
ボラティリティを収益源とする仮想通貨自動売買における損益と時間帯の関係および考察

の11日目の記事になります。
richmanbtcさんのチュートリアルコードを使いたいと思います。
https://github.com/richmanbtc/mlbot_tutorial/blob/master/work/tutorial.ipynb
この記事にはチュートリアルコードにおける直近のバックテストのネタバレが含まれます。
概要と目標
前置き
richmanbtcさんが公開されているMLbotのチュートリアルについて、ポジション制限と機械学習の予測を適応しない場合のバックテストの成績は、2022年の初めから急激に悪くなっています。

一方で、この成績は時間帯を考慮しておらず、改善の余地がありました。
目標
そこで、この記事では時間帯の情報を分析し、GMOコインにおけるBTC_JPYの15分足の直近のバックテストの見た目を改善することを目標にしたいと思います。
全体の流れ
バックテストで散々な結果になっているATR0.5の指値戦略を時間のエッジを使ってなんとか右肩上がりにしたい。
→MLの予測対象のyはそのまま損益を表しているからこれがどういう分布か調べたらヒントがあるかもしれない。
→数パーセントの外れ値を抽出すると、かなり少ない数なのに損益に大きな影響を与えている。
→悪影響を及ぼす外れ値と時間帯に注目して分析したら、歪んでいることは分かった。
→上手く活用できなかったので外れ値のことは忘れて時間帯だけに注目してフィルタを作成したら上手くいった。
→テスト用に残しておいた2023年のデータを使って検証すると、yの累積はある程度良くなった。
あとは、最後に扱いきれなかったけど分析したものとか問題点とか使い道とか書きました。
準備
使用データの期間
使用データは、2018-09-05 08:00:00+00:00~2023-11-16 20:00:00+00:00とします。
そのうち、2022-12-31 23:45:00+00:00までのデータをフィルタ作成用データとします。
df = df[df.index<pd.to_datetime('2023-11-16 20:00:00+00:00', utc=True)]df全体のデータ数は179554です。
このdfに対して、チュートリアルに従ってfee, ATR 14(calc_featuresをせずにATRのみ単体で入れておく), buy/sell_price, buy/sell_fep, buy/sell_executed, y_buy/sell, buy/sell_costを計算してdropna()した後、
trainとtestで分けます。
# ohlcの表記はこちらの都合で変更しています。
df.rename(
{
'op':'open',
'hi':'high',
'lo':'low',
'cl':'close',
}, axis=1, inplace=True
)
train = pd.to_datetime('2023-01-01', utc=True)
df_train = df[df.index<train]
df_test = df[df.index>=train]現状
一旦、直近のy_buyとy_sellのcumsumを、テストデータを使って確認します。
df_test['y_buy'].cumsum().plot(label='y_buy')
df_test['y_sell'].cumsum().plot( label='y_sell')
(df_test['y_buy'].cumsum()+df_test['y_sell'].cumsum()).plot(label='y_buy+y_sell')
plt.title('df_test cumsum')
plt.legend()
plt.show()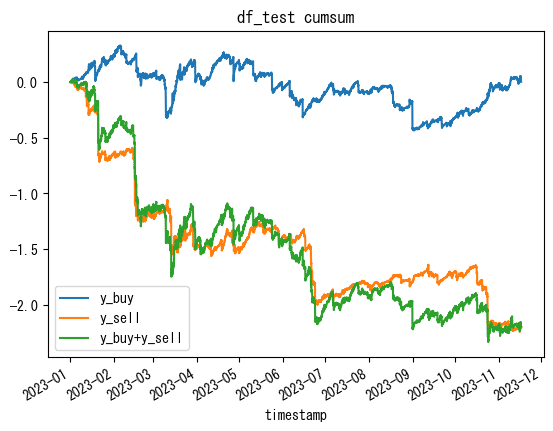
ヒストグラム(雰囲気)
trainデータのy_buyとy_sellのヒストグラムを確認します。数が多く見にくくなるため0のデータは除きます。
同様に見にくくなるため、xlimでグラフを制限することで外れ値も除外します。
df_train[df_train['y_buy']!=0]['y_buy'].hist(bins=100, label='y_buy')
df_train[df_train['y_sell']!=0]['y_sell'].hist(bins=100,label='y_sell', alpha=0.5)
plt.legend()
plt.xlim([-0.05, 0.05])
plt.title('df_train y_buy, y_sell ヒストグラム')
plt.show()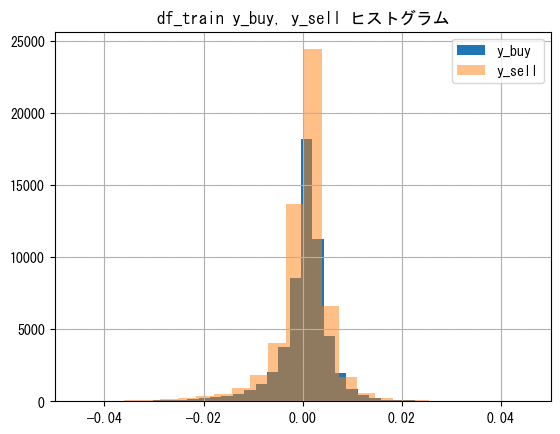
どちらもマイナス側に裾が広がっているように見えます。
散布図(雰囲気)
y_buyだけ見ておきます。
plt.scatter(df_train.index.hour, df_train['y_buy'], s=0.01)
plt.grid()
plt.title('df_train y_buy 散布図')
plt.show()
特に何も分かりませんでした。
plt.scatter()はs=で粒の大きさを変えられます。大きいままだと何がなんだか分からないことも多いので、小さめに設定するのはオススメです。
使う関数
今回は時間帯情報について、損益データの外れ値の影響とその分布に絡めて分析を行いました。
外れ値を見たいので、np.percentile()という便利関数を使います。
この関数は、
NumPyライブラリにある関数で、データセット内の特定の百分位数を計算します。この関数は、数値データの配列と百分位数を指定すると、その百分位数に相当するデータの値を返します。例えば、np.percentile(data, 50)というコードは、データセットの中央値(50%百分位数)を計算します。同様に、25%や75%など、任意の百分位数を指定することができます。これは統計データを分析する際に非常に役立つツールです。
だそうです。
外れ値を分ける閾値を作成してプロット
np.percentile()を使って閾値を用意します。0を除いたy_buyとy_sellに対して、下位n%とそれ以外を分ける閾値を作成します。
試しに10%で作成してプロットしてみます。
th = 90
# 閾値作成
high_y_buy = np.percentile(df_train[df_train['y_buy']!=0]['y_buy'], th)
low_y_buy = np.percentile(df_train[df_train['y_buy']!=0]['y_buy'], 100-th)
high_y_sell = np.percentile(df_train[df_train['y_sell']!=0]['y_sell'], th)
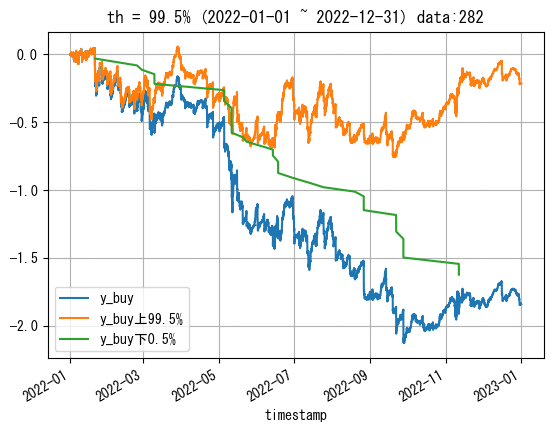
low_y_sell = np.percentile(df_train[df_train['y_sell']!=0]['y_sell'], 100-th)上から、約0.0054, -0.0053, 0.0052, -0.0056となりました。
この閾値を使ってy_buyのみプロットしてみます。ただし、見やすいようにプロットは2022年のみです。
# 2022-01-01~2022-12-31について
# y_buy全体をプロット
plt.plot(df_train.loc[df_train.index>pd.to_datetime('2022-01-01',utc=True),'y_buy'].cumsum(), label='y_buy')
# low_y_buy(下位1%の閾値)で分けてプロット
df_train.loc[(df_train.index>pd.to_datetime('2022-01-01',utc=True)) & (df_train['y_buy']>=low_y_buy)]['y_buy'].cumsum().plot(label=f'y_buy上{th}%')
df_train.loc[(df_train.index>pd.to_datetime('2022-01-01',utc=True)) & (df_train['y_buy']< low_y_buy)]['y_buy'].cumsum().plot(label=f'y_buy下{100-th}%')
plt.title(f'{th = }% (2022-01-01 ~ 2022-12-31)')
plt.legend()
plt.grid()
plt.show()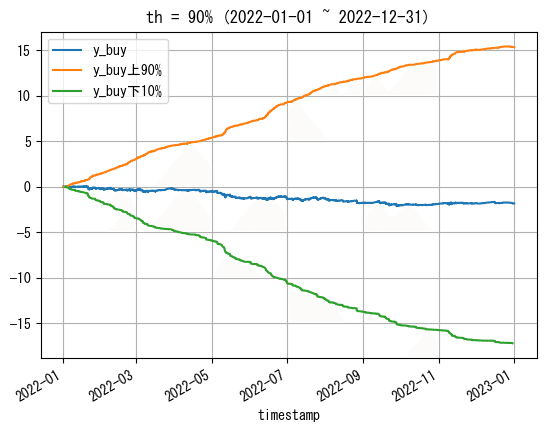
y_buyについて0以外の10%を除くだけで、かなり綺麗なグラフになりました。
この閾値を詰めていきます。
閾値を調整
y_buyの上側の累積が何パーセントくらいからプラスになるかを探りたいと思います。
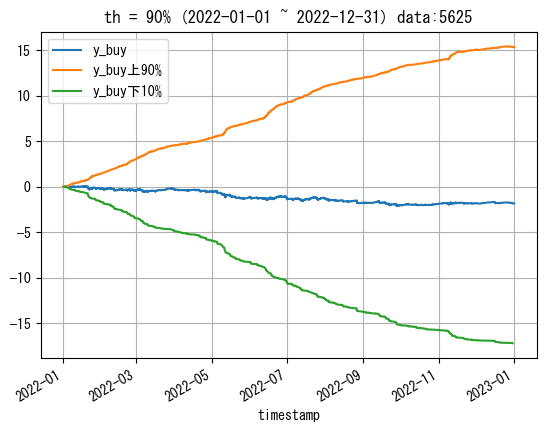
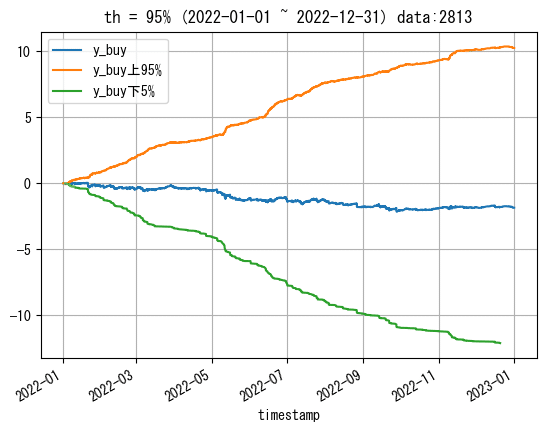
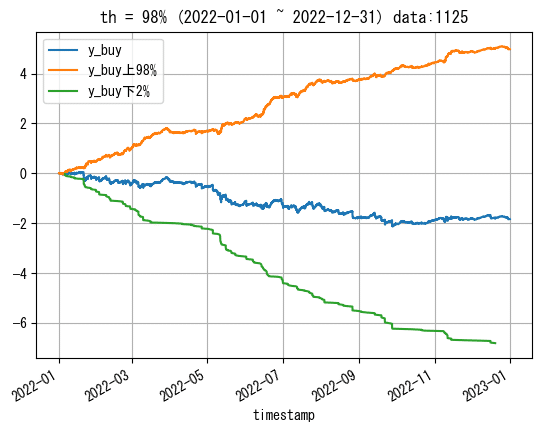
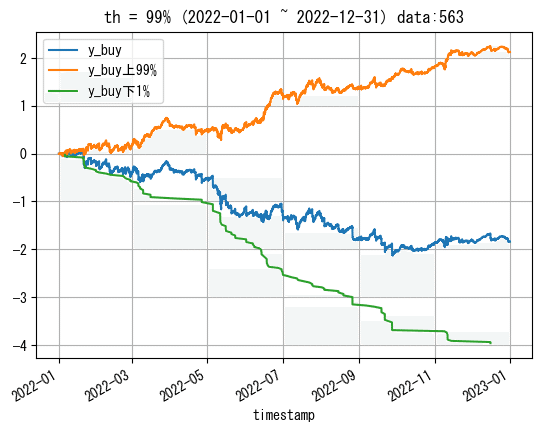
個人的には0以外の下位1%の閾値であれば、ヤバいデータは大体抽出できているかなという印象を持ちました。
しかし、今回少ない方のデータを扱うにあたって、1%だと562しかデータ数がないため、98%に設定して下位2%の1124のデータ数で分析をしてみたいと思います。
※y_sellも同じ閾値にして分析します。
※閾値を決定する際にy_buy!=0の条件を挟んだため、df_trainにおけるデータ数の2%よりも少なくなっています。
外れ値の部分のみ分離
再度閾値を計算しておいて
th = 98
#high_y_buy = np.percentile(df_train[df_train['y_buy']!=0]['y_buy'], th)
low_y_buy = np.percentile(df_train[df_train['y_buy']!=0]['y_buy'], 100-th)
#high_y_sell = np.percentile(df_train[df_train['y_buy']!=0]['y_sell'], th)
low_y_sell = np.percentile(df_train[df_train['y_buy']!=0]['y_sell'], 100-th)外れ値の部分だけを扱いやすいように分離しておきます。
y_buy_low = df_train[ df_train['y_buy']<low_y_buy]
y_sell_low = df_train[df_train['y_sell']<low_y_sell]y_buyとy_sellの0以外の下2%のヤバいデータが扱いやすくなりました。
分析
時間帯データについて
時間帯を絡めて調べて行きます。使用するのはdf_train.index.hourで取り出せる値です。1時間毎の時間を示す0~23のデータになります。
df_train.index.hour
#Int64Index([11, 12, 12, 12, 12, 13, 13, 13, 13, 14,
# ...
# 21, 21, 22, 22, 22, 22, 23, 23, 23, 23],
# dtype='int64', name='timestamp', length=149134)「全体のデータ(青)」と「下位2%のヤバいデータの時間帯の分布(オレンジ)」
y_buyとy_sellの下位2%のデータについて、その時間帯をy_buy_low.index.hour、y_sell_low.index.hourで取り出し、半透明オレンジのヒストグラムで描画します。青は0以外のy_buy/sell全体の分布です。
これで、y_buyとy_sellのヤバいデータがどの時間帯に多いのかが分かります。
※0~23の24種類のデータであり、最後の23~23.99...の部分を反映させるためにbins=range(25)としました。(24だとダメでした。)
※青はy_buy, y_sellについて全体から0を除いた時間帯ごとのデータの分布を示しています。
※縦軸は左右で異なっています。
buy側
fig, ax1 = plt.subplots()
ax1.set_xlabel('時間')
# 0以外のy_buyのヒストグラム
ax1.hist(df_train[df_train['y_buy'] != 0].index.hour, bins=range(25), color='tab:blue')
ax1.set_ylabel('0以外のy_buyの頻度', color='tab:blue')
ax1.tick_params(axis='y', color='tab:blue')
# 100-thパーセンタイル以下のy_buyのヒストグラム
ax2 = ax1.twinx()
ax2.hist(y_buy_low['y_buy'].index.hour, bins=range(25), color='tab:orange', alpha=0.5)
ax2.set_ylabel(f'y_buy下{100-th}%の頻度', color='tab:orange')
ax2.tick_params(axis='y', color='tab:orange')
plt.title('時間ごとのy_buyのデータ分布')
plt.show()sell側のコードは省略
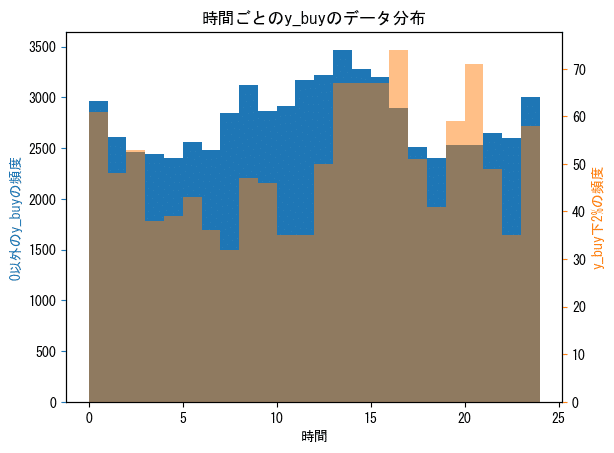

0以外のyについて、全体の分布と比較すると、危険なデータの時間帯分布がそれなりに歪んでいることが分かりました。
「全体の時間帯ごとのy_buy/sellの合計値(青)」と、「下位2%のヤバいデータの時間帯ごとのy_buy/sellの合計値(オレンジ)」
「時間帯ごとの0を除いたy_buy/sell(青)」と「y_buy/sell_low(下位0.5%のみのデータ)(半透明オレンジ)」の合計値も別々でプロットして見てみます。比較用に全体の合計を青でプロットしています。
buy側
# 時間ごとのy_buyとy_buy_lowの合計--------------------------------------
# y_buy全体の時間ごとの合計値
y_buy_hourly_sum = df_train[df_train['y_buy'] != 0].groupby(df_train[df_train['y_buy'] != 0].index.hour)['y_buy'].sum()
# y_buy下位100-th%の時間ごとの合計値
y_buy_low_hourly_sum = y_buy_low.groupby(y_buy_low.index.hour)['y_buy'].sum()
# プロット--------------------------------------
# y_buy全体の時間ごと合計値をプロット
fig, ax1 = plt.subplots()
ax1.bar(y_buy_hourly_sum.index, y_buy_hourly_sum, color='tab:blue')
# y_buy下位100-th%の時間ごとの合計値用の2つ目のy軸を作成
ax2 = ax1.twinx()
# y_buy下位100-th%の時間ごとの合計値をプロット
ax2.bar(y_buy_low_hourly_sum.index, y_buy_low_hourly_sum, alpha=0.5, color='tab:orange')
# 上下を同じ幅にするためにy軸の最大値を計算
max_lim = np.maximum(y_buy_hourly_sum.abs().max(), y_buy_low_hourly_sum.abs().max())
# y軸の範囲を設定
ax1.set_ylim([-max_lim*1.1, max_lim*1.1])
ax2.set_ylim([-max_lim*1.1, max_lim*1.1])
# y_buy全体のタイトルと軸ラベルの設定
ax1.set_ylabel('0を除いたy_buyの合計', color='tab:blue')
ax1.tick_params('y', colors='tab:blue')
# y_buy下位100-th%の時間ごとのタイトルと軸ラベルの設定
ax2.set_ylabel('y_buy_lowの合計', color='tab:orange')
ax2.tick_params('y', colors='tab:orange')
plt.title('時間ごとのy_buyとy_buy_lowの合計')
plt.xlabel('時間')
# グラフの表示
plt.show()
sell側のコードは省略

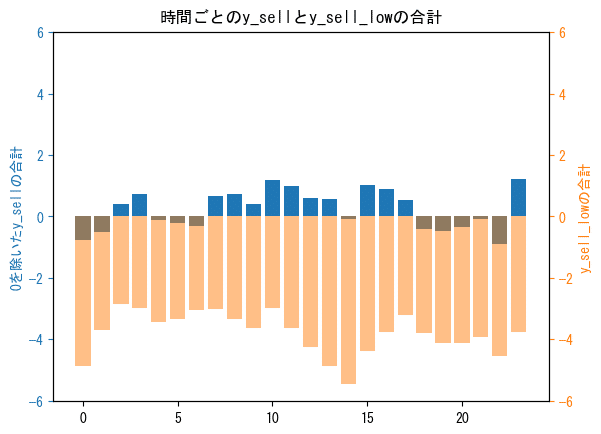
buy側もsell側はUTCで夕方から朝方まで(JTCでは朝3時頃から12時頃まで)について、2%の外れ値が全体の合計値に対して少なからず影響していそうです。
※y_buy/sell_lowは0を除いた下位2%のみを抽出しており、合計は全てマイナスになっています。
※縦軸は揃えてあります。
1時間毎のフィルタによるバックテスト
バックテストの方法
危険なデータの多い時間帯がなんとなく分かったので、その時間を除いて結果を見てみます。
具体的には、y_pred_buy/sellについて、全体を1で埋めた後、危険な時間帯を0に置き換えて、y_pred_buy/sellが1のときのみのy_buy累積を計算します。
アメリカの民が働いている時間だけでバックテスト
先ほどの時間ごとの棒グラフからUTCで夜17時から朝7時までが良くない気がしたので除外してみます。
# y_pred_buy/sellを01で埋める
df_train['y_pred_buy'] = 1
df_train['y_pred_sell'] = 1
excluded_indexes = [18,19,20,21,22,23,0,1,2,3,4,5,6]
for hour in excluded_indexes:
df_train.loc[df_train.index.hour == hour, 'y_pred_buy'] = 0
df_train.loc[df_train.index.hour == hour, 'y_pred_sell'] = 0
# 全体の期間
df_train['y_buy'].cumsum().plot(label='y_buy')
df_train.where(df_train['y_pred_buy']>0,0)['y_buy'].cumsum().plot(label='危険な時間帯を除いたy_buy')
df_train['y_sell'].cumsum().plot(label='y_sell')
df_train.where(df_train['y_pred_sell']>0,0)['y_sell'].cumsum().plot(label='危険な時間帯を除いたy_sell')
plt.legend()
plt.show()プロット部分(使い回します)
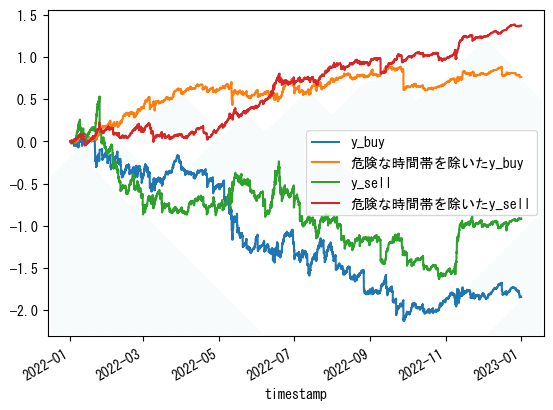
# 2022~2023の期間
df_train[df_train.index.year>=2022]['y_buy'].cumsum().plot(label='y_buy')
df_train[df_train.index.year>=2022].where(df_train['y_pred_buy']>0,0)['y_buy'].cumsum().plot(label='危険な時間帯を除いたy_buy')
df_train[df_train.index.year>=2022]['y_sell'].cumsum().plot(label='y_sell')
df_train[df_train.index.year>=2022].where(df_train['y_pred_sell']>0,0)['y_sell'].cumsum().plot(label='危険な時間帯を除いたy_sell')
plt.legend()
plt.show()
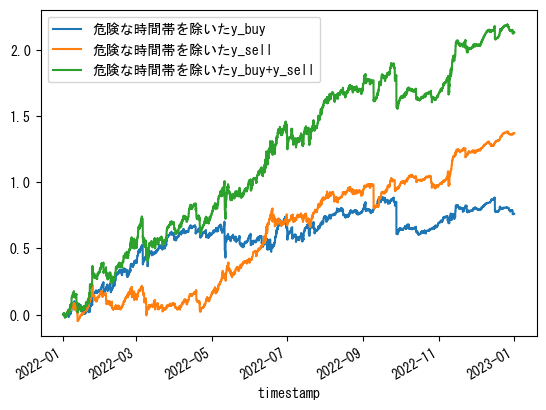
df_train[df_train.index.year>=2022].where(df_train['y_pred_buy']>0,0)['y_buy'].cumsum().plot(label='危険な時間帯を除いたy_buy')
df_train[df_train.index.year>=2022].where(df_train['y_pred_sell']>0,0)['y_sell'].cumsum().plot(label='危険な時間帯を除いたy_sell')
plt.legend()
plt.show()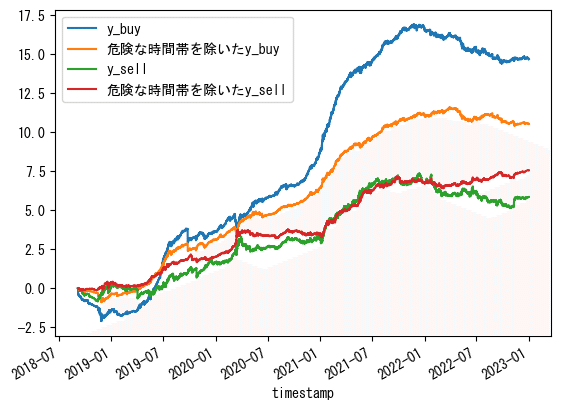
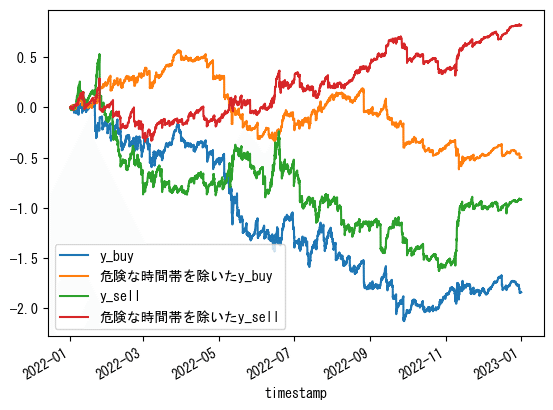
2022年~は良くはなっていますが、あまりピンとこない結果となりました。
下位2%データのy_buy/sellの時間毎合計値フィルタでバックテスト
下位2%データのy_buy/sellについて時間ごとに合計し、下位20時間分を除外して上位4時間分のみを使ったバックテストです。
除外したのは以下の時間帯です。
buy: [0, 1, 2, 3, 4, 5, 8, 9, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 23]
sell: [0, 1, 4, 5, 6, 8, 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
n_excluded = 20
buy_excluded_indexes = (
y_buy_low.groupby(y_buy_low.index.hour)['y_buy']
.sum()
.sort_values()
.index
.to_list()
)[:n_excluded]
sell_excluded_indexes = (
y_sell_low.groupby(y_sell_low.index.hour)['y_sell']
.sum()
.sort_values()
.index
.to_list()
)[:n_excluded]
df_train['y_pred_buy'] = 1
df_train['y_pred_sell'] = 1
for buy_hour, sell_hour in zip(buy_excluded_indexes, sell_excluded_indexes):
df_train.loc[df_train.index.hour == buy_hour, 'y_pred_buy'] = 0
df_train.loc[df_train.index.hour == sell_hour, 'y_pred_sell'] = 0
# プロット部分は同じ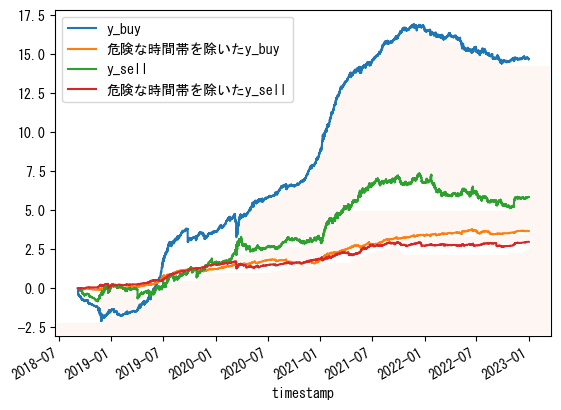
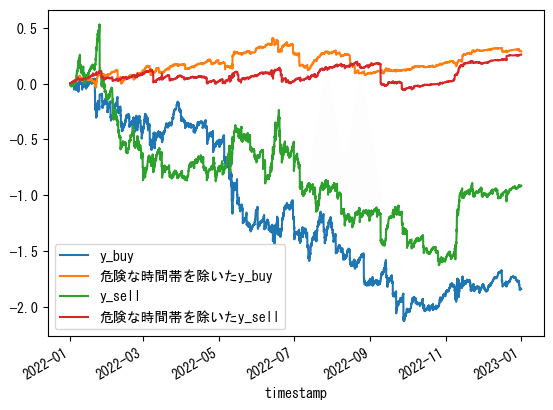
2時間残しとかで2022~2023のy_buyは多少綺麗になりますが、取引回数が少なくなってしまいます。
y_sellは一生綺麗になりません。
全てのデータのy_buy/sellの時間毎合計値フィルタでバックテスト
外れ値に拘るから綺麗にならないんだろうということで、今までの話を全部捨てて、全ての訓練データにおいての時間ごとのy_buy/sellの合計値が上位の時間帯だけを使ってみました。
除外した時間帯は以下の時間帯です。(15時間除外)
buy: [0, 1, 2, 5, 6, 9, 13, 14, 17, 18, 19, 20, 21, 22, 23]
sell: [0, 1, 2, 4, 5, 6, 9, 13, 14, 17, 18, 19, 20, 21, 22]
n_excluded = 15
buy_excluded_indexes = (
df_train.groupby(df_train.index.hour)['y_buy']
.sum()
.sort_values(ascending=True)
.index
.to_list()
)[:n_excluded]
sell_excluded_indexes = (
df_train.groupby(df_train.index.hour)['y_sell']
.sum()
.sort_values(ascending=True)
.index
.to_list()
)[:n_excluded]
# プロット部分は同じ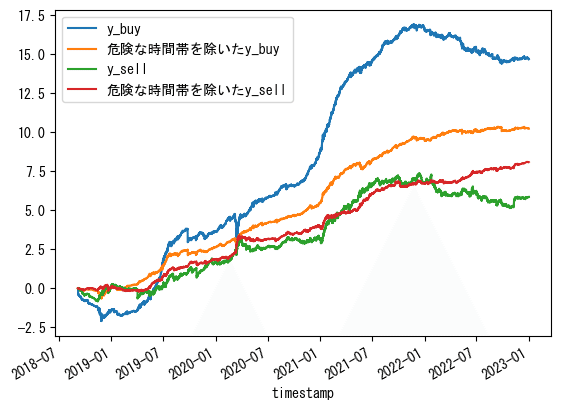
全体の利益は減りますが、今回の目標である「見た目」は良くなりました。
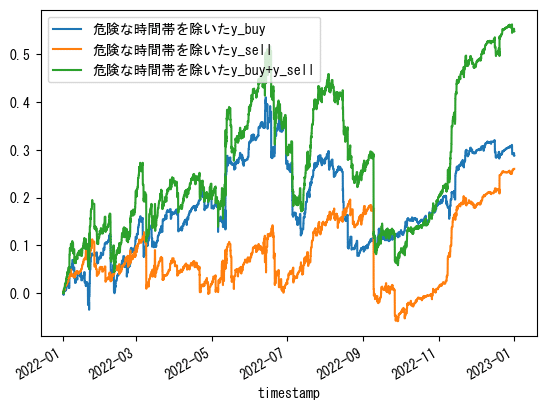
15分毎の時間データも使ってみた
なんか時間帯ごとの合計値フィルタが機能したっぽいので、df.index.minuteで取り出せる0, 15, 30, 45の分のデータも組み合わせてみました。
0~23の情報に15分毎の情報も加えてバックテスト
時間の情報(0~23時)に加え、さらに15分毎の分情報を使ってそれぞれの時間帯ごとのy_buy/sellの累積の上位10個の時間帯のみでバックテストしました。
具体的な処理について、例えば「4:45と15:15と….と23:30の時間のみのy_buy/sellだけを合計する」というような処理になります。
n_excluded = 86 # 0~95(24*4-1)
buy_excluded_indexes = (
df_train.groupby([df_train.index.hour, df_train.index.minute])['y_buy']
.sum()
.sort_values()
.index
.to_list()
)[:n_excluded]
sell_excluded_indexes = (
df_train.groupby([df_train.index.hour, df_train.index.minute])['y_sell']
.sum()
.sort_values()
.index
.to_list()
)[:n_excluded]
# 'y_pred_buy' 列を1で初期化
df_train['y_pred_buy'] = 1
df_train['y_pred_sell'] = 1
# 除外する時間と分の組み合わせに対応する 'y_pred_buy/sell' の値を0に設定
for hour, minute in buy_excluded_indexes:
df_train.loc[(df_train.index.hour == hour) & (df_train.index.minute == minute), 'y_pred_buy'] = 0
for hour, minute in sell_excluded_indexes:
df_train.loc[(df_train.index.hour == hour) & (df_train.index.minute == minute), 'y_pred_sell'] = 0
# プロット部分は同じ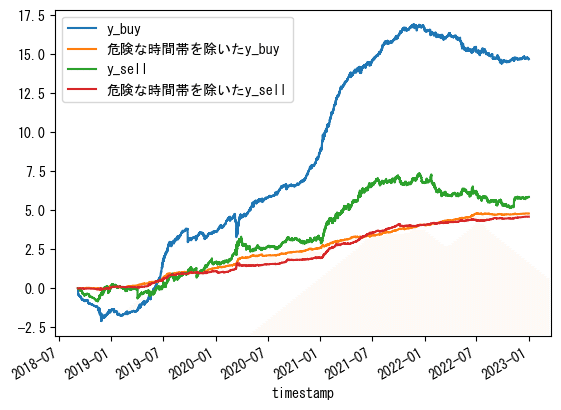
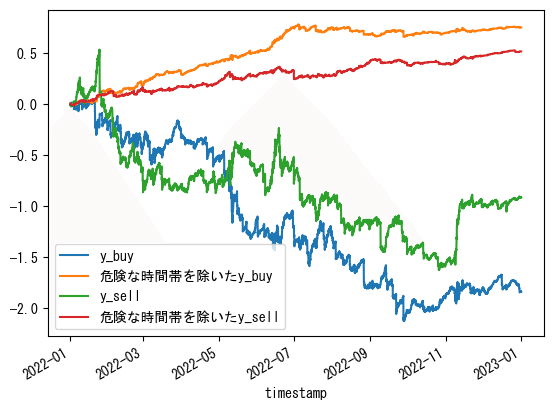
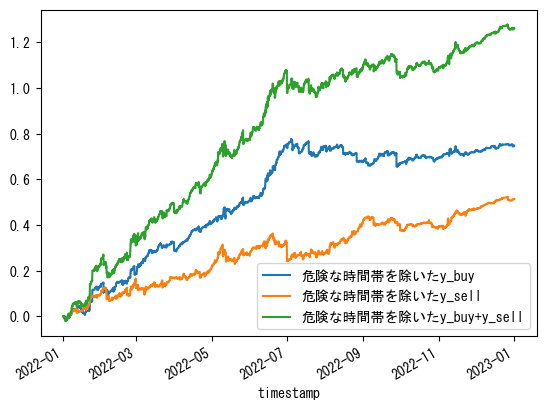
美しくなりました。
テストデータでバックテスト
これまでの検証で、「0~23の情報に15分毎の情報も加えた時間帯毎の合計値フィルタ」が、GMO BTC_JPY15分足のATR0.5戦略においてなんとなく有効であることは分かりました。
ということで、2022-12-31までの訓練用データで作成した時間帯ごとの合計値フィルタを、2023-01-01~2023-11-16のテストデータに適用してみます。
コード省略
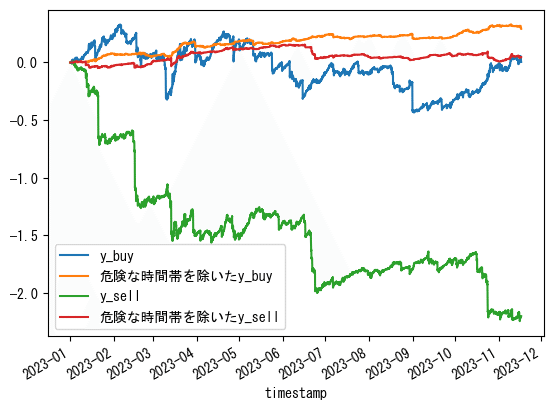
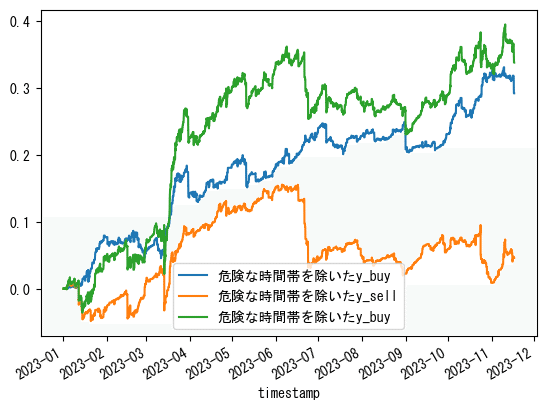
微妙でした。
y_buyだけは良かったみたいです。

ポジション数を考慮したバックテストに通した結果も載せておきます。
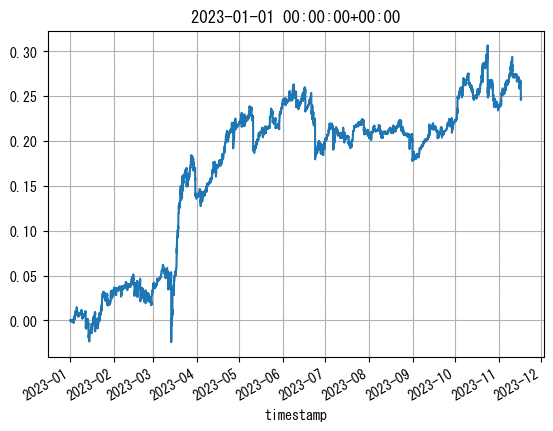
ML投入でワンチャンありそう。
分析おまけ
15分毎まで細かくした時間帯ごとのy_buy/sellの合計値
15分毎まで細かくした時間帯ごとのy_buy/sellの合計値をプロットしてみました。検証したフィルタはこれで飛び出てるやつのbuy/sellそれぞれの上位10個を使っています。
hour_minute_plt_buy = (
df_train.groupby([df_train.index.hour, df_train.index.minute])['y_buy']
.sum()
)
hour_minute_plt_sell = (
df_train.groupby([df_train.index.hour, df_train.index.minute])['y_sell']
.sum()
)
# 時間と分の組み合わせを文字列に変換してラベルとして使用
labels = [f'{hour}:{minute:02d}' for hour, minute in hour_minute_plt_buy.index]
# プロット
plt.figure(figsize=(20, 5))
plt.plot(labels, hour_minute_plt_buy.values, marker='o', label='y_buy')
plt.plot(labels, hour_minute_plt_sell.values, marker='o', label='y_sell')
# x 軸のラベルを調整
plt.xticks(rotation=90)
plt.title('時間帯ごとのyの合計値')
plt.xlabel('時間')
plt.ylabel('yの合計値')
plt.grid()
plt.legend()
# プロットの表示
plt.show()
結構ばらつきがあります。
時間に限らず、15分毎の合計値も調べてみました。
# 各分に対応する値の合計を計算
buy_minute_totals = hour_minute_plt_buy.groupby(level=1).sum()
sell_minute_totals = hour_minute_plt_sell.groupby(level=1).sum()
# プロット
plt.figure(figsize=(10, 5))
buy_minute_totals.plot(kind='bar', label='y_buy')
sell_minute_totals.plot(kind='bar', alpha=0.5, color = 'tab:orange',label='y_sell')
plt.title('15分毎の合計値')
plt.xlabel('分')
plt.ylabel('yの合計値')
plt.legend()
plt.grid()
plt.show()青がbuy側の0, 15, 30, 45分それぞれのyの合計、オレンジがsell側の同様の合計を示したものです。

基本的に1時間のなかで後の方が儲かっているようです。sell側に関しては0分にエントリーするのは辞めた方が良さそうです。
結論、問題点、活用
結論
y_buyとy_sellに時間帯フィルターをかけることで、MLを使わずになんとか右肩上がりになりました🎉
問題点
今回の方法ではフィルタによって取引回数が少なくなってしまうというデメリットが発生します。そして、ここにMLフィルタを追加投入すると、更に取引回数が減ってしまいます。
このチュートリアルbotは、新規売買と決済の時間差が大きくなる(1時間以上空く)ことがあり(執行が新規と決済で全く同じという点も踏まえて)今回の方法ではフィルターを完全に正しく適用できているとは言えません。
活用方法
時間帯フィルタは、指値でボラを取るbotだけでなく、様々なタイプのbotのフィルタとして活用できると予想しています。
また、フィルタを作成する際にある程度の取引回数を残しましたが、もっと時間帯を絞ればきれいな右肩上がりになるわけで、例えばtakeのbotに時間フィルタを適用して、特定の時間だけに取引をするような方向で考えることもできると思います。
あわせてどうぞ
Twitter(新X) 「時間アノマリー」 検索結果
2023年のWSOTで成績を残された方のbotのロジックも時間に関係したものだったと記憶しています。該当ツイートは見つけられず。
その他
windowsであれば、plt.rcParams['font.family'] = "MS Gothic"で日本語が上手く表示できるようになると思います。