[Stataによるデータ分析入門]Stataの文字化け対策:日本語・中国語のデータ読み込み

Stata14から多言語対応となりました。日本語や中国語のCSV等のテキストファイルを読み込む際には、
import delimited using hogehoge.csv, encoding(shift_jis)のようにencodeオプションで文字コードを指定することで読み込みが可能です。日本語を含むファイルで文字化けするのは、Shift-JISという文字コードのファイルをStataが異なる文字コードで読み込んでしまった場合なので、””Shift-JIS”を指定すれば文字化けが解消することが多いです。
一方で、中国語や韓国語、さらには良く知らない言語が含まれたファイルの場合、どんな文字コードを指定すればいいのか見当もつきません。文字コードが不明な場合は、次のようにファイルを開くと適切な文字コードを確認することができます。
1)メニューバーより
<ファイル>→<インポート>→<テキストデータ(デリミタ、.csv等)
すると、「デリミタテキストデータをインポートする」というウインドウが現れる。

2)ファイルを指定し、「テキストのエンコード」から文字コードを変更していくと文字化けしない文字コードを探すことができます。下図の例では、当初「西ヨーロッパ言語」が指定さえていますが、変数名が文字化けしています。
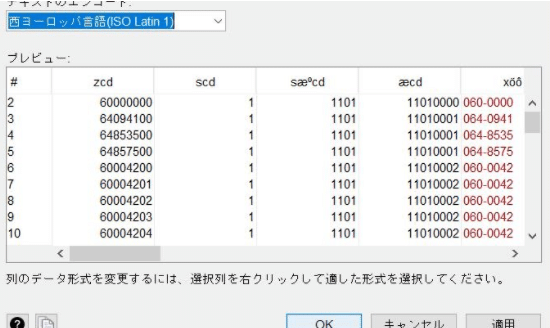
「テキストのエンコード」をいろいろ変えてみると、「日本語(Shift JIS)」を選ぶと文字化けが解消されることが確認できたので、このファイルを開く際にはShift JISを指定してファイルを開けばよいことがわかります(下図参照)。

※本記事はStataによるデータ分析入門第3版のWeb Appendixです。
Stataによるデータ分析入門第3版のWEB補論の一覧はこちら。
この記事が気に入ったらサポートをしてみませんか?