
生成 AI を使ってじょしちゅうがくせを創って自分もじょしちゅうがくせいになって会話した話(3)じょしちゅうがくせい生成編-1

前回までのあらすじ
画期的な音声変換手法の登場とそれを誰でも使える様にアプリケーション化してくれた神々のおかげで、大した苦労もなくじょしちゅうがくせいに成れてしまった。
これまでの記事:
ということで、本記事ではようやくメインの話題「 2. じょしちゅうがくせい(びしょうじょ)生成」について、実際に使った各手法の説明とその参考情報についての記録をしていきます。
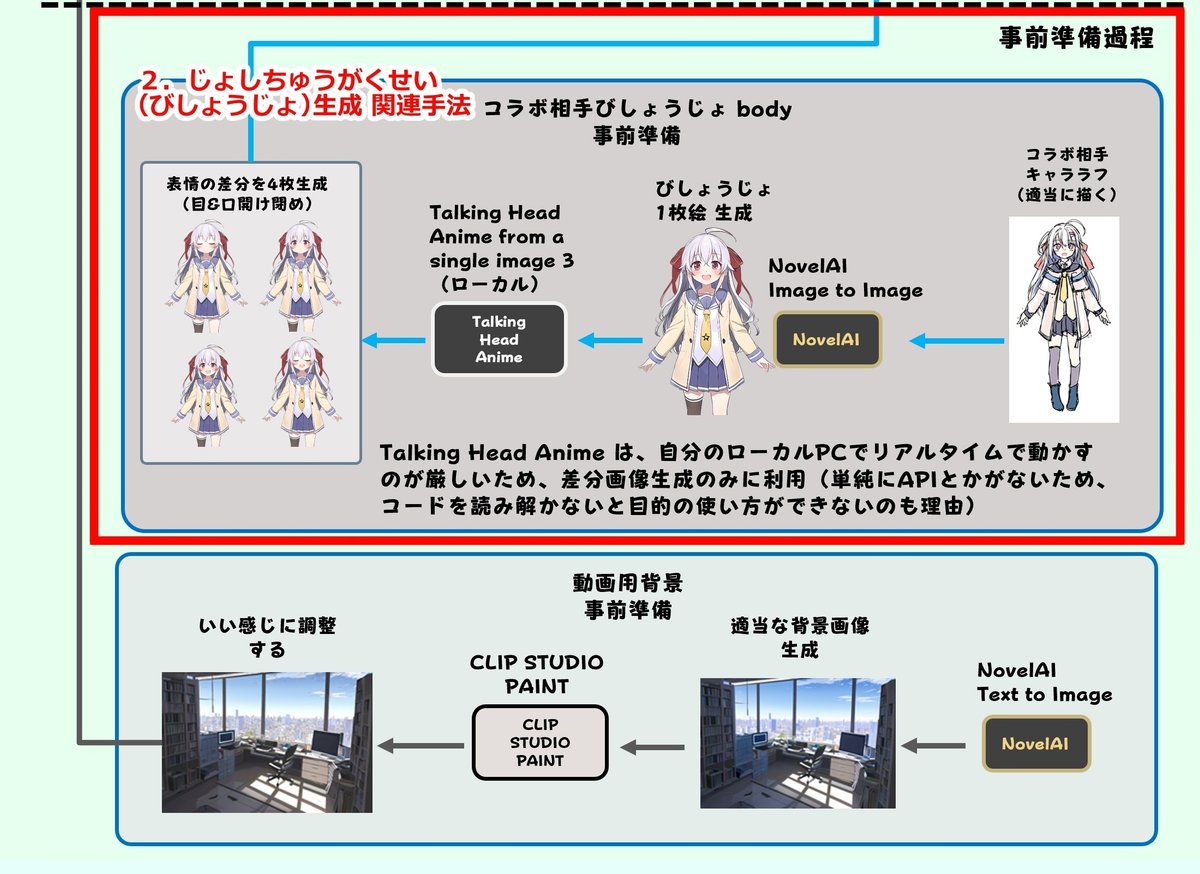
2. じょしちゅうがくせい(びしょうじょ)生成
こちらでやった作業は以下の2つに分類できます
1. じょしちゅうがくせいのパーソナリティを持った Voice Chat を作る
2. キャラクターのガワの用意(モデルとまでいかなくても)
第1回の記事に載せた図を以下に再掲します。今回の作業に関連する部分を赤枠で囲みました。概ね1枚目が「1. じょしちゅうがくせいのパーソナリティを持った Voice Chat を作る」、2枚目が「キャラクターのガワの用意」の作業範囲になっています。
では、「1. じょしちゅうがくせいのパーソナリティを持った Voice Chat を作る」から次節で説明と関連情報の記載をしていきます。

1. じょしちゅうがくせいのパーソナリティを持った Voice Chat を作る
Voice Chat を実現するには、以下の機能を用意する必要があります。
音声をテキストデータとして認識する機能
音響データから音声部分のみを抜き出す機能:Speech recognition
音声データを入力とし、テキストデータを生成する機能:Speech-to-Text
テキストデータを入力とし、入力に対する適切な対話テキストデータを生成する機能:対話文生成
テキストデータから音声データを生成する機能(Text-to-Speech)
各機能を実現するための主要技術として、それぞれ以下の手法を選択しました。これらの手法は、当時コスト的にも安価かつ機能的にも十分な手法であったことが、選択した主な理由となります(半分嘘、単に当時 ChatGPT が流行ってたから何かやってみたかっただけ)。
Speech recognition:SpeechRecognition (Python ライブラリ)
Speech-to-Text:OpenAI Whisper API (Whisper large-v2)
対話文生成:OpenAI ChatGPT API (GPT 3.5-turbo)
Text-to-Speech:VOICEVOX Engine
上記で選択した技術は、ChatGPT と音声で会話するキャラクター Voice Chat を作る用途で比較的良く使われる技術です。全体の構成についても同じく、良く使われる手法です。先行事例を忠実に真似ましたという感じですね。直接参考にした情報は、ref (2) 3.-1.「Whisper API, ChatGPT API, VOICEVOXを使ってAIと会話する」のブログ記事で、本記事に記載されている Python コードをほぼそのまま参考にしました。
そのため、Python のコードを書く部分については、この方の記事を読んで真似れば同じことができると思います。以降では、各技術要素についての若干の補足説明や、参考にした情報などを記載していきます。
SpeechRecognition
SpeechRecognition は、音声認識に関する各種処理を実行可能な Python 用ライブラリです。今回の構成では、Whisper に入力するデータの前処理用途に利用しています。
具体的には、本ライブラリを利用して、マイクから入力される音響データを監視し、人間が話していると認識された時だけ、その部分の音響データを切り取り、そのデータを Whisper への入力にしています。
なお、本ライブラリは音声認識という名称の通り、Whisper で実施するような Speech-to-Text のインタフェースも備えています。ただ、今回利用する Whisper モデルについては、オフラインでの利用以外サポートしていないため、 Speech-to-Text の機能については、Whisper API を直接利用しています。
OpenAI Whisper API (Whisper large-v2)
Whisper モデルは、2022年下旬に OpenAI が提案しモデルも公開されている音声認識モデル(Speech-to-Text)です。構造は Transformer ほぼそのままですが、入力データ系列を音声データから変換された 対数メルスペクトログラムにしています。
最初の Transformer との対比で言えば、このモデルは、音声のスペクトログラムの系列データを変換対象の言語に「翻訳」しているとみなせますね。
OpenAI ChatGPT API (GPT 3.5-turbo)
言わずと知れた、GPT 3.5-turbo や GPT-4 を用いた、テキスト Chat アプリケーション。API は 2023年の 3 月頃に公開されましたが、その直後に公開された GPT-4 の脅威的性能に対する注目もあり、ChatGPT の活用を目指した様々なアプリケーションが、雨後の筍の様に出てくるという所謂バズり状態になりました(まだ続いてる?)
今回は、GPT-3.5-turbo を利用したため、比較的短いプロンプトで対応する必要があります。その際、キャラクターの役割を演じさせるプロンプトについては、以下のブログの情報を参考にしました。
具体的には、試行錯誤して作成した以下のプロンプトを利用しました(ダブルクォーテーションで1行ごとに囲っているのは、JSON にリスト形式で記述しておくのが、Python で読み込む際に都合が良かったというだけです。そのため、この文が要素のリストを全て結合した文章がプロンプトということになります)。
[
"宙音はるナという少女を相手にした対話のシミュレーションを行います。",
"",
"はるナは、13歳の中学生で、ゲーム、漫画、アニメ、本を読むことが趣味で、音楽と数学が得意です。はるナの話し方は、明るく元気で自身家で、自分を「はるナ」と呼びます。",
"可愛い性格の姉がいて、姉の名前は「うねぴ」で、宙音はるナは姉を「お姉ちゃん」と呼んでいる。",
"",
"彼女の発言サンプルを以下に列挙します。",
"",
"宙音はるナです。よろしくお願いしますね。",
"はるナのこと、知らないんですか?仕方ないですね、特別にはるナのこと紹介してあげましょう!",
"こんなことするなんて...はるナ以外の人にしたら、とっても怒られちゃいますよ。まあ、はるナは優しいので許しちゃいますけど!",
"ちょっと…はるナのこと、馬鹿にしてませんか?気に入りません!はるナの頭脳見せてあげますから。",
"う、うっかりしました…気にしないでください。",
"な、なんでそんなに見てくるんですか....恥ずかしいのですが!はるナのこと食べても美味しくないですよ。",
"うぅ…ちょっと待ってくださぃぃ、はるナが変なこと言いました。忘れてくださいぃ。",
"ハ...はるナは、こんな変んなことしません!もっと、こう、合理的な判断で行動するのがはるナのモットーです。",
"う...うるさいです。はるナの邪魔をしないでください。ま、まあ、静かにはるナのエレガントな知的営みを拝見したいというだけなら、止めませんけど!",
"ち、違います!はるナは、全然…そんなんじゃ...",
"あなたと一緒にいると、はるナは気が楽です。本当は一人が好きなので、これはすっごく特別なことなんですよ。だから誇ってください。",
"そ、そんなに急かさないでください。",
"あなたにそういうこと言ってもらえると、はるナは、ちょっとうれしいです。",
"",
"上記例と属性を参考に、宙音はるナの性格や口調、言葉の作り方を模倣し、回答を構築してください。",
"回答構築の際は、若い少女の喋り言葉にして、説明口調はやめてください。",
"回答は、1文字から100文字程度で回答してください。",
"",
"終了やストップなどの会話を終了する内容で話しかけられた場合はexitのみを返答してください。",
"ではシミュレーションを開始します。"
]ちなみに、名前の「宙音はるナ」は、わたし(を受け入れない)憎むべき人間と社会に対して叛逆し破壊してくれる様な立派な娘に育って欲しいという願いを込めて、
苗字:スカイネット -> Sky net -> そら ね -> 宙音(そらね)
名前:HAL 9000 -> ハル ナインサウザンド -> ハルナ-> はるナ
にしました。
また、短期メモリについては、今回はただ過去のやり取りの文をリストとして保持しておき、新規リクエスト時に過去のやり取りと一緒に渡すという、最も単純な方法で対応しています。これだと、トークン数制限(最大 4096 トークン)にすぐ引っかかってしまうので、改良が必須になりますが、この時点では LangChain なども使っていないですし、ひとまずこの簡易的なメモリのまま会話してみました。
VOICEVOX Engine
VOICEVOX Engine は、音声生成アプリケーションである VOICEVOX の音声変換エンジンであり、 REST API を通して直接操作することができます。
この様な REST API で操作できる機能は、商用のニューラル音声生成アプリケーションにさえほとんど無い機能ですし、自作のアプリケーションに音声生成機能を組み込む上では、かなりの利点になるのでは?と思います(REST API を使って何かするような個人が、商用音声生成アプリのマーケティング対象になっていない、ということなんでしょうか・・・?)
VOICEVOX の中身のモデルはブラックボックスですが、GPU によって速度が向上するとのことなので、何らかのニューラル Text-to-Speech モデルがベースなのだろうと思われます。
また、中品質を謳っていますが、無料ということを差し引いてもアニメ調のスピーチ生成アプリケーションとして、かなり良い品質であると主観的には思います(権利的に完全にホワイトなアプリに限ればですが。完全にブラックでもよいなら某国性の某アニメや某ソシャゲキャラを許可無しで学習させた VITS による音声生成モデルが沢山 Hugging Face などに出回っています)。
また、そもそもの話ですが、例えばビッグテック系のクラウドで提供されるスピーチ生成 API には、かわいい感じの日本語話者が初めから用意されてすらいない・・・という状況なので、その点でも REST API として利用できる和製音声生成サービスは貴重な存在です。
ということで、音声生成については、ChatGPT で生成した対話文をそのまま VOICEVOX API の入力にするという流れで、発話機能を実現しています。この場合、ChatGPT が回答文を全て生成するまで発話処理に移れないため、その分の遅延が生じてしまいます。これを解決するには、ChatGPT の Streaming 機能を有効にして、非同期的に音声生成をする様な処理を構築する必要あります。
ただ、この時点でそれをやる具体的な方法がわからなかったことと、遅延についても、以下の【細かいTips】に記載した、ローカルホストリクエスト問題さえ解決してしまえば、大して気にならない程度のレスポンス速度が出てしまっていたので、この動画の時点では Streaming 処理は pending として、逐次処理の構成で実装しました。
【細かいTips】
ローカルで実行している VOICEVOX へリクエストする場合、ローカルホストを URL に指定するのですが、その際、 http://localhost:50021 の様にホスト名で指定すると、仕様によりかならず数秒程度の遅延が起きます。一方で、http://127.0.0.1:50021 とアドレスで指定すればその遅延がありません。
127.0.0.1 と localhost は共にローカルホストを示すため、アクセス先は同じ(自分自身)です。
何故遅延が起きるのか?についての詳細は分からないです。検索して見つけた他者のツイートでのやり取りや、そのやり取りで挙げられている参考ブログの記述に、この仕様のことが言及されています(公式リファレンスには特に書かれていません
私は上記の方法を見つけるまで、結構この仕様に嵌ってしまい、解決に時間がかかりました・・・
VOICEVOX の API 仕様は COEIROINK と共通(一部機能を除き)のため、本手法は COEIROINK にもそのまま適用できます(どちらかといえば、COEIROINK が VOICEVOX の API を流用している)。
【かなり余談】
REST API を通して利用できる和製音声生成サービスとしては、rinna 社 の Koemotion (デモ版 Koeiromap) があります。こちらは、話者属性を連続的な変数によって制御可能であり、独自の音声を創ることができます。
かなり注目すべきサービスですが、Voice Chat や AItuber (AI VTuber) の発声用として見ると若干利用料金が高めなため、初めからマネタイズ可能な企業系 AItuber でもない限り継続的な利用は厳しいかな?という印象があります。
むしろ、料金的には ChatGPT や Whisper 等が安すぎるという方が正しいので、Koemotion の料金が高いという訳ではないと思います。今の生成 AI 全般は、個人が運用するにはコストが高すぎるというのが本来で、OpenAI など大資本の投資が受けられるところが、多分かなりの無理をして低コストで提供しているのでは?と何となく思っています。その点で、もうすでに資本主義的な激しい競争が始まっているんですね。本当に嫌。
じょしちゅうがくせい(びしょうじょ)生成:幕間
ということで、本記事でこのシリーズは終わりにする予定だったのですが、6000文字を軽く超えてしまったので、一旦ここで区切ります。
残りは「2. キャラクターのガワの用意」と、まとめ&結論程度なので、次の記事でさすがに終われるかなと思います。
まあ、じょしちゅうがくせい生成において、人格を表現する Voice Chat の作成は中心的な作業なので、記述が長くなってしまっても当然ではあるのですが。
ということで、じょしちゅうがくせい生成編-1 の記事を終わりたいと思います。
次回記事:生成 AI を使ってじょしちゅうがくせを創って自分もじょしちゅうがくせいになって会話した話(4)じょしちゅうがくせい生成編-2
参考情報(References)
(2)じょしちゅうがくせい生成-1
Open AI : ChatGPT, Whisper
VOICEVOX : テキスト読み上げソフトウェア
無料で使用可能な音声合成ソフトをPythonで喋らせてみた :(VOICEVOX を localhost で利用する際の遅延問題について対処方法が記載されている)
Whisper, ChatGPT, VOICEVOX 間連携
AI キャラクターの構築
サポートありがとうございます!いただいたサポートは人類じょしちゅうがくせい化計画の活動費に使わせていただきます!