
「人工知能」は、どのような流れで作るのか ~ 実作業と、その位置づけ ~

注
本記事では、「人工知能」のうち「深層学習」をメインに書きます。
なお、別の形式の「人工知能」も、似ている部分はけっこうあります
そもそも「人工知能」とは、基本的に「自動化」
人間の判断や作業を代わりにやってくれます
「人数を数える」「顔画像から年齢を推定する」「自動運転する」
「顔を検出して温度を計測し、高温だとアラートが鳴る」
「需要を予測する」「購買データを地域ごとに分析する」
「動画の視聴時間から好きな動画を把握してレコメンドする」
といったものがあります。
最近は、
キーワードを入れたら記事を自動的に作ってくれたり、
新しいキャラクターを作ってくれたり、という「創造」に近いものも。
このように、人が行ってきた判断や作業を、
プログラムが代わりにやってくれること(自動化)を
実現するための手段の一つが「人工知能」です。
【本題】つくる流れ。
いくつかのサイトを引用して解説します。
まずはこちら
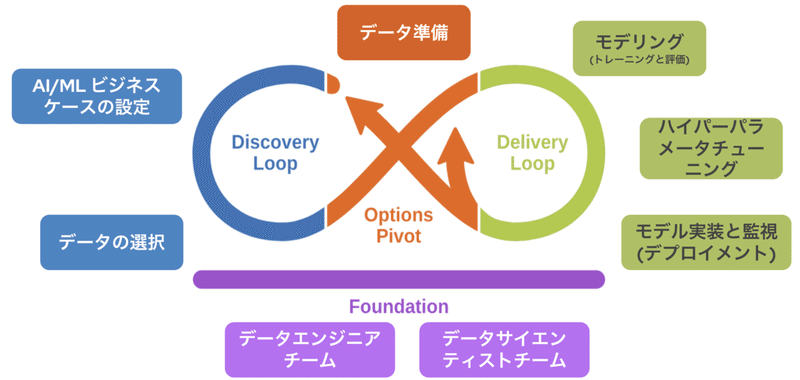
作業としては∞の形のサイクルを、ひたすら回すことになります。
【A】
・ 必要なデータを集めて、整えて、「正解」を付ける(データ準備)
・ モデルの構造を考える、学習・評価する(モデリング)
・ 学習を調整して精度を更に上げる(ハイパーパラメータチューニング)
・ アプリへの搭載と運用(デプロイメント)
→ エンドユーザからのフィードバックを受けて、
「精度を向上」「新たなモデルを構築」するための方針とする
【B】
・ どのようなAIが必要かを決める(ビジネスケースの設定)
・ そのAIに必要なデータを検討する(データの選択)
本当に重要なのは・・・
ついつい【A】の部分が注目されがちですが、
実運用を考えると【B】が大切です。
「作業の自動化」が目的のはずだからです。
目的、つまり
・ どういう状態が望ましいのか
を先に考える必要があります。
具体的には
・ 主力商品がちゃんと売れているか、変化を把握したい
・ 想定した年齢層の人が来てくれているのかを知りたい
・ 体温が高い人が来たら別室に連れて、全体の安全を確保したい
・ 単純作業の時間を減らして、好きなことをしたい
などなど。
こういった「望ましい状態」を考えることで、
どのような「人工知能」を作るか、と考えを進めていくのが、
理想的な流れです。
そのためには、「望ましい状態」を考えている人たち、
つまり、どんなビジネスを行っていきたいのか、
とを考えている人たちと話をして決めていくのが重要です。

手段と目的が入れ替わらないように、注意しましょう。
(とはいえ「人工知能」ってどんなことができるの?というのが、全くわからない状態だと「こうしたい」というのも思いつけないという難しさがあるとも思いますが…)
【A】の開発部分について

下記リンクの「ABEJA」の記事から抜粋

同記事から抜粋
特に大変なのは、データの管理とアノテーション
あくまで主観ですが、
「データの管理」と「アノテーション」が大変です。
まず「アノテーション」から
聞き慣れない言葉だと思います。
「アノテーション」とは、「正解」を人力で付けることです。
(分野が違うと違う意味で使われることもあります)
「正解」とは、下記の例だと、
画像を受け取って「これはなんですか?」と質問されたときに
「猫です」と答えられるようにするために、
「コンピュータに教えるためのデータ」のことです。

人間にとっては「あ、猫だな」と簡単にわかりますが、
コンピュータにとっては画像は数値データでしかないため、
このように正解を覚えてもらう必要があるのです。
この作業のことを「機械学習」「深層学習」と呼びます。
というわけで、
たくさんある画像に「これは猫だ」「これは犬だ」といった正解を、
準備していく必要があります。これが、大変だし大切です。
(詳細は別の記事に記載します)
「データの管理」は何が大変か
データ管理は、大きく2つの側面があります。
1. データの特徴を把握できる状態にする
2. 実際に学習に使用する
1. については、
・ いつ、なぜ取得したデータか
・ どの学習に使用したか
・ このデータが精度に与えた影響はどのくらいか
・ どのように正解づけを行ったか
・ 誰が正解をつけたか
といった項目を、把握する必要があり、
これらをもとに、どのように精度を上げるかを考えることになります。
最新状態を保持するのが大変です。
2. については、
例えば画像で学習させる場合、
精度向上を狙って、「左右反転」「色調変更」「コントラスト補正」「少しだけ回転」といった操作(前処理)を行うことがあります。
このような操作を行った場合、
元の画像1枚が、例えば10枚とか20枚になってしまうことがあるため、
これらの画像を全て保存しておこうとおもうと、
データ容量がすごいことになってしまいます。
一般に、高精度を狙いたい場合、
画像は数千枚必要なことが多いため、
もとが数千枚だとすると、
20倍したら数万枚、数十万枚になってしまいます。
とはいえ、
学習するたびに、毎回作るのか?というと、
それはそれで大変です。
それぞれ、課題はありますが、
環境に合わせて、どのようにしていくかを選んでいく必要がありますね。
このような、データ管理の大変さと、アノテーションの大変さを解決するために、各社のSaaSが登場している、というのが、昨今の情勢です。
(2022年02月 現在)
【補足】検索ワードは「MLOps」
「MLOps」という用語を調べると、作る流れなどが、けっこう出てきます。
(ML: Machine Learning。機械学習)
ビジネスのオペレーション(Operation)を考慮して、
機械学習で必要なモデルを作っていく、ということですね。
そのためのしくみが、サービスとして登場してきているので、
みなさん苦労してるのが伺えます。
まとめ
人工知能とは。どのように作るか。
を見てきました。
なんとなくは、わかりましたでしょうか。
諸般の事情から、急ぎで作成したため、
いろいろと不足していることもあると思いますので、
もしご指摘やコメントなどいただけると、とてもありがたいです。
長文にお付き合いいただき、ありがとうございました!
補足: 実は「人工知能」は「ほんの一部」

他にも膨大な作業や、重要な要素があることを言っている。
下記の英語記事に登場する図
「人工知能」を作ることも、とっても手間がかかるけど、
もっともっと、他の要素が大変で重要である、と、この記事は主張しています。
翻訳記事もありました。
この記事が気に入ったらサポートをしてみませんか?