共演回数が一番多いエロゲ声優といえば誰と誰?(2005~09年版)

※本記事は声優名敬称略でお届けします。
先日、Twitterで(00年代後半に)よく出演するエロゲ声優の話題になりました。その中で、
そういえばもしかしたらご本読み飛ばしてるかもしれませんが、この「この声優はこの声優とよく一緒にいる」みたいなのってえろすけのあれそれでできたりしないんでしょうかね。
— 玉泉のす (@nosuo_nosuo) May 11, 2021
という感じで、エロゲトリビアの種をいただきました。こんなんなんぼあってもいいですからね。
「この声優はこの声優とよく一緒にいる」をテーマに、今回はシンプルに「共演回数が多い組み合わせ」を調べます。
■集計対象
ErogameScapeで、以下の条件にあてはまるゲームとそれに出演する声優さんの対応を取得し、共演回数を調べました。
・2005年~2009年発売のアダルトゲーム(同人含む)
・ユーザーからの点数入力数100以上のゲーム(集計コスト削減のため)
・メイン、サブのほか、モブでの出演もすべて含む
SQL文は以下の通りです。
SELECT c.name, s.game
FROM shokushu s
JOIN gamelist g ON s.game=g.id
JOIN createrlist c ON s.creater = c.id
WHERE s.shubetu = 5
AND g.count2 > 99
AND g.erogame <> 'f'
AND g.sellday BETWEEN '2005-01-01' AND '2009-12-31'
ORDER BY s.game, s.creater■3位
同率も含め、上位3位から発表します。
3位:共演本数31本
'一色ヒカル', '青山ゆかり'

ひだまり (AXL) (2006-05-26) など
3位:共演本数31本
'青山ゆかり', '北都南'

魔界天使ジブリール -episode2- (FrontWing) (2005-04-22) など
3位:共演本数31本
'一色ヒカル', '北都南'

おたく☆まっしぐら (銀時計) (2006-09-29) など
3位:共演本数31本
'かわしまりの', '風音'

超昂閃忍ハルカ (ALICESOFT) (2008-02-29) など
3位:共演本数31本
'みる', '風音'

ゴア・スクリーミング・ショウ (BLACK Cyc) (2006-01-20) など
■2位
ここからは2位になります。
2位:共演本数32本
'一色ヒカル', '風音'

世界でいちばんNGな恋 (HERMIT) (2007-11-22) など
2位:共演本数32本
'まきいづみ', '一色ヒカル'

姉汁 ~白川三姉妹におまかせ~ (アトリエかぐや) (2005-11-25) など
■1位
1位:共演本数39本
'まきいづみ', '青山ゆかり'

さかしき人にみるこころ (light) (2008-05-30) など
■4位以降
4位以降の結果は以下のようになります。
結果として1位の「まきいづみ、青山ゆかり」コンビが飛びぬけましたね。
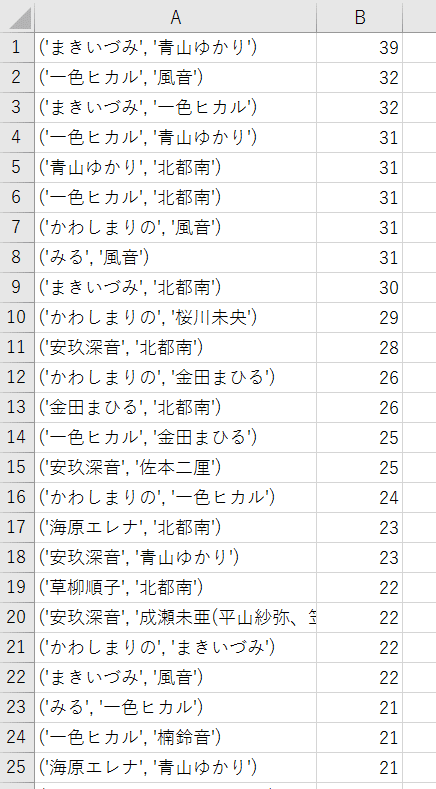
フルバージョンのスプレッドシートもおいておきます。
■課題と展望
①出演数の補正
今回の集計の課題としては、「シンプルに出演数が多い人は上位に入りやすいよね」という側面があります。
参考までに、今回の集計対象における声優の出演ゲーム数は以下のようになってます。
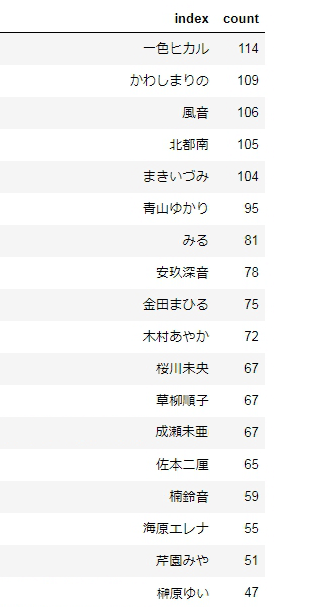
一色ヒカル、かわしまりのを始めシンプルに出演数多い人が、今回のコンビ集計でも上位にくるのは当たり前ですので、『共演しやすさ度合い』という意味ではまだ微妙なところがあります。
かといってそのまま出演数で割ると、出演数1本同士の声優のコンビが共演率100%になってしまうので、上手な補正を考えたいところですね。
②他の年代およびブランドとの対応
今回は00年代後半に絞ってやりましたが、他の年代でもやってみたいですね。あとは、ブランド名との関係もとって、AXLは青山ゆかり・松田理沙が出がち、クロシェントは桜川未央が出がち、みたいなところがとれたら面白そうです。
もうちょっと遊んでみたいですね。
■組み合わせ集計方法
ここから先は、今回行った集計の方法を書き残しておきます。ぜひいろいろアレンジして遊んでみてください。
前述のSQL文で得られた表をvoice.csvとして保存し、pythonで以下の処理を行いました。
import pandas as pd
import itertools
import collections
import csv
#csv読み込み
df = pd.read_csv('voice.csv')
#ゲームidを重複なしで取り出す
uniq_game = df["game"].unique()
#ゲームidが与えられたら「それの出演声優の全員のうち2人を選ぶ全ての組み合わせを
#combination_listに入れる関数」を定義する。
def make_combi_that_game(game_id):
df_part = df.loc[df['game'] == game_id, ['name']]
s_part = df_part['name']
set0 = []
for i in s_part:
set0.append(i)
for x in itertools.combinations(set0, 2):
combination_list.append(x)
return combination_list
#ゲームid全てについて、上記の関数処理を行う。
combination_list = []
for z in uniq_game:
make_combi_that_game(z)
#集計してcsvに書き出す。
c = collections.Counter(combination_list)
with open('rank_voice_0.csv', 'w', newline='') as file:
writer = csv.writer(file, quoting=csv.QUOTE_ALL,delimiter=',')
writer.writerows(c.most_common())
#参考:声優の出演ゲーム数(今回の集計対象のゲームのうち)
act_number = df["name"].value_counts().rename("count").reset_index()
print(act_number.head(30))
#いろいろとスマートではないかもしませんが、そこはあまり気にしないでこの記事が気に入ったらサポートをしてみませんか?