
『Python実践データ分析100本ノック』ノック21〜25

今回は、『Python実践データ分析100本ノック』で学んだことをアウトプットします。
データ件数は、len()で把握
データの件数は、len()を用いて把握することができます。
データの先頭数行を表示させるには、head()を用います。
print(len(uselog))
uselog.head()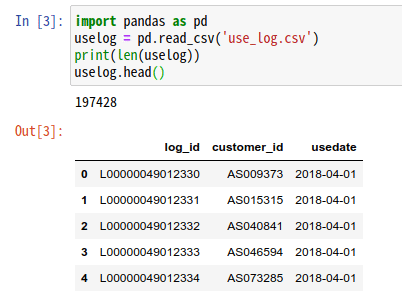
ジョイン後は欠損値の確認を忘れずに!
データをジョインする際、キーが見つからないなど、うまくジョインできないと、欠損値が自動で入ります。そのため、ジョイン後は欠損値の確認をするようにしましょう。
customer_join.isnull().sum()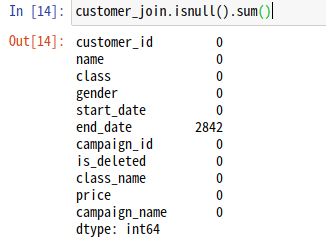
groupby() + count()でデータ件数を集計
例えば、会員区分ごとに顧客データを集計する場合、会員区分(class_name)でgroupbyを行った後で、.count()を行うことで顧客データの件数を集計できます。
今回は、customer_id毎にカウントを行っています。
customer_join.groupby('class_name').count()['customer_id']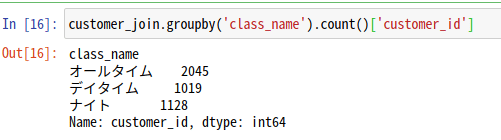
次に、期間中に入会した人数(入会人数)を集計します。入会人数は、start_date列が2018年4月1日から2019年3月31日までのユーザーとなります。
手順としては、
1.start_dateをdatetime型に変換
2. customer_startというデータフレームに該当ユーザーのデータを格納
3. データの件数を表示
となります。
customer_join['start_date'] = pd.to_datetime(customer_join['start_date'])
customer_start = customer_join.loc[customer_join['start_date'] > pd.to_datetime('20180401')]
print(len(customer_start))集計されたデータを行インデックスなしで戻す
groupby()で集計されたデータは、インデックス付されています。as_index=Falseをgroupbyに渡すことで、集計されたデータを行インデックスなしで戻すことができます。
uselog['usedate'] = pd.to_datetime(uselog['usedate'])
uselog['年月'] = uselog['usedate'].dt.strftime('%Y%m')
uselog_months = uselog.groupby(['年月', 'customer_id'], as_index=False).count()
uselog_months.head()
また、インデックス付けされた結果に対して、reset_indexメソッドを呼ぶことで、インデックスの振り直しを行うことでも、同様の結果を得ることができます。
uselog_customer = uselog_months.groupby('customer_id').agg(['mean', 'median', 'max', 'min'])['count']
uselog_customer = uselog_customer.reset_index(drop=False)
uselog_customer.head()
上記のコードの2行目で、groupbyをした影響でインデックス付けされたcustomer_id列をカラムに変更して、indexの振り直しを行っています。
今回の学びのまとめ
○データ件数は、len()で把握。
○ジョイン後は欠損値の確認を忘れずに!
○groupbyを行った後で、.count()を行うことで対象データの件数の集計が可能
○集計されたデータを行インデックスなしで戻すには、以下の2つの方法がある
①as_index=Falseをgroupbyに渡す
②reset_indexメソッドで、インデックスの振り直しを行う
サポート、本当にありがとうございます。サポートしていただいた金額は、知的サイドハッスルとして取り組んでいる、個人研究の費用に充てさせていただきますね♪