
YOLOv8で物体検出をしてみる

YOLOv8を使い、オリジナル画像で物体検出するまでの手順について記述します。環境構築からオリジナル画像でのアノテーション、Pythonでの学習、推論実行までの手順をまとめました。この記事通りに行えば、独自のYOLOv8推論を動かすことができるので、是非チャレンジしてみてください。
■ 事前準備
ここでは Anaconda を用いて環境を構築していきます。また、Pythonのコーディングは VS Code を使用します。よって、事前に Anaconda と VS Code をインストールしておいてください。
■ YOLOv8のインストール
Anaconda Navigator を使って簡単に環境構築します。「Environment」から「Create」で YOLOv8 という環境を作成します。
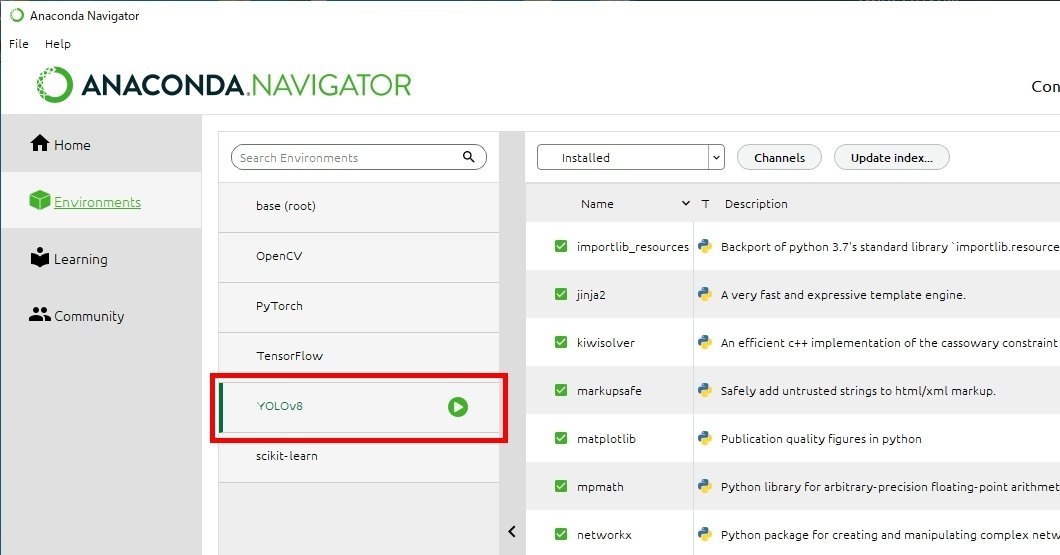
次に ultralytics のライブラリから YOLOv8 をインストールします。先ほどAnaconda Navigator で作成した YOLOv8 の環境から「Open Terminal」を選択し、次のコマンドを打ってインストールします。
conda install -c conda-forge ultralytics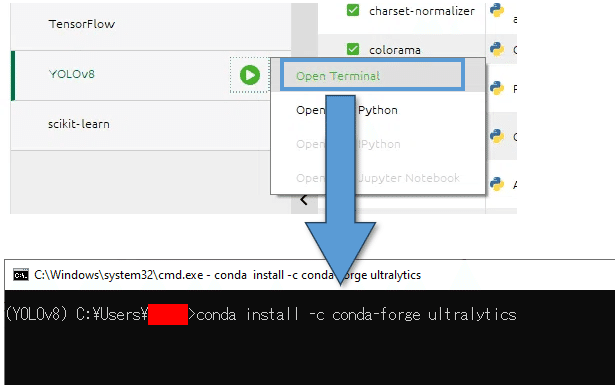
■ ワークスペースの作成
Anaconda Navigator から 起動する VS Code のワークスペースを作成します。ここでは、デスクトップに「YOLOv8 test」というフォルダを作成し、次のようなフォルダ構成にしました。

"_image"フォルダには、予めスマホで撮像した画像を(できれば数百枚以上)保存しておきます。保存した画像は画像エディタソフトでサイズを 640×480 pixelにリサイズしました。
■ labelImgをインストール
画像にアノテーションを行う為のツールをインストールします。物体検出用のアノテーションツールとして、VoTT、labelImg などいくつかのツールがありますが、ここでは labelImg を使います。
【URL】
・VoTT:https://github.com/microsoft/VoTT
・labelImg:https://github.com/HumanSignal/labelImg?tab=readme-ov-file#labelimg
上記 labelImg のURLに記載されているインストール方法に従ってインストールしてください。
最初からEXE形式 (labelImg.exe) になっているものを使用したい方は、こちらからダウンロードしてください。https://github.com/HumanSignal/labelImg/releases
■ アノテーション
labelImgでアノテーションを行います。左のメニューの「Open Dir」で、画像を保存した "./Desktop/YOLOv8/_images" フォルダを開きます。同じく左のメニューで、出力形式を「YOLO」に変更しておきます。検出したいオブジェクトを矩形で囲み、ラベルを付けていきます。今回付けるラベルは「味の素のクノールカップスープ」1種類だけで、「soup」とラベル付けしました。
以下はlabelImgのその他の設定です。必要に応じて設定してください。
・左のメニューの「Change Save Dir」でアノテーションデータの保存先を変更します。
・ 上メニューの「View」→「Auto Save mode」にチェックを入れると、画像を切り替えたタイミングでアノテーションデータが自動保存されます。
・検出したいオブジェクトが1種類の場合、「View」→「Single Class Mode」にチェックを入れます。
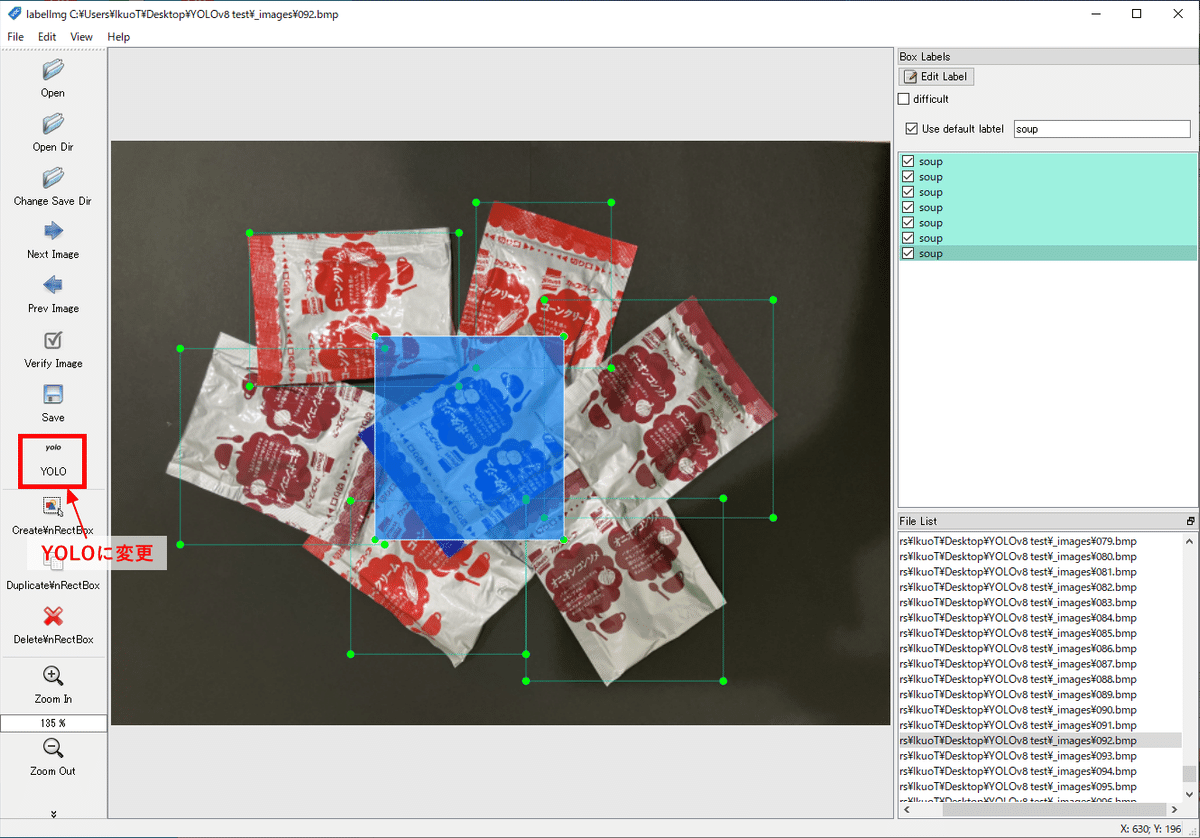
1つの画像に対し、1つのアノテーションデータ(拡張子 .txt)が作成されます。ファイルの中身は左から順に [class number, center x, center y, width, height] となっています。

■ データセットの準備
画像と、画像と対となるアノテーションデータを、学習用フォルダと検証用フォルダにランダムに振り分けます。振り分け比率は「学習用データ : 検証用データ = 7:3 ~ 8:2」くらいにします。
# 学習用データ
./Desktop/YOLOv8 test/_images/01_train
# 検証用データ
./Desktop/YOLOv8 test/_images/02_valid
学習済みモデルの精度を確認するためのテストデータ(※)も用意します。テスト用の画像は、学習と検証に使っていない画像を用意してください。
※この記事では「推論用データ」と呼んでいます。
# 推論用データ (テストデータ)
./Desktop/YOLOv8 test/_images/03_pred最後にデータセットを定義したYAMLファイルを作成します。"dataset.yaml" というファイルを下記フォルダに作成します。
./Desktop/YOLOv8 test/_images/dataset.yaml"dataset.yaml" ファイルをテキストエディタで開き、データセットの情報を記述します。
※ "path:" はフルパスを指定します。
# dataset root dir ※フルパスで指定する
path: C:/Users/(ユーザー名)/Desktop/YOLOv8 test/_images
# training images
train: 01_train
# validation images
val: 02_valid
# prediction images
test: 03_pred
# クラス数
nc: 1
# クラス名
names: ['soup']■ 学習の実行
Anaconda Navigator から VS Code を起動します。
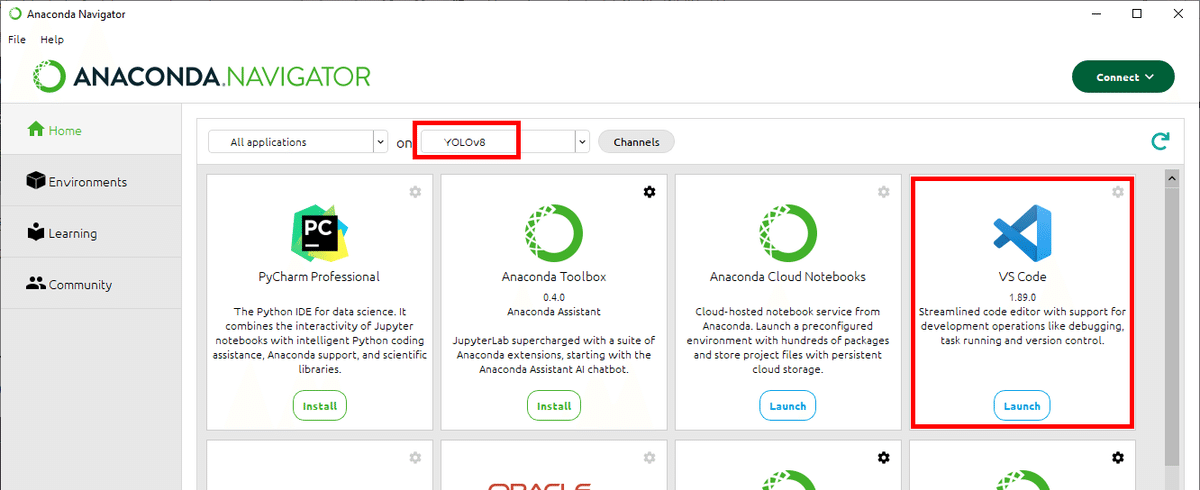
VS Code のメニューの「File」→「フォルダーを開く…」から、ワークスペース ("./Desktop/YOLOv8 test") を開きます。
ワークスペース直下に "CupSoup_Detection_train.py" というPythonファイルを作成します。そして、PythonでYOLOv8nモデルをダウンロードし学習するコードを記述します。
from ultralytics import YOLO
# Load model
model = YOLO('yolov8n.pt')
# Training
yamlfile = "./_images/dataset.yaml"
results = model.train(data=yamlfile, epochs=100, batch=8, imgsz=640, exist_ok=True)
results = model.val()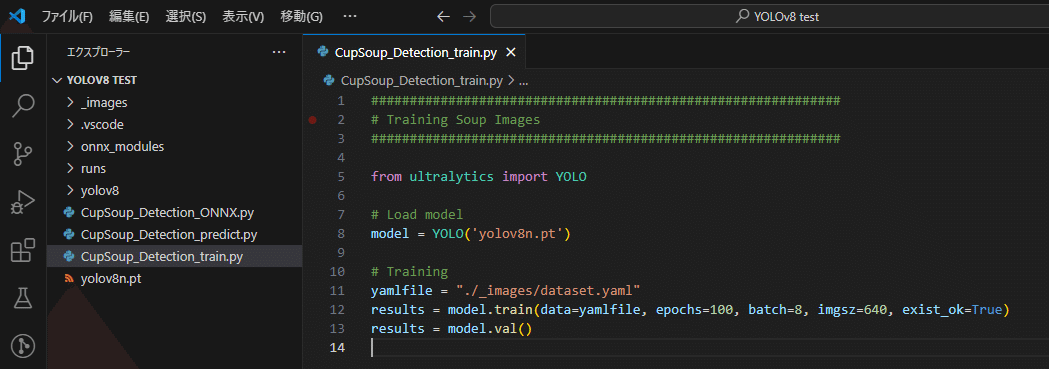
プログラムを実行し、学習を開始します。

学習が終わると結果を確認します。下図にあるように "runs/detect/train" フォルダに結果が出力されています。

"runs/detect/train/results.png" を確認し、過学習が行われていないか等、モデルの精度を確認します。mAP50とmAP50-95が1に近ければ優秀な学習モデルだといえます。train/box_lossよりval/box_lossが下回っていることから、過学習気味かもしれませんが、今回は良しとしましょう。

実際に作成された学習済みモデルは "runs/detect/train/weights" フォルダの "best.pt" です。これ以外にも "last.pt" が作成されていることが確認できます。"best.pt" は最も精度の高いモデルで、"last.pt" は最後に作られたモデルです。
■ 推論(検出処理の実行)
オリジナル画像で学習させたモデルを使い、実際に検出処理を行います。
検出処理用に "CupSoup_Detection_predict.py" というPythonファイルをワークスペース直下に作成し、処理を記述します。因みに検出処理をしたい画像は "./Desktop/YOLOv8 test/_images/03_pred" フォルダに格納しています。また、検出信頼度の閾値は0.8 (conf=0.8) にしました。
from ultralytics import YOLO
# Load model
model_path = "./runs/detect/train/weights/best.pt"
model = YOLO(model_path)
# Prediction
yamlfile = "./_images/dataset.yaml"
test_dir = "./_images/03_pred"
results = model.predict(source=test_dir, imgsz=640, save=True, exist_ok=True, conf=0.8)
プログラムを実行します。結果は "/runs/detect/predict" フォルダに出力されます。

実際の検出結果画像を確認します。背景が異なっても上手く検出できているようです。

■ まとめ
今回学習させた画像の枚数は100枚ちょっとと少なかったのですが、それなりに精度の良い検出ができました。カップスープの素を乱雑に重ね置いても検出できています。ロボットのバラ積みピッキングなどにも使えそうですね。
次回はYOLOの学習済みモデルをONNX形式に変換し、検出を行う方法について紹介する予定です。
↓
追記:記事ができました。こちらになります。
この記事が気に入ったらサポートをしてみませんか?