一枚の画像を読み込み、NSFW/SFWかどうか、版権キャラクターの可能性があるか判定するスクリプト

需要あるかなと思って書いたら結構反響あったのでメモ。
まずこれを動かす環境作り。
誰のPCでも動くようにCPU版にします
python -m venv venv
venv\Scripts\activate
pip install opencv-python-headless numpy pillow onnxruntime huggingface-hub以下のスクリプトを作成
ContentSafetyAnalyzer.py
import csv
import os
from pathlib import Path
import cv2
import numpy as np
from PIL import Image
import onnxruntime as ort
from huggingface_hub import hf_hub_download
# 画像のサイズ設定
IMAGE_SIZE = 448
def preprocess_image(image):
image = np.array(image)
image = image[:, :, ::-1] # BGRからRGBへ変換
# 画像を正方形にするためのパディングを追加
size = max(image.shape[0:2])
pad_x = size - image.shape[1]
pad_y = size - image.shape[0]
pad_l = pad_x // 2
pad_t = pad_y // 2
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode="constant", constant_values=255)
# サイズに合わせた補間方法を選択
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
image = image.astype(np.float32)
return image
def process_image(image_path, input_name, ort_sess, rating_tags, character_tags, general_tags, thresh):
try:
image = Image.open(image_path)
image = image.convert("RGB") if image.mode != "RGB" else image
image = preprocess_image(image)
except Exception as e:
print(f"画像を読み込めません: {image_path}, エラー: {e}")
return
img = np.array([image])
prob = ort_sess.run(None, {input_name: img})[0][0] # ONNXモデルからの出力
# NSFW/SFW判定
tag_confidences = {tag: prob[i] for i, tag in enumerate(rating_tags)}
max_nsfw_score = max(tag_confidences.get("questionable", 0), tag_confidences.get("explicit", 0))
max_sfw_score = tag_confidences.get("general", 0)
if max_nsfw_score > max_sfw_score:
print("NSFWの可能性が高いです")
else:
print("SFWの可能性が高いです")
# 版権キャラクターの可能性を評価
character_tags_with_probs = []
for i, p in enumerate(prob[4:]):
if p >= thresh and i >= len(general_tags):
tag_index = i - len(general_tags)
if tag_index < len(character_tags):
tag_name = character_tags[tag_index]
prob_percent = round(p * 100, 2) # 確率をパーセンテージに変換
character_tags_with_probs.append((tag_name, f"{prob_percent}%"))
if character_tags_with_probs:
print(f"版権キャラクター: {character_tags_with_probs}の可能性があります")
else:
print("版権キャラクターの可能性が低いと思われます")
def main(MODEL_ID, image_path, thresh):
print("Hugging Faceからモデルをダウンロード中")
onnx_path = hf_hub_download(MODEL_ID, "model.onnx")
csv_path = hf_hub_download(MODEL_ID, "selected_tags.csv")
print("ONNXモデルを実行中")
print(f"ONNXモデルのパス: {onnx_path}")
ort_sess = ort.InferenceSession(onnx_path)
with open(csv_path, "r", encoding="utf-8") as f:
reader = csv.reader(f)
header = next(reader)
rows = list(reader)
assert header == ["tag_id", "name", "category", "count"], f"CSVフォーマットが期待と異なります: {header}"
rating_tags = [row[1] for row in rows if row[2] == "9"]
character_tags = [row[1] for row in rows if row[2] == "4"]
general_tags = [row[1] for row in rows[1:] if row[2] == "0"]
process_image(image_path, ort_sess.get_inputs()[0].name, ort_sess, rating_tags, character_tags, general_tags, thresh)
print("処理完了!")
if __name__ == "__main__":
MODEL_ID = "SmilingWolf/wd-vit-tagger-v3"
image_path = "E:/desktop/test.jpg" # 画像のパス
thresh = 0.35 # 閾値の設定
main(MODEL_ID, image_path, thresh)
実行する
python ContentSafetyAnalyzer.py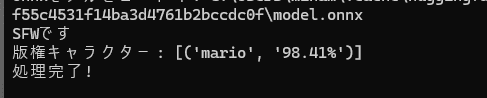
この記事が気に入ったらサポートをしてみませんか?