
お絵描き補助AIアプリ『AI-AssistantV3』公開!

【更新履歴】
2024/06/12
fanbox支援者様のみに先行公開
公開先URL:
2024/06/15
全体公開
公開先URL:https://drive.google.com/file/d/1YmS8qlmvThjn-ZMXEm2QTwOC0pPcX7Gq/view?usp=sharing
予備URL:https://drive.google.com/file/d/1YmS8qlmvThjn-ZMXEm2QTwOC0pPcX7Gq/view?usp=drive_link
2024/06/22
出力画像サイズが小さくなるバグ対応
【はじめに】

「AI-Assistant」は、デジタルお絵描きの作画補助に特化したAIアプリです。カラーイラストから線画を抽出したり、線画を疑似3D画像にしてライティングしたりすることができます。
今回のバージョン3ではUIを変更・最適化するとともに、「①i2iタブの機能向上(anytest v3&v4を採用)」「②”色見本”タブの搭載」「③”アニメ影”に3種類目を導入」という3つの新機能を搭載しました。
今まではexeファイルを起動するとグレーの専用画面が出てくる形式でしたが、V3からはブラウザ上で起動するようになりました。より多くの人にAIアプリに触れてもらうため、どんなスペックのPCやスマホでも、ブラウザから動かせるwebアプリにしていくことを目指しています。
なお今回のバージョンも無料かつ商用利用OKです!ただ開発には無限にお金がかかるので、カンパや応援は大歓迎!この記事をXでリポストしてくれるだけでも大助かりです。
【V2までの標準機能】
新機能について触れる前に、「V2」の時点でできていたことをおさらいします。
・image2image(i2i):入力した画像をなんかいい感じにAIが描き直す。

・線画化:入力した画像を線画にする。ラフでもカラーのAI絵でも線画化することができ、AIの干渉度(入力画像からどれくらい線を変更してよいか)を調整することも可能です。

・線画入り抜き:太さが平坦な線画を入り抜きのあるいい感じの線画に描き直してくれる。線の太さの調整も可能。

ノーマルマップ化:線画を入力すると疑似3D画像化できる。次の「ライティング」の下準備に使う

ライティング:疑似3D画像をもとに陰影を作る。このままで使ってもよいし、「アニメ影」に変換することもできる。

アニメ影化:ライティングした画像をアニメ影風に変換する。グリザイユ塗りがお手軽にできます。

リサイズ:画像を最大長辺2880までにリサイズします。モノクロリサイズが得意でカラーは若干色味変わるかも。長辺2048位がちょうどいいです。

【V3で進化したポイント】
①i2iタブにanytestを導入
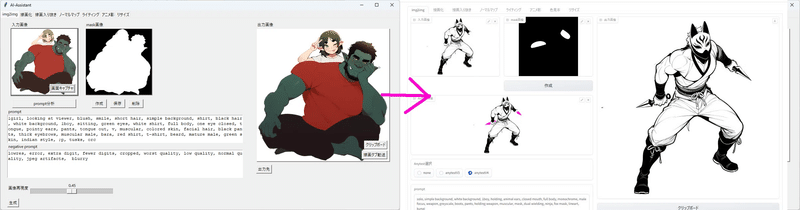
月須和・那々さん制作の汎用Controlnet「anytest v3&v4」をi2iタブに採用したことで、より高度な編集ができるようになりました。
例えば、AIで雑にムチムチマッスル仮面忍者を生成すると、武器があらぬ場所から生えてきてしまうことってよくあるじゃないですか?

こういう時にanytestを使うと・・・

なんかこうなります。anytest_v3とanytest_v4は、シルエットをなんとなく読み取って、こちらの意図通りに補完する力が強いんですよね。。ちなみにanytest_v3の方が元画像に忠実で、anytest_v4の方が自由度が高い特徴があるので、用途によって使い分けてください。
②色見本タブ追加
V2まではできなかった線画への着色機能です。白黒の線画を入力すると、線をできるだけずらさないようにしながら、プロンプトに従ってさまざまな「色見本」を出力できるようになりました!
どうせなので先ほどのニンジャを例に使いましょう。

promptを分析して、末尾に『, sleeveless, exposed bare arms, black kimono, red mask, white bandages』と追加すると。

こんな感じの色見本が出力されます。線画と重ねるとこんな感じ。


「線画を自動でバケツ塗りしてくれるツール」というのには若干惜しい感じですが、色見本程度には使えるかなと思います。いや、バケツで塗って色相や濃度や明暗いじって調整した方が早くない?と内なる私がささやきますが
③アニメ影タブに新しいパターンを追加
今までの影(anime01、anime02)に比べて薄めの影(anime03)も用意しました。好みで使い分けて下さい。


【必要スペック】
簡単に言うと、ある程度高性能なグラフィックボードが搭載されたPCじゃないと動きません。
PCに詳しい方向けに言えば「CUDAに対応したRTX〇〇系のVRAM12GB以上推奨」となりますが、「PCにグラフィックボードが搭載されているかどうか分からない」「自分のPCで動くか自信がない」という方はこちらのアプリで判定してみてください。
【インストール方法】
ユーザーは、このソフトウェアを適切に利用し、法的な規制や他人の権利を侵害しないように注意する必要があります。ソフト開発者は、ユーザーがソフトウェアを適切に使用することに関して責任を負いません。
基本的には『手書きでやってはいけないことはAIでもやってはいけない』というルールで運用してください。
①zipファイルをDLし適当な場所に解凍する
クソデカファイルです。
『パスが長すぎて解凍できません』的なエラーが出るときはWindows標準の解凍機能ではなく7-zipというアプリを使って解凍してください
AI_Assistant_V3\AI_Assistantのようにファイルが展開されるので
AI_Assistantフォルダを適当な場所に配置してください。
②セキュリティーソフトの設定で、フォルダと実行ファイル名を除外リストに追加する
例:Windows Defenderの場合、Windows セキュリティ→ウイルスと脅威の防止→ウイルスと脅威の防止の設定→設定の管理→除外
AI_Assistant.exe(プロセス)
E:\Documents\Freesoft\AI_Assistant(フォルダ)
のように指定する。
③各種モデルDL
AI_Assistant.exeを実行の前にに『AI_Assistant_model_DL.cmd』を右クリックして管理者権限で実行して下さい。必要なモデルがDLされます。
失敗する場合はブラウザから以下を手動でDLして下さい。
models/tagger
models/Lora
models/Lora
models/Lora
models/Lora
models/Lora
models/Lora
models/Lora
models/ControlNet
models/ControlNet
models/ControlNet
models/ControlNet
models/ControlNet
models/ControlNet
models/Stable-diffusion
④AI_Assistant.exeを実行
exeファイルをそのままダブルクリックで起動できます。
VRAMが6GB以下の場合
AI_Assistant_lowVRAM.batから実行した方が動作が早いかもしれません(未検証。誰か報告して)
LoRAを使いたい場合
AI_Assistant_exUI.batから実行。
※上級者向け
オプションとして、以下の引数を指定することで、起動時の言語を指定できます。ショートカットやbatファイルをご利用下さい。
AI_Assistant.exe --lang=jp
AI_Assistant.exe --lang=en
AI_Assistant.exe --lang=zh_CNさらに引数を追加することで、Stable Diffusion Web UIに対するオプションを追加できます。
また、以下の引数を追加することで拡張UIを表示できます(現在、i2iタブでLoRAを読み込めるようになりました)
--exuiデフォルトではこのように指定されています。
AI_Assistant.exe --lang=ja --nowebui --xformers --skip-python-version-check --skip-torch-cuda-test --skip-torch-cuda-test【使い方】
image2imageタブ
AIに画像を読み込ませて、それをベースに生成させる機能を持つタブです。
どシンプルですがAnytestで面白い応用ができるようになりました。
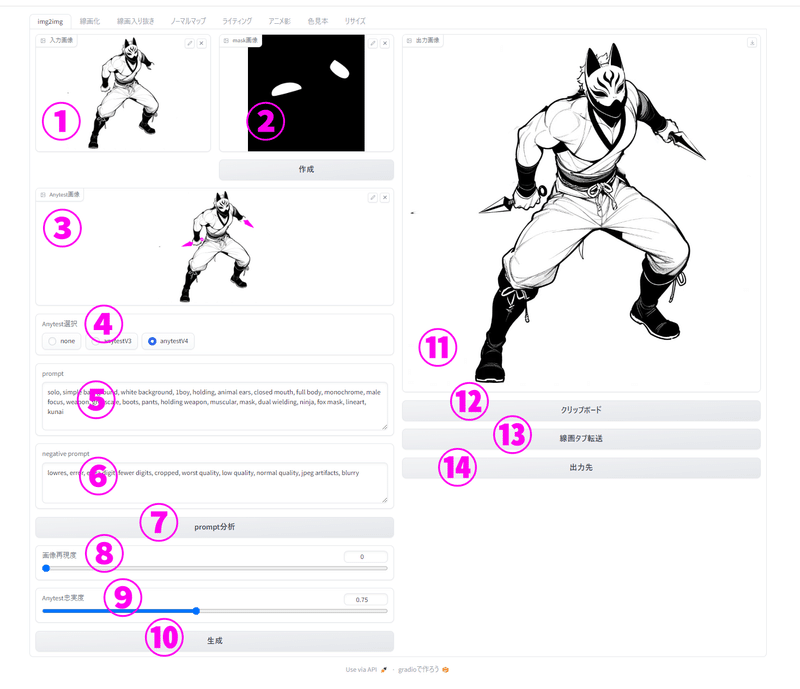
①入力画像:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。(キャプチャ機能は廃止されました。すまねぇ)
②マスク画像:生成したい範囲を白色で指定する。黒色は元画像から変化させない。入力必須ではないので空欄でもよい。
『作成』ボタンで自動生成(失敗することもあるので、その時は手動で手直しすること)
③Anytest画像:Anytest用の画像を入力する。使わないなら空欄でもよい。
Anytestは画像のシルエットを参考にするので、それを意識して使うとよい。
説明が難しいのでいつか具体的な使い方のnoteを書こうと思います!
④Anytest選択:Anytestのバージョン指定。
none:Anytestを使わない普通のi2i
anytestV3:入力画像(Anytest画像)に忠実なanytest。制御が比較的強い。
anytestV3:入力画像(Anytest画像)よりpromptに忠実なanytest。自由度が高い
⑤prompt:AIに対する指示を入力する。所謂呪文。
⑥negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
⑦prompt分析:入力画像のpromptを解析するボタン
⑧画像再現度(0-0.9):数値が大きいほど元の画像に近くなり、変化が乏しくなる。
⑨Anytest忠実度(0.35-1.25):数値が大きいほどAnytestの影響度が高くなる。
⑩生成:生成ボタン。こちらをクリックすると画像が生成される
⑪出力画像:出力画像が表示される
⑫クリップボード:クリップボードに出力画像を張り付ける
⑬線画タブ転送:生成された画像を線画タブの入力欄に転送する
⑭出力先フォルダ:出力先フォルダが開く
image2image:拡張UI
--exuiオプションで起動した時にだけ現れるUI

Loraモデル一覧:Lora一覧。選択するとpromptにLoraが追加される
LoRAモデル一覧更新:LoRA一覧を読み込むボタン
LoRAモデル一覧更新ボタンを押した後、Loraモデル一覧からLoRAを選んで使う
線画化タブ
線画を出力する機能を持つタブ。

①入力画像:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。
②canny画像:白黒反転した線画みたいなを入力する。
検出される線を濃くしたいとき:20/120
検出される線を薄くしたいときは:150/240
等に設定して調整してください。
③prompt:AIに対する指示を入力する。所謂呪文。
④negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
⑤prompt分析:入力画像のpromptを解析するボタン
⑥線画忠実度(0.5-1.25):数値が大きいほど線画の影響が強くなる。
⑦線画太さ(0-1.4):数値が大きいほど線が太くなる。
⑧生成:生成ボタン。こちらをクリックすると画像が生成される
⑨出力画像:出力画像が表示される
⑩クリップボード:クリップボードに出力画像を張り付ける
⑪Normalmapタブ転送:生成された画像をNormalmapタブの入力欄に転送する
⑫出力先フォルダ:出力先フォルダが開く
線画入り抜きタブ
マウス等で描いた平坦な線画をなんかいい感じにするタブ。こういうことができます。

ノーマルマップタブ
疑似3D画像を出力する機能を持つタブ。こういうことができます。
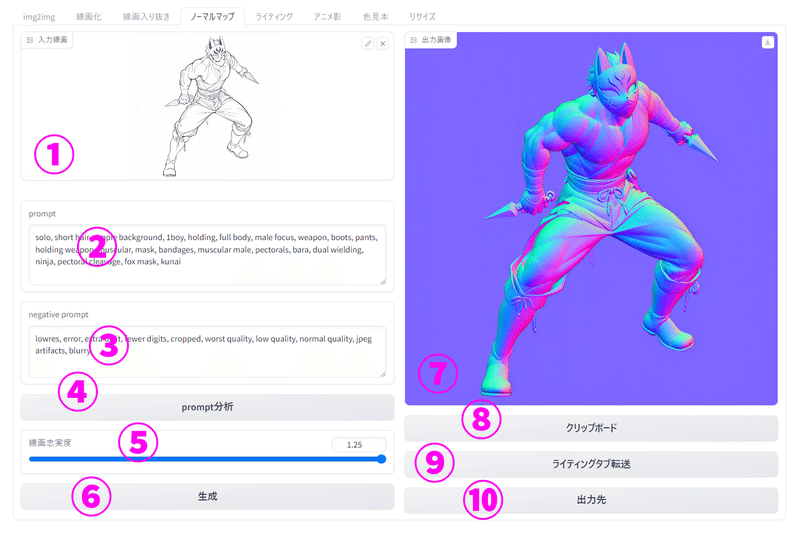
①入力線画:AI生成のベースになる線画を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。
②prompt:AIに対する指示を入力する。所謂呪文。
③negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
④prompt分析:入力画像のpromptを解析するボタン
⑤線画忠実度(0.5-1.25):数値が大きいほど線画の影響が強くなる。
⑥生成:生成ボタン。こちらをクリックすると画像が生成される
⑦出力画像:出力画像が表示される
⑧クリップボード:クリップボードに出力画像を張り付ける
⑨Normalmapタブ転送:生成された画像をNormalmapタブの入力欄に転送する
⑩出力先フォルダ:出力先フォルダが開く
ライティングタブ
疑似3D画像をライティングします。
①入力画像:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。画面キャプチャボタンで画面をキャプチャできる。
(範囲指定のあと、Enterキーを押して画面キャプチャできます)
②光源プリセット:プリセットの光源を選択できる
③light_yaw:光の角度パラメータその1
④light_pitch:光の角度パラメータその2
⑤specular_power:ライティングされる物質の表面の滑らかさや光沢度
⑥NormalDiffuseStrength: ランバート反射による拡散光の強さ調整を行います。なるほどわからん
⑦SpecularHighlightsStrength: フォン(Phong)の鏡面反射モデルによる鏡面反射の調整をします。わからん
⑧TotalGain: 全体の明るさを調整します。
⑨生成:ライティングされた画像が生成されます
⑩出力画像:出力画像が表示される
⑪クリップボード:クリップボードに出力画像を張り付ける
⑫アニメ影タブ転送:生成された画像をアニメ影タブの入力欄に転送する
⑬出力先フォルダ:出力先フォルダが開く
アニメ影化タブ
ライティングした画像をアニメ影風に変換します。
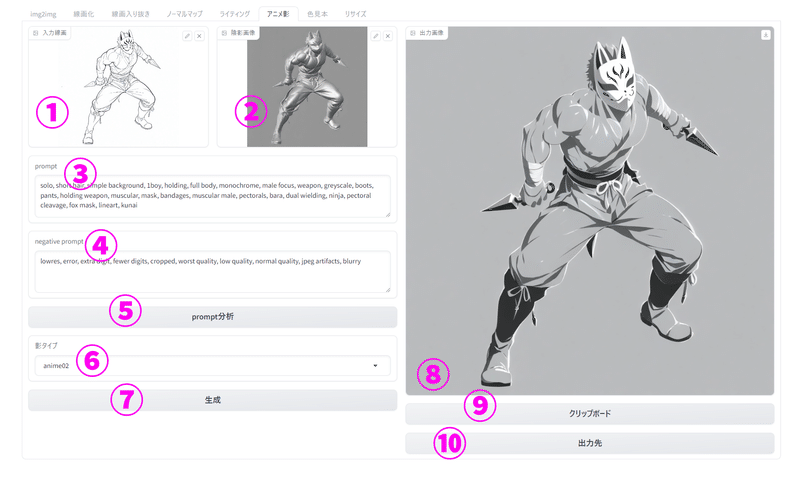
①入力線画:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。
②陰影画像:ライティングタブでライティングした画像を入力する。
③prompt:AIに対する指示を入力する。所謂呪文。
④negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
⑤prompt分析:入力画像のpromptを解析するボタン
⑥影種類:anime01,anime02から選べます。増えていく予定
⑦生成:生成ボタン。こちらをクリックすると画像が生成される
⑧出力画像:出力画像が表示される
⑨クリップボード:クリップボードに出力画像を張り付ける
⑩出力先フォルダ:出力先フォルダが開く
色見本タブ
promptに応じて見本色を塗ってくれます。あんまり厳密ではないです。
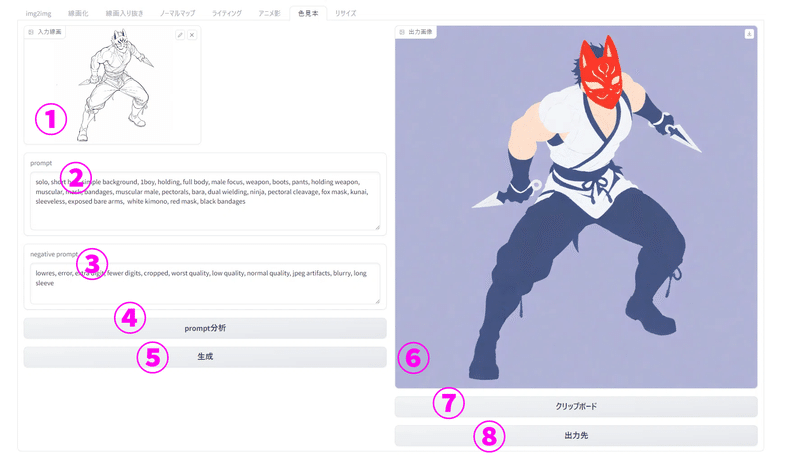
①入力線画:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。
②prompt:AIに対する指示を入力する。所謂呪文。
③negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
④prompt分析:入力画像のpromptを解析するボタン
⑤生成:生成ボタン。こちらをクリックすると画像が生成される
⑥出力画像:出力画像が表示される
⑦クリップボード:クリップボードに出力画像を張り付ける
⑧出力先フォルダ:出力先フォルダが開く
リサイズタブ
画像を最大長辺2880までにリサイズします

①入力画像:AI生成のベースになる画像を入力する。
余談だがここに自分が描いたもの以外のイラストを入れてベースに生成することは権利侵害になる可能性があるので許諾を得ていない場合はしないように。
②prompt:AIに対する指示を入力する。所謂呪文。
③negative prompt:生成されるイラストから除外したい要素を入力する。
わからなければデフォルトでOK(デフォルトは低品質な画像を取り除く呪文)
④prompt分析:入力画像のpromptを解析するボタン
⑤長辺の長さ:長い方の辺の長さ。拡大サイズを設定する。
⑥生成:生成ボタン。こちらをクリックすると画像が生成される
⑦出力画像:出力画像が表示される
⑧クリップボード:クリップボードに出力画像を張り付ける
⑨出力先フォルダ:出力先フォルダが開く
【ソースコード】
ソースコードをぺたり
【最後に】
気が向いたらおひねりください!!!!趣味でやっているけど、開発費が無限にかかるんだわがはは!!!
fanbox支援していただいたり、アマゾン欲しいものリストでギフト券投げてもらったり、下の有料課金記事ポチっていただいたりRPしていただくだけでやる気でます!!
(有料記事の中身は生成AIで生成したオーク健全イラスト集です)
私の生成したオークがかっこいい&かわいいから見て下さい!!!

ここから先は
この記事が気に入ったらサポートをしてみませんか?