Kaggleのタイタニックコンペに参加してみた(欠損値補完編)

4月からAI Academy Bootcampを受講しているTriaezuです。
年初に機械学習に興味を持ち、3月にPyQのライトプランに1ヵ月加入し、Pythonの基礎や機械学習の基本を学びました。本格的に学ぶにつれ、機械学習エンジニアとして働きたいと思い、AI Academyさんのブートキャンプに4月から参加しました!(選んだ理由等は今度書きます)
その第一回目の課題ではKaggleのTaitanicコンペに参加することでしたので、そのときのコードを少し書いてみようと思います。良さそうなKernelを完璧にパクっただけなので、詳細なコードは以下のリンクを見ていただけたらと思います。
Titanic Top 4% with ensemble modeling
このKernelからはEDA、欠損値の補完、特徴量選択、モデルの選択・学習などの大まかな流れを学べました。
その中で今回は欠損値の補完に焦点を当てて紹介します。
0. データの用意
kaggleのコンペのページにあるDataからDownload Allで全てのデータを一括でダウンロードできます。

次にデータを取り込みます。
import pandas as pd
train = pd.read_csv('CSVファイル名')
test = pd.read_csv('CSVファイル名')ではさっそくトレーニングデータの中身を見ていきましょう。
1. 表の一部を表示させてみる
train.head()
#トレーニングデータの5行目までを表示してくれる
#例えばn行目までみたいときにはtrain.head(n)とすれば良い
2. 外れ値の削除
外れ値の検出方法としてテューキー(Tukey)法を使っていきます(テューキー法については後日別の記事で解説します)。
def detect_outliers(df, n, features):
outlier_indices = [ ] #異常値をまとめたリスト
for col in features:
Q1 = np.percentile(df[col], 25)
Q3 = np.percentile(df[col], 75)
IQR = Q3 - Q1
outlier_step = 1.5 * IQR
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step)].index
outlier_indices.extend(outlier_list_col)
outlier_indices = Counter(outlier_indices)
multiple_outliers = list(k for k, v in outlier_indices.items() if v > n)
return multiple_outliers
Outliers_to_drop = detect_outliers(train, 2, ["Age", "SibSp", "Parch", "Fare"])実際にトレーニングデータから外れ値を削除してみる
train = train.drop(Outliers_to_drop, axis=0).reset_index(drop=True)3. 欠損値をチェックする
まずはトレーニングデータとテストデータをくっつけて欠損値をチェックします。
dataset = pd.concat(objs=[train, test], axis=0).reset_index(drop=True)
dataset.isnull().sum().sort_values(ascending=False)
axis=0で、それぞれの行ラベル(インデックス)に対してメソッドを適用しています。列ラベルに対してはaxis=1でメソッドを適用できます。
欠損値のチェックをすることはどのコンペでも必ずやると思うので覚えておいて損はないです。
それぞれ変数の型、分布具合は以下のように確かめることができます。
train.dtype
train.describe()
4. float型の変数の分布を観察する
4-1. Age
g = sns.kdeplot(train["Age"][(train["Survived] ==0) & (train["Age"].notnull())], color="Red", shade=True)
g = sns.kdeplot(train["Age"][(train["Survived] ==1) & (train["Age"].notnull())], color="Blues", shade=True)
g.set_xlabel("Age")
g.set_ylabel("Frequency")
g.legend(["Not Survived", "Survived"])

4-2. Fare
dataset["Fare"] = dataset["Fare"].fillna(dataset["Fare"].median())
g = sns.distplot(dataset["Fare"], color='m', label='Skewness:%.2f'%(dataset["Fare"].skew()))
g = g.legend(loc="best")
歪度が高いので対数変換してあげます。
dataset["Fare"] = dataset["Fare"].map(lambda i: np.log(i) if i>0 else 0)
g = sns.distplot(dataset["Fare"], label="Skewness: %.2f"%(dataset["Fare"].skew())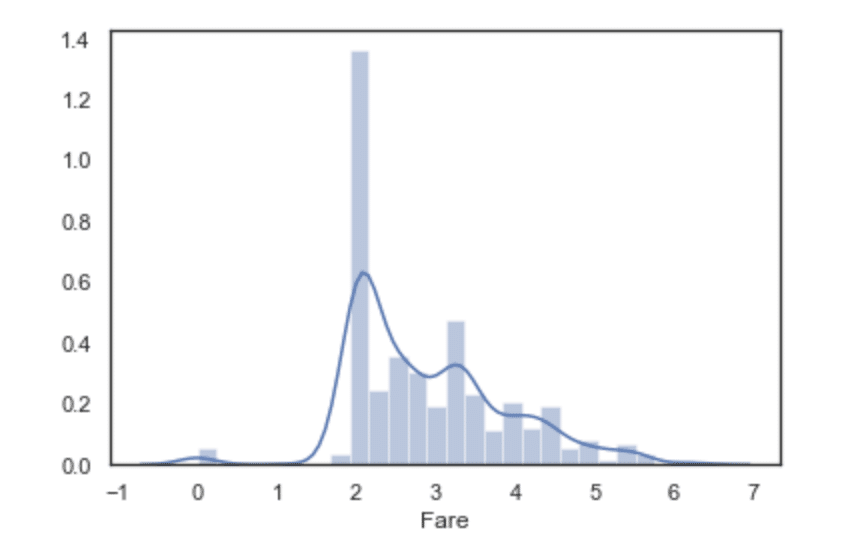
5. 欠損値を補完する
まずは欠損値の少ないEmbarkedから補完していきます。
5-1. Embarked(乗船した港)
欠損値の個数が2つしかないので最頻値で補完します。
dataset["Embarked"] = dataset["Embarked"].fillna(dataset["Embarked"].mode())
5-2. Age(年齢)
まずは年齢と最も相関が高い説明変数を見つけていきましょう。
性別だけがカテゴリ変数のままなので、エンコーディングしておきます。
sex_mapping = {'female':0, 'male':1}
dataset["Sex"] = dataset["Sex"].map(sex_mapping)
g = sns.heatmap(dataset[["Age", "Sex", "SibSp", "Parch", "Pclass"]].corr(), annot=True)
Ageの行(列)を見ると、AgeとSexの相関係数が低いことがわかります。なので、SibSp, Parch, Pclassを用いて欠損値を補完することにします。
index_NaN_age = list(dataset["Age"][dataset["Age"].isnull()].index)
for i in index_NaN_age:
age_med = dataset["Age"].median()
age_pred = dataset["Age"][((dataset["SibSp"] == dataset.iloc[i]["SibSp"])
& (dataset["Parch"] == dataset.iloc[i]["Parch"])
& (dataset["Pclass"] == dataset.iloc[i]["Pclass"]))].median()
if not np.isnan(age_pred):
dataset["Age"].iloc[i] == age_pred
else:
dataset["Age"].iloc[i] == age_medage_predではPclass,Parch,SibSpの値が同じ行の中央年齢を出力しています。
5-3. Cabin(部屋番号)
まずはCabinの詳細な情報をdescribe()で見ていきます。
dataset["Cabin"].describe()
カウントできる値が292個に対し、欠損値は1007個あるので、平均値や中央値などのカウントできる値を使った補完の仕方は良くなさそうだとわかります。なので、欠損値に対しては適当な文字を与えてCabinカラムの全体を可視化してみましょう。
dataset["Cabin"] = pd.Series([i[0] if not pd.isnull(i) else 'X' for i in dataset['Cabin'] ])さて、上のコードで欠損値は全て"X"と置き換え、欠損値以外の値では"B57","B59"のように先頭にあるアルファベットが部屋の位置を大まかに表しているので数字を捨ててアルファベットだけを抽出しています。
g = sns.countplot(dataset["Cabin"], order=['A','B','C','D','E','F','G','T','X'])
Xが圧倒的に多いですね。では部屋番号ごとの生存確率はどうなっているでしょうか。
g = sns.factorplot(y="Survived", x="Cabin", data=dataset, kind='bar',
order=['A','B','C','D','E','F','G','T','X'])
g = g.set_ylabels("Survival Probability")
Xよりも部屋番号を持っていた方の方が生存確率が高いことがわかります。ですので、番号を持っていない人に対して、変に他の部屋番号を推測して、あてはめるのは得策ではないのかもしれません。
dataset = pd.get_dummies(dataset, columns=["Cabin"], prefix="Cabin")最後にOne-Hotエンコーディングしてあげればこれで欠損値の補完は終了です。
最後に
これで欠損値の補完が終わり、次に行うことは特徴量の選択です。今後もTaitanicの特徴量選択編、モデル選択編と書いていく予定ですので、応援してもらえるとモチベが上がり、記事を書くスピードが早くなるのでよろしくお願いします!(欠損値の補完の仕方が甘かったりしたらコメント等で指摘してくださると幸いです。)
私のように最近Kaggleに興味を持った方や始めてみたけど何をしたら良くわからない方にこの記事が刺されば嬉しいです。
この記事が気に入ったらサポートをしてみませんか?