
教師なし学習による異常音検知~AutoEncoder色々~

「ToyADMOS:異常音検知」手法比較:CNN と AutoEncoderの続きです。
背景
CNN(教師あり学習)とAutoEncoder(教師なし学習)を比較した場合、f1-score、Recall(再現率)・Precision(適合率)・学習時間において、CNNがAutoEncoderよりも優れている結果となりました。一方で、異常検知というタスクでは、未知の異常モードが存在するため教師なし学習の方が望ましいです。そのため、教師なし学習AutoEncoderの複数のモデルや前処理手法などについて検証・考察していきます。
目的
教師なし学習であるAutoEncoderの前回の課題3点について評価します。
1点目:周波数領域波形を利用しており時間成分が欠落している
2点目:閾値を正常データの再構成誤差の平均+2σ と一意に決めている
3点目:サンプリング周波数が48kHzと高く、データ点数が多い(処理時間が遅い)
そこで、
1.1D/2D AutoEncoderモデルによる違い
2.閾値最適化方法
3.サンプリング周波数の影響
について検討しました。
やったこと
AutoEncoderの比較(時間周波数領域画像の利用)
1D AutoEncoder(1D-AE)
2D Deep Autoencoder(Deep-AE)
2D Convolutional Autoencoder(Conv-AE)
閾値決定方法の比較
再構成誤差の平均+2σ
ROCカーブより決定
Audioデータのリサンプリングの影響確認
リサンプリングなし
サンプリング周波数変更:48[kHz] -> 16[kHz]
結論
総合的にみると、
・1D AutoEncoder(1D-AE)
・閾値 : ROCカーブから決定
・ダウンサンプリング(48kHz ⇒ 16kHz)
の組合せが、f1-score・recallのスコアがよく、学習速度も速く、データセット依存性も小さくなり、総合的に優れている結果となりました。
検証モデル
今回比較した3つのモデルを説明します。
1.1D-AutoEncoder(1D-AE)

autoencoder = tf.keras.Sequential([
layers.Dense(528, activation="relu"),
layers.Dense(128, activation="relu"),
layers.Dense(64, activation="relu", name = 'encoder'),
layers.Dense(128, activation="relu"),
layers.Dense(528, activation="relu"),
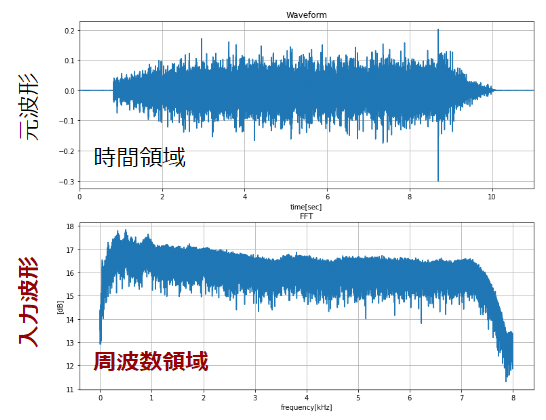
layers.Dense(input_shape, activation="sigmoid")]) # 出力は(0,1)入力は、FFT変換した周波数波形(dB換算)になります。以下に入力画像を図示します。
2.2D-DeepAutoEncoder(Deep-AE)
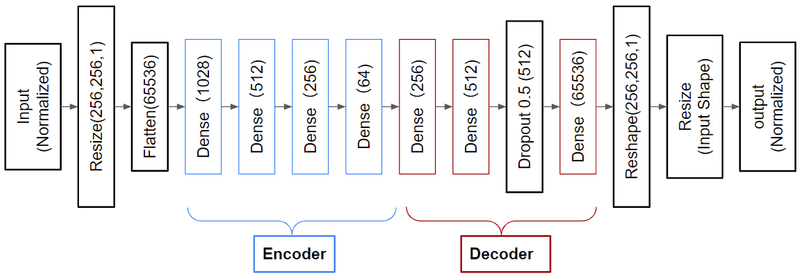
model = models.Sequential([
layers.Input(shape=input_shape),
layers.Resizing(256, 256), # 256, 256
#layers .Dropout(0.5),
layers.Flatten(),
layers.Dense(32*32, activation="relu"), # 1024: 32*32 **
layers.Dense(512, activation="relu"),
layers.Dense(256, activation="relu"),
layers.Dense(64, activation="relu", name = 'encoder'),
layers.Dense(256, activation="relu"),
layers.Dense(512, activation="relu"),
layers.Dropout(0.5),
layers.Dense(256 * 256, activation="sigmoid"), # 1024: 256 * 256
layers.Reshape((256, 256, 1)),
# Supports "bilinear", "nearest", "bicubic", "area", "lanczos3", "lanczos5", "gaussian", "mitchellcubic".
layers.Resizing(input_shape[0],input_shape[1]), # input_shape[0],input_shape[1] , interpolation='nearest'
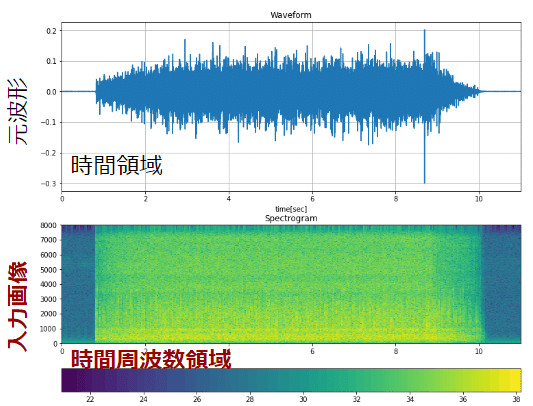
])入力は、STFT変換した時間周波数画像になります。以下に入力画像を図示します。
3.2D Convolutional Autoencoder(Conv-AE)

model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(128, 128), # (64, 64) (129,129)
layers.Conv2D(32, 3, padding='same', activation='relu'), # 32
layers.MaxPooling2D((2, 2), padding='same'),
layers.Conv2D(16, 3, padding='same',activation='relu'), # 16
layers.MaxPooling2D((2, 2), padding='same'),
layers.Conv2D(8, 3, padding='same',activation='relu'),
#layers .Conv2D(128, 3, padding='same',activation='relu'),
layers.MaxPooling2D((2, 2), padding='same', name='encoder'),
layers.Conv2DTranspose(8, (3, 3), padding='same',activation='relu'),
layers.UpSampling2D((2, 2)), #(6,6)
layers.Conv2DTranspose(16, (3, 3), padding='same',activation='relu'), # 16
layers.UpSampling2D((2, 2)),
layers.Conv2DTranspose(32, (3, 3), padding='same',activation='relu'), # 32 , strides=(2, 2)
layers.UpSampling2D((2, 2)),
layers.Conv2DTranspose(1, (3, 3), padding='same',activation='sigmoid'),
# Supports "bilinear", "nearest", "bicubic", "area", "lanczos3", "lanczos5", "gaussian", "mitchellcubic".
layers.Resizing(input_shape[0], input_shape[1], interpolation='nearest') #
])入力は、STFT変換した時間周波数画像になります。以下に入力波形を図示します。
考察
1.AutoEncoderの比較(時間周波数領域画像の利用)
f1-score/recallが最良なモデルは1D-AEでした。今回の信号は、定速回転のため時間的な周波数の変動が小さく、単純な周波数信号で良好な結果を得る事ができました。時間周波数画像を利用した2D-AE(特に、Conv-AE)では、元画像の再現性(正常分布の特徴抽出)に問題があり、1D-AEに及びませんでした。Encoder-Decoder部の改良が必要です。
2.リサンプリングの影響
16kHzにダウンサンプリングすると、f1-score・recallが改善、学習時間が48kHzの0.16~0.6倍ほどに削減されました。f1-score・recallの改善について、異常音の周波数成分が8kHz以下と比較的低周波だったためと考えられます。学習時間の削減効果については、入力データサイズが1D-AEでは1/2に2D-AEでは1/10になるためだと考えられます。適切に前処理を行う必要性を再認識しました。
3.閾値決定方法の比較
閾値については、閾値を再構成誤差の平均値+2σで一意に決めるのは、再構成誤差が正規分布ではない(多峰、裾引き等)場合に、閾値が大きくなりすぎる(異常を正常と誤判定する)などの問題がありました。ROCカーブでYouden’s indexにより、これらの問題点を考慮した最適な閾値を設定でき、f1-score/recallが改善しました。ROCカーブを使うメリットを再認識しました。
では、結果について確認していましょう。
結果
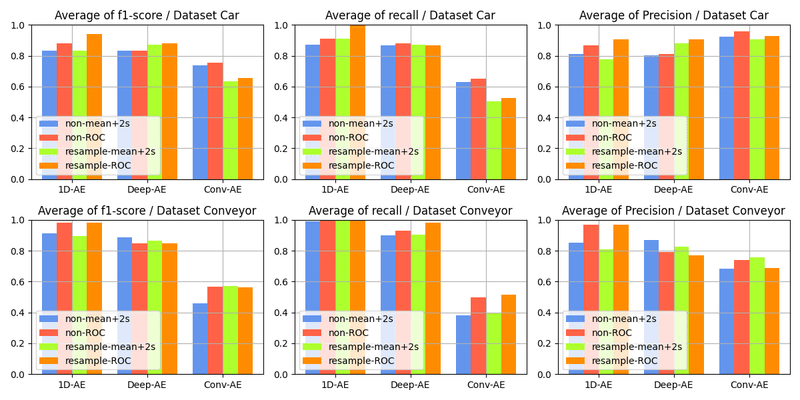
・f1-score/recall/Precision比較
今回は、f1-score/recallの最大化を目指します。
まずは、CarとConveyorの各caseのスコアを平均し、大まかな傾向を確認します。
Car:4種(case1, case2, case3, case4)の平均
Conveyor:3種(case1, case2, case3)の平均
・Dataset毎の平均(大まかな傾向確認)
f1-score:1D-AE > Deep-Ae >>>> Conv-AE
閾値 :ROCカーブで閾値を算出すればf1-score/recallが向上。
リサンプリング:ダウンサンプリング(48kHz ⇒ 16kHz)の副作用はみられず、ROCカーブによる閾値決定と組合わせる事でベストスコアとなりました。異常音の周波数成分が8kHz以下と比較的低周波だったと考えられます。
・ヒートマップ(Dataset・case別)
car・conveyorの各caseでf1-score/recall/Precisionを確認しました。先述した傾向と同様な結果となっていることがわかります。


・再構成画像比較(Deep-AE、Conv-AE)
・Deep-AE
正常分布の特徴をある程度抽出ができており、再構成画像から正常(OK)・異常(NG)を大まかに判別できました。再構成画像の解像度をもう少し高められれば、f1-score/recallの更なる改善が見込めると思われます。

・Convolutional-AE
Deep-AEに比べて正常分布の特徴抽出ができておらず、正常(OK)・異常(NG)の判別が難しかったようです。encoder-decoder部の構成を再検討する予定です。

・学習時間
ダウンサンプリングすることで、学習時間が元波形の0.16~0.6倍ほどに削減されました。
Deep-AEで学習時間の削減効果が大きいです。これは、Deep-AEへ入力する画像サイズが(936, 936)⇒(311, 311)と約10分の1に小さくなり、loss関数の計算コストが小さくなったため(?)と思われます。


・リサンプリング:入力信号比較
48kHz から 16kHz へとダウンサンプリングした時の各波形・画像を比較します。下図は、上から時間領域、周波数領域(FFT)、時間周波数領域(STFT)を示しています。ここで、FFTは1D-AEの入力、STFTは2D-AEの入力です。
48kHz から 16kHz へダウンサンプリングしたため、ナイキスト周波数は24kHz から 8 kHz になります。16kHz にダウンサンプリングすると、8kHz以上の周波数領域が切り捨てられることが分かります。
16kHz にダウンサンプリングするとf1-score・recallが改善しました。今回の異常音の周波数成分は8kHz以下の比較的低周波だったと考えられます。前処理が重要ですね。

今回、reampyライブラリのresampleでサンプリング周波数を変更しました。
import resampy
# resampling original -> rate_out
def resampling_audio(audio):
audio = resampy.resample(
audio, sampling_rate.numpy(), rate_out, name=None
) # tf.reshape(audio,[-1])
audio = tf.reshape(audio, [audio.shape[0], 1]) # MapDataset で numpyの計算
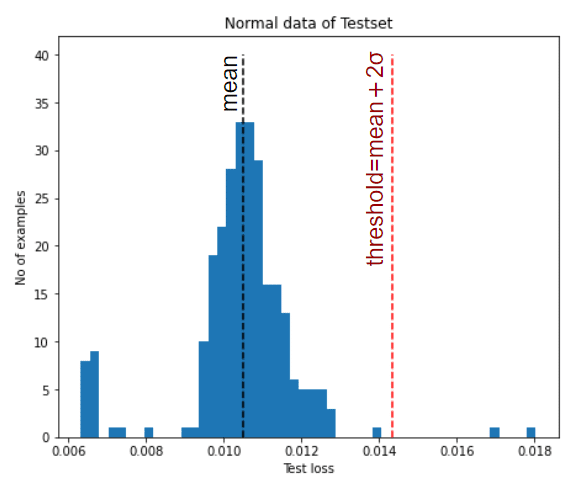
return tf.squeeze(audio, axis=-1) # モノラル信号のため、チャンネル軸を除去閾値決定手法
1.再構成誤差の平均+2σ
正常データの再構成誤差の平均値+2σ(赤破線)を閾値とし、閾値以上のlossを異常と判定します。正規分布ではない場合(多峰分布や裾が長い分布)、適切な閾値を設定できず誤判定が発生します。(閾値が大きくなりすぎて、異常を正常と誤判定するなど)
2.ROCカーブによる決定
ROCカーブを作成し、Youden’s indexの考えに基づき、閾値を決定しました。argmax(TRP-FRP)となるThresholdを閾値に選択しました。下記の図であれば、☆印の部分です。

(2D_DeepAutoEncoder, 16kHz, conveyor-case2、AUC:0.98、
f1-score:0.86、recall:0.96、Presicion:0.78)
Youden’s indexは感度も特異度も高いほうがいいと考えて、(感度+特異度)が最大になる点を最適点と定義する方法です。
具体的には、最も検査の有効性が低いROC曲線、すなわちAUC = 0.5となる45度の線から最も離れたポイントをカットオフ値にすればいいということ。
45度の線から縦軸方向の距離を計算すると(感度+特異度-1)となりますが、これが最大値となるポイントをカットオフ値にしてしまえばいい。
今後
ノイズに対するロバスト性をCNN・AutoEncoderで比較したいと思います。
その後、GANを用いた異常検知手法にトライしていきます。
この記事が気に入ったらサポートをしてみませんか?