Python : データのマージ(Google Colaboratory)

関連するデータがファイルに分かれているとき,1つの表にまとめたいです.
例えば,複数の被験者に実験やアンケートを複数回したとき,1回ごとのファイルとして出力されることがあります.

各ファイルに保存されている被験者IDをキーとしてすべてのファイルのデータを一覧表にします.

データファイルを読み込む
被験者ファイルを読み込む
被験者ファイルにデータファイルをマージする
行ごとに合計を求める
結果をファイルに出力する
(1)データファイルの読み込み
同じ形式のファイルがたくさんあるとき,ファイル名はとても重要.連番になるように決めていると連続処理ができます.
ここでは、C02.csv , C03.csv , C04.csv , ・・・ , C14.csvとしています.
import pandas as pd
df = list()
for i in range(2,15) :
s = '/content/C{:02}.csv'.format(i)
print(s)
df0 = pd.read_csv(s)
df.append(df0)Colaboratoryでは、ファイルは/content/内にあるので、
/content/C02.csv
/content/C03.csv
/content/C04.csv
:
から読み込むことになります.ファイル名を文字列で生成して指定しています.
s = '/content/C{:02}.csv'.format(i)
df0 = pd.read_csv(s)
連続処理をするためには,読み込んだDataFrameをリストにしておくと便利
df.append(df0)
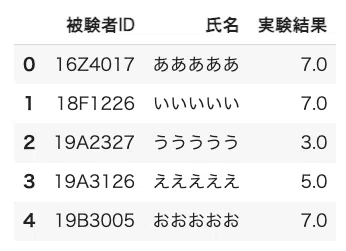
(2)被験者ファイルの読み込み
データファイルには欠席などの理由で実験やアンケートができなかった被験者がおり,ファイルに記載されていないことが想定されます.一覧表のベースとなる被験者全員の名簿を作成しておきます.
df_base = pd.read_csv('/content/名簿.csv')
df_base.head()
ここで,共通の項目である「被験者ID」と「氏名」について,2種類のDataFrame(実験データと名簿)で異なる列名をつけておくとマージした後の処理が楽になります.
(3)名簿に結果データをマージする
マージには以下の種類があります.
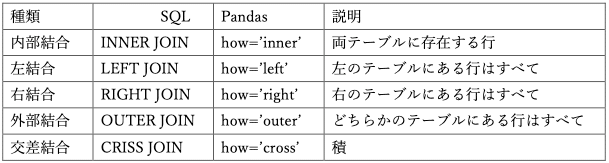
データベースのSQLと考え方は同じです.
キーの指定
2つのテーブルのキーの列名が同じであれば
on = キーの列名
2つのテーブルのキーの列名が異なるときは
left_on=左のキーの列名 , right_on=右のキーの列名
両方のテーブルに同じ列名があるとき,マージの結果列名に_xと_yというサフィックスが付きます.
ここでは、ベースとなる名簿に実験結果のデータを次々にマージいていきますから,同じ列名は片方を削除しておきたい.そうでないと,例えば同じ氏名が15個並ぶことになってしまいます.
片方を削除するためには,_x _yのようなサフィックスがつかない方が指定しやすく,そのためには,最初から左右のテーブルの列名を異なるものにしておけばよいのです.
for i , df0 in enumerate(df) :
#得点列名の変更
c_name = '実験{:02}'.format(i+2)
print(c_name)
df0 = df0.rename(columns={'実験結果' : c_name})
df_base = pd.merge(df_base , df0 , how='left' , left_on='ID' , right_on='被験者ID')
df_base = df_base.drop('氏名' , axis=1)
df_base = df_base.drop('被験者ID' , axis=1)
(4)行ごとに合計を求める
数値でない氏名とIDは合計項目からはずします.
df_base['sum'] = df_base.sum(axis=1 , numeric_only=True)
df_base.head()(5)ファイルに保存
df_base.to_csv('一覧表.csv')