
【石丸さん応援企画】Google Trend APIで東京都知事選挙をLookerで表現

東京都知事選挙が盛り上がってきましたね!家の近くの居酒屋やバーなどでも「東京都知事選挙」の話は毎日のように聞くようになってきて、今までにないような盛り上がり方だなと思っています。
そんな盛り上がりを見せる東京都知事選挙の検索傾向を調べるために、Google Trend APIを活用してダッシュボードを構築しました。
※画像はNewPicksから引用しています。
東京都知事選挙ダッシュボード


リンク先はこちらです。
"ネット"では圧倒的な石丸さん
直近60日→14日→7日…と見れば見るほど、石丸伸二さんのシェア率が上がっています。ネットでは石丸伸二さんは間違いないのですが、ネットを利用しない層からすると「石丸伸二さんは誰?」という声もあります。
TVで報道されない限り認識しにくい
ネットを利用しない高齢者は、小池百合子 vs 蓮舫の構図になっており、現役世代からすると、「石丸さんをもっとTVで扱って欲しい…」というマスコミの在り方に非常に疑問を感じます。
歯がゆい気持ちではありますが、本記事のタイトル通りの内容に戻り、石丸さんを応援しながら、Google APIの活用方法を紹介していきます。
そもそもなんでGoogle Trend APIを利用するのか?
Google Trendのブラウザ操作でも出力できますが、コーディングのメリットは1度更新したら、2回目の手動の更新作業がないことです。画面操作というのは非効率作業で、基本的に"2回目からは自動更新"を基本的に考えています。

Lookerで表現する理由
Googleトレンド画面では、折れ線が利用されており、絶対数ではなく相対比較数値が表示されているため、極端な数字が形成されることが多いです。
Lookerの平滑線グラフは見やすい
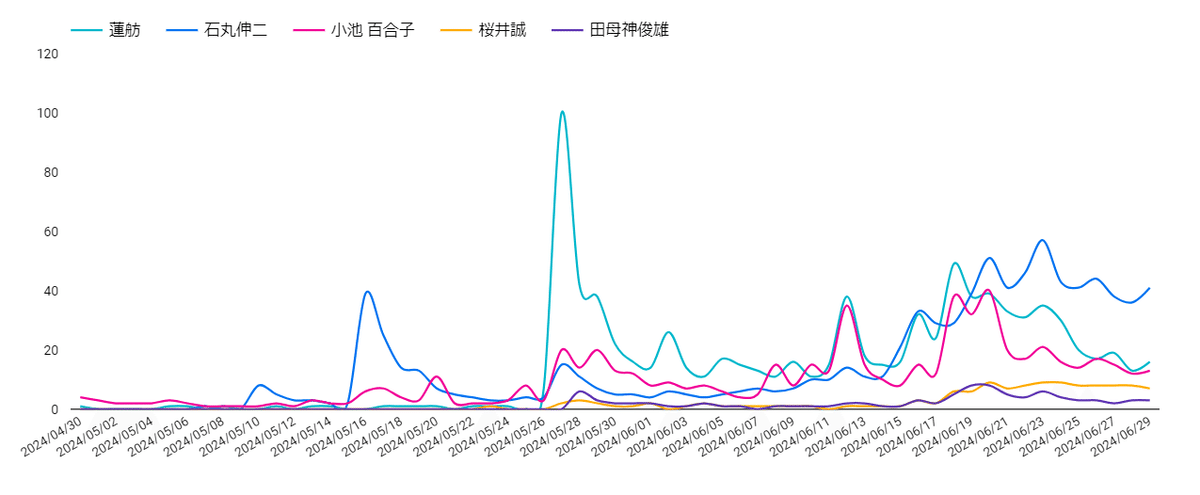
平滑線グラフ(スムージング曲線)は、データの変動を滑らかにし、全体の傾向を視覚的に捉えやすくするためのグラフです。通常、データポイントがばらついている場合、そのままプロットするとノイズが多く、全体のパターンが見えにくくなります。そのため、Lookerの平滑線グラフの方が見やすいと思います。
Google Trend APIは公式には存在しない
Googleに頑張って欲しいところですが、Google Trend APIは存在しません。pytrendsというライブラリを利用しています。そのため、pytrendsの仕様が変わったり、Googleからライブラリ経由での利用が許可されなくなったら利用できない可能性があります。
pytrendsライブラリとは?
GoogleトレンドデータにプログラムでアクセスするためのPythonパッケージです。このライブラリを使うことで、キーワードの検索トレンドを取得し、リアルタイムで分析することができます。
pytrendsライブラリでできること
ブラウザ操作と同じようなことが利用できます。
トレンドデータの取得
複数のキーワード比較
地域別のトレンド
関連キーワードの取得
トレンドの急上昇ワード
Pythonを使ってpytrendsライブラリを利用
コードで利用するのはPythonです。ここからは具体的な実装方法を紹介していきます。
必要なライブラリのインストール
必要なライブラリをインストールします。以下のコマンドを実行して、pytrendsをインストールしましょう。
pip install pytrends pandas datetimeGoogleトレンドデータの取得
まず、TrendReqオブジェクトを作成します。これはGoogleトレンドのAPIにリクエストを送るためのものです。次に、過去60日間のデータを取得するための期間を設定します。キーワードリストを指定し、そのキーワードに関するトレンドデータを取得します。
from pytrends.request import TrendReq
import pandas as pd
from datetime import datetime, timedelta
def get_trends_data(keywords):
pytrends = TrendReq(hl='en-US', tz=360)
# 直近60日間の期間を設定
end_date = datetime.today()
start_date = end_date - timedelta(days=60)
timeframe = start_date.strftime('%Y-%m-%d') + ' ' + end_date.strftime('%Y-%m-%d')
all_trends_data = pd.DataFrame()
# キーワードを処理
print(f"Processing keywords: {keywords}")
try:
pytrends.build_payload(keywords, cat=0, timeframe=timeframe, geo='JP', gprop='')
trends_data = pytrends.interest_over_time()
all_trends_data = pd.concat([all_trends_data, trends_data], axis=1)
except Exception as e:
print(f"Error retrieving data for {keywords}: {e}")
return all_trends_data
# 上位5つの検索キーワードを指定
kw_list = [
"石丸伸二", "蓮舫", "小池 百合子", "桜井誠", "ひまそらあかね"
]
# トレンドデータの取得
trends_data = get_trends_data(kw_list)
print(trends_data)具体的に何をしているのか解説します。
from pytrends.request import TrendReq
import pandas as pd
from datetime import datetime, timedelta
def get_trends_data(keywords):
pytrends = TrendReq(hl='en-US', tz=360)ライブラリのインポート:
TrendReq:pytrendsライブラリからのクラスで、GoogleトレンドのAPIにアクセスするために使用します。
pandas:データ操作のためのライブラリ。
datetimeとtimedelta:日付と時間を操作するための標準ライブラリ。
TrendReqオブジェクトの作成:
pytrends = TrendReq(hl='en-US', tz=360):TrendReqオブジェクトを作成し、言語を英語(hl='en-US')、タイムゾーンを360分(UTC+6時間)に設定。
# 直近60日間の期間を設定
end_date = datetime.today()
start_date = end_date - timedelta(days=60)
timeframe = start_date.strftime('%Y-%m-%d') + ' ' + end_date.strftime('%Y-%m-%d')
all_trends_data = pd.DataFrame()期間の設定:
end_date:今日の日付を取得。
start_date:今日の日付から60日前の日付を計算。
timeframe:日付を文字列形式に変換し、YYYY-MM-DD形式で60日間の期間を指定。
all_trends_data:データフレームを初期化。
try: pytrends.build_payload(keywords, cat=0, timeframe=timeframe, geo='JP', gprop='')データ取得の準備:
pytrends.build_payload:キーワード、カテゴリ(cat=0はすべてのカテゴリ)、期間(先ほど設定した60日間)、地域(geo='JP'は日本)、プロパティ(gprop=''はすべてのGoogleプロパティ)を設定して、リクエストを作成します。
trends_data = pytrends.interest_over_time()
all_trends_data = pd.concat([all_trends_data, trends_data], axis=1)データの取得と統合:
trends_data = pytrends.interest_over_time():トレンドデータを取得。
all_trends_data = pd.concat([all_trends_data, trends_data], axis=1):取得したデータを既存のデータフレームに列方向(axis=1)で結合
# 上位5つの検索キーワードを指定
kw_list = [ "石丸伸二", "蓮舫", "小池 百合子", "桜井誠", "ひまそらあかね" ]
# トレンドデータの取得
trends_data = get_trends_data(kw_list) print(trends_data)キーワードリストの指定:
kw_list:検索するキーワードをリストとして指定。
トレンドデータの取得と出力:
・trends_data = get_trends_data(kw_list):指定したキーワードに関するトレンドデータを取得。
・print(trends_data):取得したトレンドデータをコンソールに出力。
取得したデータをスプレッドシートへ出力
スプレッドシートに出力するためのライブラリをインストールします。
pip install ezsheets Ezsheetsは、GoogleスプレッドシートとPythonを連携させるための便利なライブラリです。Ezsheetsを使えば、Googleスプレッドシートの読み書き、データの抽出や更新などを簡単に行えます。APIキーやOAuth2認証を設定する必要がなしで、スプレッドシートを扱える点が特徴です。
# スプレッドシートに出力
if not trends_data.empty:
trends_data.reset_index(inplace=True)
trends_data['date'] = trends_data['date'].dt.strftime('%Y-%m-%d')
ss = ezsheets.Spreadsheet('****あなたのスプレッドシートのid*****')
sheet = ss[0]
sheet.clear()
sheet.updateRow(1, trends_data.columns.tolist())
for i, column in enumerate(trends_data.columns):
sheet.updateColumn(i + 1, [str(column)] + trends_data[column].tolist())
else:
print("Failed to retrieve Google Trends data.")条件判定 (if not trends_data.empty:):
trends_dataが空でないかを確認します。つまり、取得したトレンドデータがある場合に以下の処理を行います。
日付のフォーマット変更:
trends_data.reset_index(inplace=True)
trends_data['date'] = trends_data['date'].dt.strftime('%Y-%m-%d')reset_index(inplace=True):
インデックスをリセットし、元のインデックスを列に移動します。
['date'] = trends_data['date'].dt.strftime('%Y-%m-%d'):
date列の日付をYYYY-MM-DD形式の文字列に変換します。
ezsheetsライブラリの使用:
ss = ezsheets.Spreadsheet('あなたのスプレッドシートのid*')
sheet = ss[0]ezsheets.Spreadsheet('あなたのスプレッドシートのid*'):ezsheetsライブラリを使用して、指定したスプレッドシートIDのスプレッドシートにアクセスします。
sheet = ss[0]: スプレッドシート内の最初のシート(インデックス0)を選択します。
ヘッダーの更新:
sheet.updateRow(1, trends_data.columns.tolist()): スプレッドシートの1行目に、trends_dataの列名をリスト形式で更新します。ここで、列名がシートの1行目に出力されます。
データの書き込み:
各列のデータをスプレッドシートの2行目以降に書き込みます。列名を1行目に書き込むため、[str(column)] + trends_data[column].tolist()で列名をリストの先頭に追加しています。
データが取得できなかった場合の処理:
for i, column in enumerate(trends_data.columns):
sheet.updateColumn(i + 1, [str(column)] + trends_data[column].tolist())
for i, column in enumerate(trends_data.columns):各列に対してループします。
sheet.updateColumn(i + 1, [str(column)] + trends_data[column].tolist()): 各列のデータをスプレッドシートの2行目以降に書き込みます。
列名を1行目に書き込むため、[str(column)] + trends_data[column].tolist()で列名をリストの先頭に追加しています。
Lookerで読み取れるようにスプレッドシートを加工
スプレッドシートでは下記のように表示されています。

関数を利用して下記のように修正します。

あとは、Lookerに接続すれば完了です。

まとめ
都知事選挙の状況をリアルタイムで把握するために、今回はAPIを利用してダッシュボードが更新されるようにしました。
今回はGoogleトレンドでしたが、XやInstaのハッシュタグ検索もできるようにして石丸伸二さんの動向を確認していきたいと思います。
頑張れ石丸さん!皆さんも選挙にいきましょう!
この記事が気に入ったらサポートをしてみませんか?