NumPy4 ビュー変更・合計、平均

NumPyの第4回目となります。
Aidemyさんの講座を受講しながらアウトプットのためにブログを更新しております。
AidemyさんHP → https:// aidemy.net
【ビュー】
あるNumPy配列を別の変数に代入すると、そのNumPy配列のビュー(view)が作られます。ビューは、もとのNumPy配列とメモリの領域を共有しており、片方に行われた変更はもう片方にも反映されます。1つのNumPy配列に、2つの名前が付いている状態と捉えることもできます。
import numpy as np
arr_1 = np.array([1, 2, 3, 4, 5])
arr_2 = arr_1
arr_2[3] = 100 # arr_2のみ値を変更する
print(arr_1)
print(arr_2)
>>> 出力結果
[ 1 2 3 100 5] #arr_1はarr_2とメモリを共有しているため100に置き換わっている
[ 1 2 3 100 5]スライスを用いて、NumPy配列の一部に対するビューを作成することも可能です。
arr_1 = np.array([1, 2, 3, 4, 5])
arr_2 = arr_1[:2]
arr_2[0] = 100 # arr_2の値を変更する
print(arr_1)
print(arr_2)
>>> 出力結果
[100 2 3 4 5]
[100 2]【コピー】
NumPy配列のコピーを作成したい場合は、copy()メソッドを使用します。次のコードでは、arr_2はarr_1を複製したものであり、メモリの領域も共有していません。そのため、片方を変更したとしてもその変更がもう片方にも反映されることはありません。
import numpy as np
arr_1 = np.array([1, 2, 3, 4, 5])
arr_2 = arr_1.copy()
arr_2[3] = 100 # arr_2のみ値を変更する
print(arr_1)
print(arr_2)
>>> 出力結果
[1 2 3 4 5] #arr_2は複製したもなのでarr_1とはメモリの共有はしていない
[ 1 2 3 100 5] #値が変更されたデータが出力【引数axis】
axisは座標軸のようなものです。
前回も同じような事例を上げましたが、
import numpy as np
a = np.arange(6).reshape((3, 2))
print(a)
print(a.shape)
>>> 出力結果
[[0 1]
[2 3]
[4 5]]
(3, 2)となりますが、axisのイメージとしては、、、

また、上記は2次元ですが、3次元にすると、、、
import numpy as np
a = np.arange(6).reshape((3, 2))
b = np.array([a, a])
print(b)
print(b.shape)
>>> 出力結果
[[[0 1]
[2 3]
[4 5]]
[[0 1]
[2 3]
[4 5]]]
(2, 3, 2)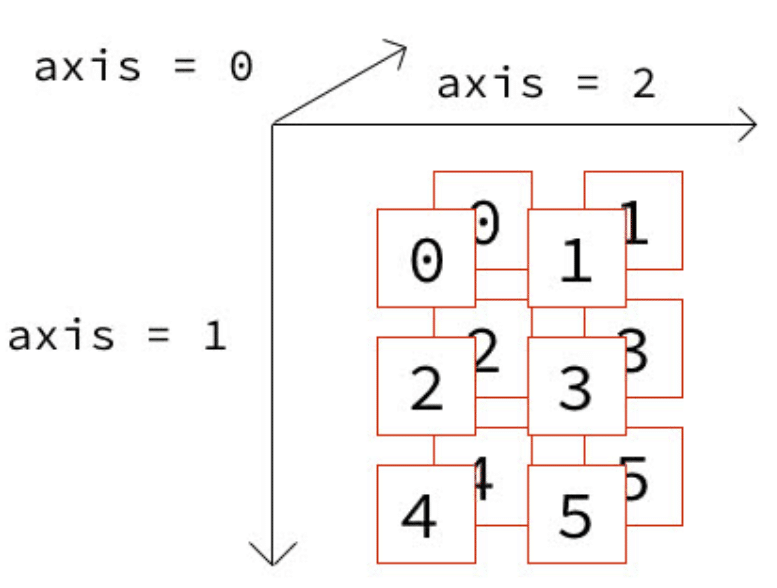
NumPy配列の統計解析用のメソッドの多くは、引数axisを使用します。
axisを指定することで、NumPy配列のどの次元に沿って計算を行うかを指定できます。
たとえば、NumPy配列要素の合計をとるsum()メソッドでは、引数axisによって合計のとり方が変わります。
import numpy as np
a = np.arange(6).reshape((3, 2))
b = np.array([a, a])
c = b.sum(axis=1)
print(c)
print(c.shape)
>>> 出力結果
[[6 9]
[6 9]]
(2, 2)出力結果の[[6 9][6 9]]については、下記の「axis=1」の
表面:「0+2+4」=6 / 「1+3+5」=9
裏面:「0+2+4」=6 / 「1+3+5」=9
を表したものとなります。

しつこい様ですが、重要ですのでもう一つイメージ図を添付します。

【合計】
NumPy配列の要素の合計値は、sum()メソッドを用いて求められます。
import numpy as np
list_1 = [1,3,5,7,9,2,4,6,8,10,11,13,15,17,19]
arr_1 = np.array(list_1)
# arr_1の合計値を求める
print(arr_1.sum())
>>> 出力結果
130【平均】
NumPy配列の要素の平均値は、mean()メソッドを用いて求められます。
import numpy as np
list_1 = [1,3,5,7,9,2,4,6,8,10,11,13,15,17,19]
arr_1 = np.array(list_1)
# arr_1の平均値を求める
print(arr_1.mean())
>>> 出力結果
8.6666666666666662次元以上の配列の場合は、引数axisを指定することでどの軸に沿って平均値を求めるかを変更できます。
【分散】
NumPy配列の要素の分散は、var()メソッドを用いて求められます。
import numpy as np
# ./4002_new_numpy/csv_example.csvを読み込む
arr_1 = np.loadtxt("./4002_new_numpy/csv_example.csv",
delimiter=",", # カンマ区切りであることを明示
skiprows=1, # 最初の1行を無視
usecols=[1, 2]) # 2列目と3列目を使用
print('axis指定なしの場合')
print(arr_1.var()) # axisを指定せずにarr_1の平均を求める
print('\naxis=0の場合')
print(arr_1.var(axis=0)) # axis=0としてarr_1の平均を求める
print('\naxis=1の場合')
print(arr_1.var(axis=1)) # axis=1としてarr_1の平均を求める
>>> 出力結果
axis指定なしの場合
2639.359375
axis=0の場合
[117.5 136.1875]
axis=1の場合
[3192.25 2209. 1722.25 3080.25]【最大値・最小値】
NumPy配列の要素の最大値・最小値は、それぞれmax()メソッドとmin()メソッドを用いて求められます。
import numpy as np
# ./4002_new_numpy/csv_example.csvを読み込む
arr_1 = np.loadtxt("./4002_new_numpy/csv_example.csv",
delimiter=",", # カンマ区切りであることを明示
skiprows=1, # 最初の1行を無視
usecols=[1, 2]) # 2列目と3列目を使用
print('axis=0の場合の最大値')
print(arr_1.max(axis=0)) # axis=0としてarr_1の最大値を求める
print('\naxis=0の場合の最小値')
print(arr_1.min(axis=0)) # axis=0としてarr_1の最小値を求める
>>> 出力結果
axis=0の場合の最大値
[180. 86.]
axis=0の場合の最小値
[151. 54.]最大値・最小値については、Python標準のmax()関数やmin()関数を用いて求める方法もあります。しかしこれらのPython標準の関数は、多次元のNumPy配列に対して用いることができません。原則として、NumPy配列にはNumPyの関数・メソッドを使いましょう。
【最大値・最小値のインデックス】
NumPy配列のargmax()メソッド・argmin()メソッドを使うと、それぞれ配列の最大値・最小値のインデックスを取得できます。これまでに習ったメソッドと同様に、引数axisにより軸の指定ができます。
import numpy as np
with open("./4002_new_numpy/weather_tokyo.csv", encoding="shift_jis") as f_in:
arr_1 = np.loadtxt(f_in,
delimiter=",",
skiprows=5,
usecols=[1, 2, 3, 4])
# 気温が最高だった日が何行目かを取得
max_temp_index = arr_1.argmax(axis=0)[0]
# 気温が最高だった日の行数を出力
print(max_temp_index)
# 気温が最高だった日の行全体を出力
print(arr_1[max_temp_index])
>>> 出力結果
203
[32.2 0. 1. 2.9]【ソートされたインデックスを取得】
NumPy配列のargsort()メソッドを用いると、配列の要素を小さい順に並べ替えたときのインデックスを取得できます。
import numpy as np
with open("./4002_new_numpy/weather_tokyo.csv", encoding="shift_jis") as f_in:
arr_1 = np.loadtxt(f_in,
delimiter=",",
skiprows=5,
usecols=[1, 2, 3, 4])
# arr_1の0列目の値をソートしたときの、インデックスを返す
sorted_temp_index = arr_1[:, 0].argsort()
print('気温の低い順に並んだインデックス')
print(sorted_temp_index[:10])
print('\n気温の低い順に10行分参照')
print(arr_1[sorted_temp_index[:10]])
>>> 出力結果
気温の低い順に並んだインデックス
[24 25 27 21 32 23 26 52 11 12]
気温の低い順に10行分参照
[[ 0. 0. 1. 2.9]
[ 0.5 0. 1. 3.8]
[ 1.7 0. 0. 1.9]
[ 1.7 24. 0. 3. ]
[ 1.9 6. 0. 2.4]
[ 2.2 0. 1. 3.3]
[ 2.6 0. 1. 4.3]
[ 2.7 2. 0. 2.8]
[ 2.7 0. 1. 2. ]
[ 2.7 0. 1. 2.3]]コード中のarr_1[:, 0]では、スライスを用いてarr_1の0列目の要素を抽出しています。抽出された1次元の配列に対し、argsort()メソッドを使っています。
arr_1のうち、24行目が最も0列目の値が小さく、25, 27, 21行目と、順に値が大きくなっていることを示しています。sort()メソッドはin-place処理で、元のNumPy配列自体を変更してしまいますが、argsort()メソッドは元の配列を変更しません。
今回はこれで以上とさせていただきます。
お読みいただきましてありがとうございました。
この記事が気に入ったらサポートをしてみませんか?