Pythonでフィットネスクラブによる退会予測をしてみた【Aidemy成果物】

Aidemyの『データ分析講座』を受講したので、成果物としてまとめます。
【開発環境】
・マシンスペック: Ryzen 9 5900HX/3.30 GHz
・pythonバージョン:Python 3.9.7
・OS:Windows
【目的】
フィットネスクラブによる会員情報(退会者のみ)から退会予測を行う。
【前提条件】
・会員情報の統計分析は事前に実施済み
⇒ 性別、年代、利用回数、利用日、在籍期間など
・入会後6か月で退会するかを判定する(正解値)
⇒ 入会後6か月付近で辞める人が多いことから、辞めない人と何らかの
違いがありそう
【使用データ】
実際にあるフィットネスクラブの会員データを用いる。
(以下のようなデータを使用し、会員番号で結合する)
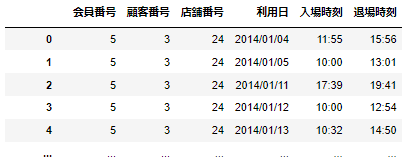
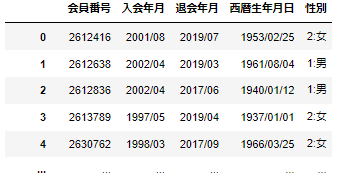
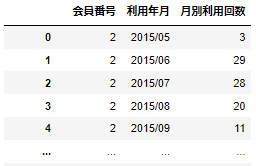
#3つのデータの結合例
df12 = pd.merge(df1, df2, on='会員番号', how='inner')
df123 = pd.merge(df12, df3, on='会員番号', how='inner')【学習方式及びモデルの決定】
今回はある期間で退会するか/しないか を判定するため2値分類を用いる。
また、分類には教師あり学習においてよく用いられる
・ロジスティック回帰
・サポートベクターマシン
・決定木
・ランダムフォレスト
というアルゴリズムを選択した。
以下の記事は2値分類を行う上で参考になったので載せます。
(※複数モデルの比較はかなり処理時間を取られるので注意!)
★分析準備★
【前処理・クレンジング】
①明らかに必要ないデータの削除
②データ型の変換(日付が文字列で格納されていることが多い)
③欠損値の確認 ⇒ ある場合:欠損は使えないので削除
※欠損値は平均値や最頻値で補完することもあるが今回は除外する。
#使用しない列の削除
df = df.drop(["店舗名","店舗番号","顧客番号","入場時刻","退場時刻"], axis=1) #データ型変換
df["入会年月"] = pd.to_datetime(df["入会年月"])
df["退会年月"] = pd.to_datetime(df["退会年月"])【分類に必要なデータ生成】
①在籍期間:退会した年月 - 入会した年月
②在籍期間のカテゴリー:在籍期間が6か月以下とそれ以外
③利用間隔(平均値 or 中央値):次の利用日 - 利用日
④出席曜日:出席日から算出
#必要カラムの生成
df["在籍月数"] = (df['退会年月'].dt.year - df['入会年月'].dt.year) * 12 + df['退会年月'].dt.month - df['入会年月'].dt.month
df["在籍期間カテゴリー"] = np.where(df['在籍月数'] <= 6, '早期退会', '優良')
df["年齢"] = (2022 - df['西暦生年月日'].dt.year)
df["年代"] = df['年齢'].apply(lambda x:math.floor(x/10)*10)
df['cycle'] = df[["会員番号","利用日"]].groupby("会員番号").diff()
df['ID_diff'] = df['会員番号'].shift()
df_diff = df[df['会員番号'] == df['ID_diff']]
df_diff['利用間隔'] = df_diff['cycle'].apply(lambda x : x.days)
df_mean = df1_diff[["会員番号","利用間隔"]].groupby("会員番号").mean()
df_median = df1_diff[["会員番号","利用間隔"]].groupby("会員番号").median()
df_merge = pd.merge(df_mean, df_median, on='会員番号', how='inner')【ダミー変数の生成】
性別は男性、女性、その他があるのでそれぞれ0,1,2に変換
#ダミー変数作成用関数
def enc(df,columns):
df_dummy = pd.get_dummies(df[columns], prefix = columns)
df_drop = df.drop([columns], axis = 1)
df1 = pd.concat([df_drop,df_dummy], axis = 1)
return df1
#性別ダミー変数
df_study = enc(df,"性別")【標準化】
利用間隔(平均)、利用間隔(中央値)、入会後2ヵ月利用回数(平均)を標準化
(以下の関数を使用)
#標準化のコード
StandardScaler().fit_transform()★仮説①★
"入会後2ヵ月のデータを見れば6か月以内に辞めるか判定できる"
(入会日は人によって1~30日などばらつきがあるので入会月は使わない。)
※統計分析より、入会後6か月以内で退会する人は6か月以上続ける人に比べて月ごとの利用回数が全体的に低いことがわかっている。そこで、6か月で退会するかどうかを早期に判定できる可能性を鑑みて、入会後2~3か月の利用回数を使用する。
【目的変数と説明変数】
目的変数は
・6か月で退会する = "早期退会"
・上記より在籍期間が長い = "優良"
と設定する。
説明変数には
・性別のダミー変数
・年代
・利用間隔(平均、中央値)
・入会後2ヵ月利用回数(平均)
を使用する。
#説明変数
X = df["性別_0:不明","性別_1:男","性別_2:女","年代","利用間隔(平均)","利用間隔(中央値)","入会後2ヵ月利用回数(平均)"]]
# 目的変数
y = df["在籍期間カテゴリー"]【データの分割】
train_test_split関数を用いる。
train_X,test_X,train_y,test_y = train_test_split(X,y, test_size=0.3, random_state=3)【学習】
前述したアルゴリズムで学習する。
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
logr_model = LogisticRegression()
logr_model.fit(train_X, train_y)
#決定木
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(train_X, train_y)
#k近傍法
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier(n_neighbors=6)
knn_model.fit(train_X, train_y)
#サポートベクターマシーン
from sklearn.svm import LinearSVC
svm_model = LinearSVC(random_state=3)
svm_model.fit(train_X, train_y)
#ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
rfc_model = RandomForestClassifier(random_state=3)
rfc_model.fit(train_X, train_y)【評価】
各アルゴリズムで学習したモデルをテストデータを用いて評価する。
#ロジスティック回帰
logr_model.score(train_X,train_y)
logr_model.score(test_X,test_y)
0.67
#決定木
tree_model.score(train_X,train_y)
tree_model.score(test_X,test_y)
0.61
#k近傍法
knn_model.score(train_X,train_y)
knn_model.score(test_X,test_y)
0.65
#サポートベクターマシーン
svm_model.score(train_X,train_y)
svm_model.score(test_X,test_y)
0.39
#ランダムフォレスト
rfc_model.score(train_X,train_y)
rfc_model.score(test_X,test_y)
0.64【チューニング】
説明変数の変更
統計分析より、入会後4か月の利用回数と5か月の利用回数の変化率が大きいことが分かっているので、早期に判定できることよりも正確に判定できることを重視する。
(旧) 入会後2ヵ月利用回数(平均)
⇓
(新) 変化率、入会後4・5ヵ月利用回数(平均)
★仮説②★
"入会後4・5ヵ月のデータを見れば6か月以内に辞めるか判定できる"
(入会日は人によって1~30日などばらつきがあるので入会月は使わない。)
入会後4・5ヵ月の各利用回数から変化率を算出
df["差分"] = df["利用回数(5か月)"] - df["利用回数(4か月)"]
df["変化率"] = df["差分"] / df["利用回数(4か月)"]
【評価】
説明変数を変更し、上述同様に学習し評価する。
#ロジスティック回帰
logr_model.score(train_X,train_y)
logr_model.score(test_X,test_y)
0.82
#決定木
tree_model.score(train_X,train_y)
tree_model.score(test_X,test_y)
0.72
#k近傍法
knn_model.score(train_X,train_y)
knn_model.score(test_X,test_y)
0.81
#サポートベクターマシーン
svm_model.score(train_X,train_y)
svm_model.score(test_X,test_y)
0.82
#ランダムフォレスト
rfc_model.score(train_X,train_y)
rfc_model.score(test_X,test_y)
0.80正解率が概ね80%超える結果となった。
【交差検証法】
過学習の可能性があるので、交差検証を行う。
#交差検証法
from sklearn.model_selection import StratifiedKFold
stratifiedkfold = StratifiedKFold(n_splits = 3)
algorithms = [model,tree_model,knn_model,svm_model,rfc_model]
from sklearn.model_selection import cross_val_score
for algorithm in algorithms:
scores = cross_val_score(algorithm,train_X, train_y,cv=stratifiedkfold)
score = scores.mean()
name = algorithm.__class__.__name__
print(f'平均スコア:{score:.4f} 個別スコア:{scores} {name}')平均スコア:0.8240 個別スコア:[0.82376464 0.82414548 0.82395506] LogisticRegression
平均スコア:0.7233 個別スコア:[0.71960392 0.72150814 0.72874417] DecisionTreeClassifier
平均スコア:0.8192 個別スコア:[0.81862325 0.81862325 0.82033705] KNeighborsClassifier
平均スコア:0.6337 個別スコア:[0.82376464 0.25316576 0.82424069] LinearSVC
平均スコア:0.8038 個別スコア:[0.8024374 0.8015805 0.80748358] RandomForestClassifier【重要度の確認】
交差検証においてもロジスティック回帰とランダムフォレストに関して予測が上手くできたので、どの変数がどれだけ寄与しているかを確認する。
#ランダムフォレストの重要度
importances = rfc_model.feature_importances_
w = pd.Series(importances, index = X.columns)
u = w.sort_values(ascending=False)利用間隔(平均) 0.49
変化率 0.15
利用間隔(中央値) 0.14
入会後4・5ヵ月利用回数(平均) 0.12
年代 0.09
性別_1:男 0.00
性別_2:女 0.00
性別_0:不明 0.00【考察】
入会後6か月で辞めるかどうかは性別や年代より利用に関する項目が影響していることが分かった。
つまり、スポーツクラブにおいて会員の利用傾向を見ることで退会予測ができる可能性が示唆されたといえる。
【最終コード】
再現性を考慮して、一部まとめて記載する。
import pandas as pd
import numpy as np
import csv
import datetime
import math
from datetime import time
from datetime import datetime
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
pd.options.display.float_format="{:.2f}".format
#csv開く
df = pd.read_csv(filepath_or_buffer=r"C:※※※.csv", encoding="utf-8", sep=",")
#使用しない列削除
df = df.drop(["不要カラム名"・・・], axis=1)
#datetime型に変換
df["変換したいカラム名"] = pd.to_datetime(df["変換したいカラム名"])
#欠損値の判定
df.isnull().sum()
#必要カラムの生成
df["在籍月数"] = (df['退会年月'].dt.year - df['入会年月'].dt.year) * 12 + df['退会年月'].dt.month - df['入会年月'].dt.month
df["在籍期間カテゴリー"] = np.where(df['在籍月数'] <= 6, '早期退会', '優良')
df["年齢"] = (2022 - df['西暦生年月日'].dt.year)
df["年代"] = df['年齢'].apply(lambda x:math.floor(x/10)*10)
df['cycle'] = df[["会員番号","利用日"]].groupby("会員番号").diff()
df['ID_diff'] = df['会員番号'].shift()
df_diff = df[df['会員番号'] == df['ID_diff']]
df_diff['利用間隔'] = df_diff['cycle'].apply(lambda x : x.days)
df_mean = df1_diff[["会員番号","利用間隔"]].groupby("会員番号").mean()
df_median = df1_diff[["会員番号","利用間隔"]].groupby("会員番号").median()
df_merge = pd.merge(df_mean, df_median, on='会員番号', how='inner')
#ダミー変数作成用関数
def enc(df,columns):
df_dummy = pd.get_dummies(df[columns], prefix = columns)
df_drop = df.drop([columns], axis = 1)
df1 = pd.concat([df_drop,df_dummy], axis = 1)
return df1
#データの結合
df_study = pd.merge(df, df_merge, on='会員番号', how='inner')
#入会後4か月と5か月
from dateutil.relativedelta import relativedelta
df_study["入会3ヵ月後"] = df_study["入会年月"].apply(lambda x: x + relativedelta(months=3))
df_study["入会4ヵ月後"] = df_study["入会年月"].apply(lambda x: x + relativedelta(months=4))
df_study["入会5ヵ月後"] = df_study["入会年月"].apply(lambda x: x + relativedelta(months=5))
df_study["入会6ヵ月後"] = df_study["入会年月"].apply(lambda x: x + relativedelta(months=6)) #年月のデータ型変換
df_study['利用年月'] = pd.to_datetime(df_study['利用年月'])
#入会後4か月と5か月の利用回数平均算出
df_study = df_study.query("利用年月 > 入会3ヵ月後 & 利用年月 < 入会6ヵ月後")
df_study_mean = df_study[["会員番号","月別利用回数"]].groupby("会員番号").mean()
#入会後4か月と5か月の利用回数変化率算出
df_study_test = df_study.query("利用年月 == 入会4ヵ月後")
df_study_test2 = df_study.query("利用年月 == 入会5ヵ月後")
df_study_test = df_study_test[["会員番号","月別利用回数"]]
df_study_test2 = df_study_test2[["会員番号","月別利用回数"]]
df_study_test = df_study_test.rename(columns={'月別利用回数': '月別利用回数(4か月)'})
df_study_test2 = df_study_test2.rename(columns={'月別利用回数': '月別利用回数(5か月)'})
df_study_test_merge = pd.merge(df_study_test, df_study_test2, on='会員番号', how='inner')
df_study_test_merge["差分"] = df_study_test_merge["月別利用回数(5か月)"] - df_study_test_merge["月別利用回数(4か月)"]
df_study_test_merge["変化率"] = df_study_test_merge["差分"] / df_study_test_merge["月別利用回数(4か月)"]
#データ整理 (結合・不要行削除・重複行削除)
df_study_merge = pd.merge(df_study, df_study_mean, on='会員番号', how='inner')
df_study_merge = df_study_merge.rename(columns={'月別利用回数': '4~5ヵ月利用回数(平均)'})
df_study_merge = df_study_merge.drop_duplicates()
df_study_merge = pd.merge(df_study_merge, df_study_test_merge, on='会員番号', how='inner')
df_study_merge = df_study_merge.dropna()
#性別ダミー変数
df_study_merge = enc(df_study_merge,"性別")
#列の移動 (在籍期間カテゴリーを最終列へ)
col = df_study_merge.columns.tolist()
col.remove('在籍期間カテゴリー')
col.append('在籍期間カテゴリー')
df_study_merge = df_study_merge[col]
#標準化
std = df_study_merge[["利用間隔(平均)","利用間隔(中央値)","4~5ヵ月利用回数(平均)","変化率"]]
std = StandardScaler().fit_transform(test)
df_std = df_study_merge.copy()
df_std[["利用間隔(平均)","利用間隔(中央値)","4~5ヵ月利用回数(平均)","変化率"]] = std
#データフレーム結合
df_std = pd.merge(df_std, df_study_merge, on='会員番号', how='inner')
#説明変数
X = df_std[["性別_0:不明","性別_1:男","性別_2:女","年代","利用間隔(平均)","利用間隔(中央値)","4~5ヵ月利用回数(平均)","変化率"]]
# 目的変数
y = df_std["在籍期間カテゴリー_x"]
#データ分割
from sklearn.model_selection import train_test_split
train_X,test_X,train_y,test_y = train_test_split(X,y, test_size=0.3, random_state=3)
#モデル作成 #ロジスティック回帰
from sklearn.linear_model import LogisticRegression
logr_model = LogisticRegression()
logr_model.fit(train_X, train_y)
#決定木
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(train_X, train_y)
#k近傍法
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier(n_neighbors=6)
knn_model.fit(train_X, train_y)
#サポートベクターマシーン
from sklearn.svm import LinearSVC
svm_model = LinearSVC(random_state=3)
svm_model.fit(train_X, train_y)
#ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
rfc_model = RandomForestClassifier(random_state=3)
rfc_model.fit(train_X, train_y)
#モデル評価 #ロジスティック回帰
logr_model.score(train_X,train_y)
logr_model.score(test_X,test_y)
#決定木
tree_model.score(train_X,train_y)
tree_model.score(test_X,test_y)
#k近傍法
knn_model.score(train_X,train_y)
knn_model.score(test_X,test_y)
#サポートベクターマシーン
svm_model.score(train_X,train_y)
svm_model.score(test_X,test_y)
#ランダムフォレスト
rfc_model.score(train_X,train_y)
rfc_model.score(test_X,test_y)
#重要度
importances = rfc_model.feature_importances_
w = pd.Series(importances, index = X.columns)
u = w.sort_values(ascending=False)
#交差検証法
from sklearn.model_selection import StratifiedKFold
stratifiedkfold = StratifiedKFold(n_splits = 3)
algorithms = [model,tree_model,knn_model,svm_model,rfc_model]
from sklearn.model_selection import cross_val_score
for algorithm in algorithms:
scores = cross_val_score(algorithm,train_X, train_y,cv=stratifiedkfold)
score = scores.mean()
name = algorithm.__class__.__name__
print(f'平均スコア:{score:.4f} 個別スコア:{scores} {name}')【今後の予定】
データ分析講座を終えて、Pythonで行うデータ分析の流れや機械学習の実装が身に付いたので、実務での活用を検討していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?