
[Rによるデータ分析入門]msummaryとetableによる結果出力(1)

本コラムはRによるデータ分析入門のWEBサポートとして作成されています。
このコラムではRの回帰分析結果出力のための関数、msummary()関数とetable()関数のオプションを操作することで、どのように表が変わってくるかについて説明します。なお、etable()関数についてはmsummaryとetableによる結果出力(2)で紹介します。
なお(2)は以下からアクセスできます。
msummary()関数とetable()関数とは
Rでは推計結果を綺麗な表にまとめる関数が用意されており、lm()関数やglm()関数による推計結果をまとめる際に使われるのがmsummary()、fixestパッケージに含まれるfeolsの結果をまとめる際に使われるのがetable()です。
msummaryの下準備
ここでは藤沢市湘南台駅最寄りの賃貸物件のデータ(rent-shonandai96-04.csv)を用いて、賃貸料を被説明変数する回帰分析する例を考えます。データとスクリプト例は以下からダウンロードできます。
なお、スクリプトを走らせる前にmodelsummaryをインストールしておく必要があります。
早速スクリプト例を説明していきます。library(modelsummary)でパッケージを呼び出したのち、ここでは3つの回帰モデルを推定し、これをlist()関数でregsというオブジェクトに格納しておきます。
regs <-
list(
"model1" =lm(rent_total~floor,data=dataf),
"model2" =lm(rent_total~floor+age,data=dataf),
"model3" =lm(rent_total~floor+age+walk,data=dataf)
)msummary: オプション無し
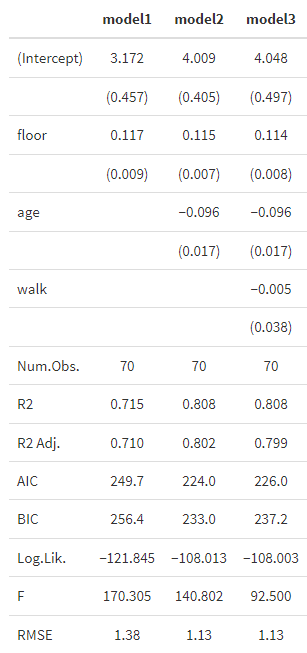
オプション無し、すなわち、msummary(regs)で実行してみましょう。
msummary(regs)結果は”Viewer”のところに表示されます。係数の下のカッコ内は標準誤差、係数の下にたくさんの統計量が表示されます。
msummary: 有意水準を示す星をつける
係数と標準誤差だけでは、どの変数が統計的に有意かを見る際に、自分でt値=係数/標準誤差を計算する必要があるので少々不便です。そこで、有意水準に基づいて*を付けてみましょう。*をつけるにはstars=TRUEというオプションを付けます。
msummary(regs, stars=TRUE)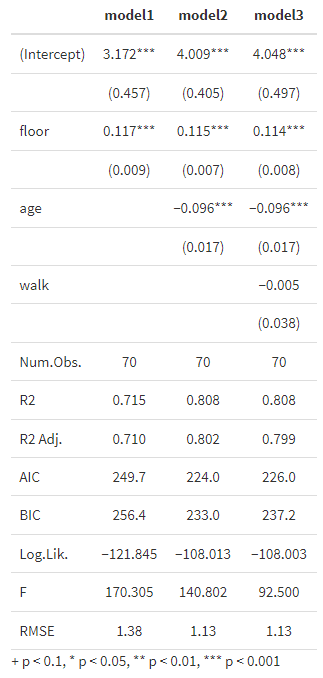
この場合、P値が0.1%未満で*、1%未満で**、5%未満で*、10%未満で+が表示されます。これでも問題ないのですが、経済学の論文では、1%未満で***、5%未満で**、10%未満で*、という表記が多いので少しカスタマイズしてみましょう。stars=のところを以下のように変更すると、*をつけるルールを変更できます。
msummary(regs, stars = c("*" = .1, "**" = .05, "***" = .01))msummary: 表示させる統計量を限定する
通常の線形の回帰分析の結果を示す際は、サンプル数(Num.Obs.)と、決定係数、自由度調整済み決定係数が示されれば十分です。これら以外の指標で表示されるのは、RMSEは二乗平均平方根誤差、AICは赤池の情報量基準、BICはベイズ情報量基準、Log.Likは対数尤度、FはF値です。これらを表示させないためのオプションがgof_omitで、直後の=以後の統計量を省略せよという意味です。たとえば、gof_omit='RMSE|AIC|BIC|Log.Lik.|F'とかくと、RMSEからF値までが表示されません。F値は残しておきたい、という場合は、gof_omit='RMSE|AIC|BIC|Log.Lik.'のようにFを外しておきます。サンプル数、決定係数、F値を表示させた結果を以下に示しておきます。
msummary(regs, stars= c("" = .1, "" = .05, "" = .01) , gof_omit='RMSE|AIC|BIC|Log.Lik.')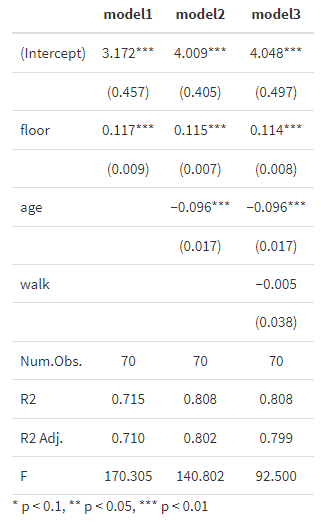
msummary: 小数点以下の桁数を変える
デフォルトでは小数点以下3桁まで表示されますが、4桁まで表示させてみましょう。fmt='%.4f'というオプションをつけます。ここで”.4”が小数点以下4桁を意味します。以下がその例です。
msummary(regs, stars=TRUE ,fmt='%.4f', gof_omit='RMSE|AIC|BIC|Log.Lik.|F')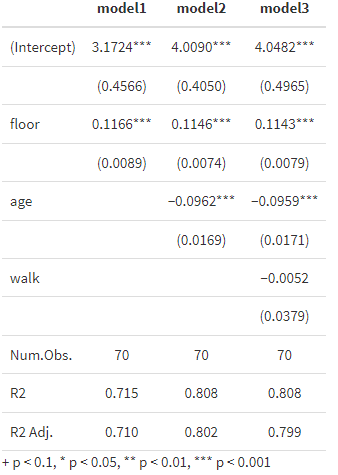
msummaryの結果をEXCELに出力
結果表をEXECELに出力するには、'data.frame'オプションをつけてmsummaryの結果を適当なオブジェクトに入れます(以下の例ではresult_tabというオブジェクトに格納)。そして、openxlsxパッケージ(要事前インストール)に含まれるwrite.xlsx()関数でファイルに出力します。write.csv()関数でも出力可能ですが、CSVファイルに出力するとカッコ付の数値がマイナスと認識されてしまうので標準誤差がすべて負の値になり修復が大変なのでwrite.xlsx()の利用をお勧めします。
results_tab <- msummary(regs, gof_omit='RMSE|AIC|BIC|Log.Lik.|F', 'data.frame')
openxlsx::write.xlsx(results_tab, 'results.xlsx')番外編:lm()関数の結果を直接CSV出力する
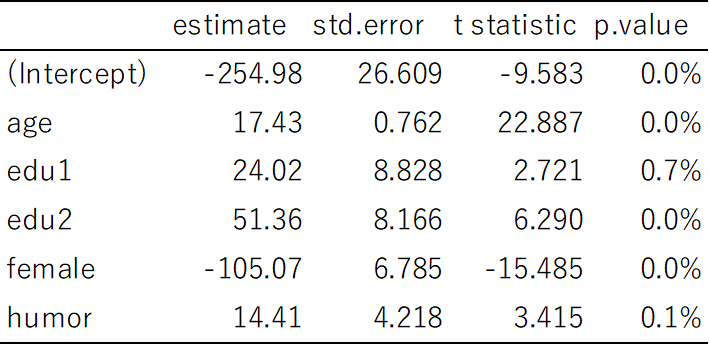
回帰分析の結果を1つだけ出力したいとき、標準誤差やt値を係数の右隣に配置したいときは推計結果をwrite.csv()で出力するのですが、ひと手間加える必要があります。
まず、broomパッケージをインストールしてlibary(broom)で呼び出しておく必要があります。そして、
1. lm()関数の結果をmodel4に格納し、
2. broom::tidy()で形を整えてwrie.csv()で出力
します。
library(broom)
model4 <- lm(rent_total~floor+age+dist,data=dataf)
broom::tidy(model4) %>% write.csv("regout.csv")このCSVファイルを開くと次のような表が得られます。
[Rによるデータ分析入門]msummaryとetableによる結果出力(2)では、etable()の使い方について説明します。
本コラムは「Rによるデータ分析入門」のWEBサポートページとして作成されました。WEBサポートの一覧は以下を参照してください。
WEBサポートの一覧は以下を参照してください。