話です。
つまり、下記の画像を参照すると
従来の加工で1枚の画像が3枚に増やした後に、各々(元画像を含む)を3枚ずつ増やすので、
rangeの値=(3+1)× 4 ←オリジナルも増やしているため

この記事が気に入ったらサポートをしてみませんか?