
Difyに入門してみました

話題のDifyへ入門してみました。入門と言っても、まだ初歩的なフロー構築の部分のみです。
この記事で書いていること
Difyで具体的に何ができるのか?
Difyは何が良いのか?
Difyをどのようにセットアップして動かすのか?
Difyとは
DifyはLLMの実行のワークフローを構築するプラットフォームです。Difyを利用することでノーコードでLLMを活用したアプリケーションを実現できます。
具体的には、チャットボットやワークフローの形式でWeb画面上からLLMに様々な処理を追加することができます。ZapierやPower Automate、(あとBizteX Connectとか)を利用したことある方は、馴染みやすいUI/UXになっているはずです。
Difyは何が良いのか?
(Difyを触ったのは初めてなのにイキって以下想像で書いています)
前提として、ChatGPTやClaudeなどのWebサービスで十分満足している場合は、Difyは不要です。
WebUIのチャットでは不十分である場合、たとえばLLMに対して以下のような追加処理が必要なケースでDifyの価値が実感できるはずです。
## WebUI上のチャットでは不十分で、さらに以下のような追加処理が必要
- 新しい情報への対応
- 複数人での利用
- 状況に応じた柔軟な対応
- 繰り返しの処理
- 不適切な回答の防止上記のように、LLMに柔軟な処理を追加するには通常プログラミングスキルが必要です。この時点でハードルが高いのですが、さらに複数人で利用可能にするには、システム構築スキルも必要でハードルはさらに上がります(*1)。
そこで、Difyのような「LLMの実装と共有」を簡単にするためのサービスがあると便利なはずです。
たとえば、外部情報を参照させたり、質問に応じた対応を分岐させたり、て各種ツールや外部アプリと連携させてから回答を生成させたり、LLMを多段で実行(あるいは複数モデルで検証させたり) と、様々なことができるのでは?と想像しています。
・・・と前置きが長くなりましたが(個人的な見解は最後にチラ裏しておきます)、さっそくDifyを触って行きましょう。
Difyをローカルで利用する
DifyはWebサービスでも利用できますが、今回はローカルで実行するためにDockerを使って試してみます。Dockerのインストールが必要ですが、手順に従えば簡単に実行することができます。
$ mkdir dify
~/dify$ cd dify
~/dify$ git clone https://github.com/langgenius/dify.git
~/dify$ cd docker
~/dify/docker$ tree -L 2
.
├── README.md
├── certbot
│ ├── README.md
│ ├── docker-entrypoint.sh
│ └── update-cert.template.txt
├── docker-compose.middleware.yaml
├── docker-compose.png
├── docker-compose.yaml
├── middleware.env.example
├── nginx
│ ├── conf.d
│ ├── docker-entrypoint.sh
│ ├── https.conf.template
│ ├── nginx.conf.template
│ ├── proxy.conf.template
│ └── ssl
├── ssrf_proxy
│ ├── docker-entrypoint.sh
│ └── squid.conf.template
├── startupscripts
│ ├── init.sh
│ └── init_user.script
└── volumes
├── app
├── certbot
├── db
├── myscale
├── opensearch
├── redis
├── sandbox
└── weaviate
~/dify/$ cp .env.example .env
~/dify/$ sudo service docker start
~/dify/$ docker compose up -d
WARN[0000] The "CERTBOT_EMAIL" variable is not set. Defaulting to a blank string.
WARN[0000] The "CERTBOT_DOMAIN" variable is not set. Defaulting to a blank string.
[+] Running 29/19
✔ api Pulled 254.9s
✔ web Pulled 72.0s
✔ worker Pulled 254.9s
[+] Running 9/9
✔ Container docker-web-1 Started 27.4s
✔ Container docker-redis-1 Started 26.8s
✔ Container docker-weaviate-1 Started 26.9s
✔ Container docker-sandbox-1 Started 26.3s
✔ Container docker-ssrf_proxy-1 Started 27.4s
✔ Container docker-db-1 Started 26.9s
✔ Container docker-api-1 Started 25.4s
✔ Container docker-worker-1 Started 25.1s
✔ Container docker-nginx-1 Started アカウント作成
Dockerが起動したら、http://localhost/install へアクセスするとアカウント作成ページが表示されます。

新規作成
それではDifyを設定するためにまずは「新規作成」ボタンを押下します。
アプリの種別を選択可能です。まずはチャットボットを選択します。

チャットボットの設定
新規作成画面では「LLMプロバイダーキーが設定されていません」と表示されています。

Difyはあくまで、ワークフローを構築するためのサービスなので、各LLMモデルの実行には、GPT-4やClaude3などのAPIキーが必要です。

APIキーなどの設定が完了すると、モデルが選択可能になります。
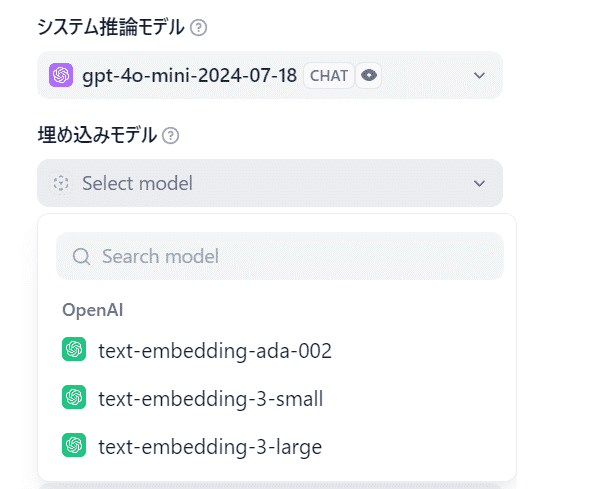
モデルのパラメーターもGUIで設定可能です。
デバッグとプレビュー画面
モデルを設定するとページ右側にデバッグとプレビュー画面が表示されます。
この時点でページ右側のUIからプロンプトを入力可能です。

回答を生成
左側の[手順]にカスタム指示を入力してから実行してみます。

改めて質問を投げると、カスタム指示が反映された状態の回答になりました。

アプリを実行
実際のアプリUIで実行可能です。画面右上の [公開する] → [アプリを実行] で実行が可能です。
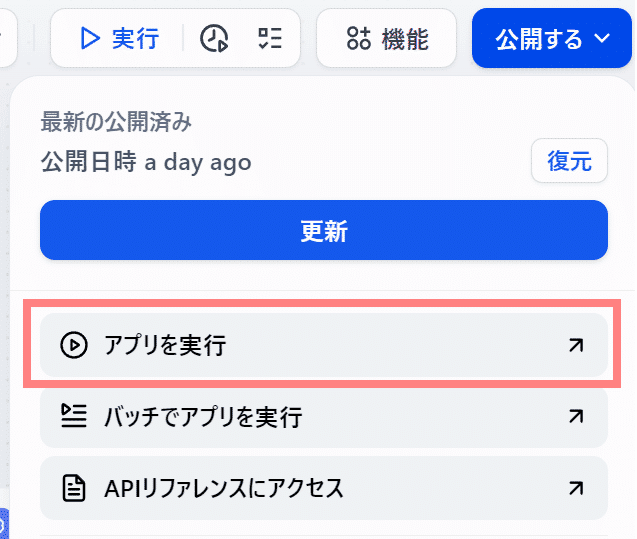
[アプリを実行]を選択後は以下の画面に切り替わります。

[Start Chat]をクリックするとChatGPTっぽい画面に切り替わります。入力すると裏側でLLM (モデルは gpt-4o-mini-2024-07-18 ) でチャットを開始できます。

ここからWebで公開する設定を行えばURLが作成されて他の人もチャットを利用可能になるはずです。
その他の設定
チャットUI画面までは簡単に作成できました。ただし、Difyの便利な特徴として大きいのは、コンテキストが簡単に設定可能なことかなと思います。
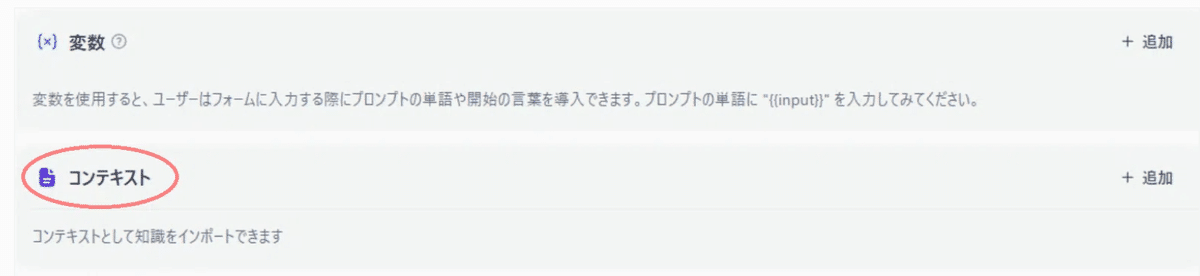
コンテキストで何ができるのか?
コンテキストでは、ドキュメントを添付することで、LLMに追加情報を与えて回答の精度を上げることが可能です。例えば、ビジネスにおける特有の情報を与えることで、その情報を考慮した回答を生成します(*2)。

WebサイトやNotionなどのリンクを同期することも可能です。
テキストの前処理とクリーニング
連携した外部情報に対して、チャンクなどの前処理やVectorStore化などが可能です。

Rerank設定
セマンティックなどの微調整がGUIで可能です。Topやスコア閾値を絞ることで類似度が顕著な場合のみ処理させることができるかもしれません。

このようにDifyでは、コンテキスト追加後に様々な試行錯誤を簡単に実現可能にしていることが重要な特徴といえます(*3)。
・・・この辺はまだ全然試していません。
ワークフロー構築
先ほどはDify上でチャットボットを簡単に構築できました。また、ドキュメントが簡単に追加できること、その後の高度な設定も調整可能なことがわかりました。しかし、これらの追加だけでは、冒頭で述べた以下の対応の実現が難しいかもしれません。
状況に応じた柔軟な対応
繰り返しの処理
そこで、Difyではワークフローを構築することで、より柔軟で複雑な処理を実行することが可能です(たぶん)。具体的にはWeb画面上でフローチャートを記述して設定します。

今回作成したフロー
まずは入力された質問に対して、質問を分類して、その分類結果に基づいてLLMに回答を生成させるシンプルなフローを作成します。
完成したフローは以下です。

実行結果
最初から実行結果です。チャットボットと同様に画面右上の [公開する] → [アプリを実行] で実行が可能です。
実際に実行した結果が以下です。
実行結果1
とりあえず出力にはミネラルの分類が反映されていそうです。

実行結果2
同様に、この出力もミトコンドリアの分類が反映されていそうでした。
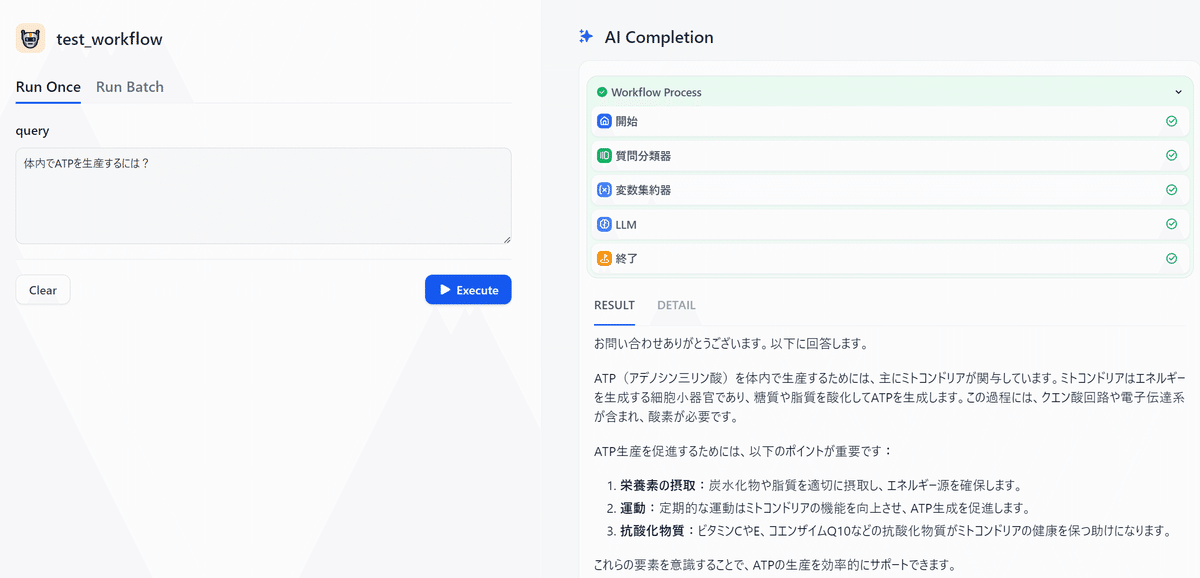
「分類」も「お題」も微妙すぎてアレですが、処理自体はうまくいっている気がします。
ワークフローについて補足
簡単にそれぞれの処理について説明していきます。
質問分類器
LLMの回答の前に入力された文章を分類して、分類毎に様々な処理を追加するために利用します。この質問を分類する処理自体にもLLMを利用します。
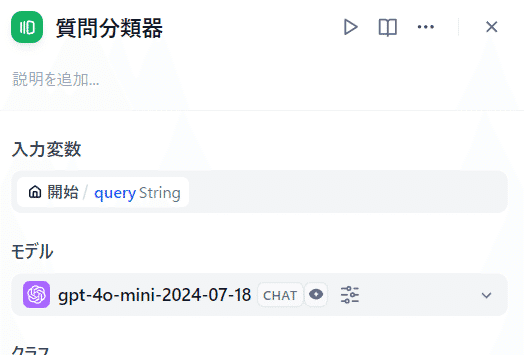
適当に分類(クラス)を設けています(思いつかず微妙なのはすみません)。
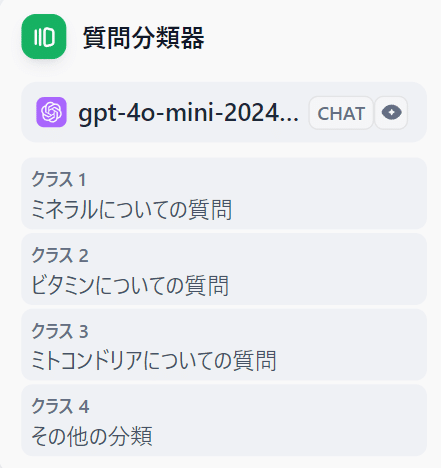
[質問分類器]の設定にも指示の追加が可能です。また後続処理は前段の出力結果を変数にして埋め込みが可能です。

変数集約器
分類器や条件分岐により、分岐が増えていくと、前処理の出力結果に応じた後続処理をたくさん記述しなければなりません。[変数集約器]があれば、処理をまとめることが可能です(たぶん使い方はこれで合っているはず)。

LLM
前段の入力テキストと分類種別を与えて回答を生成します。
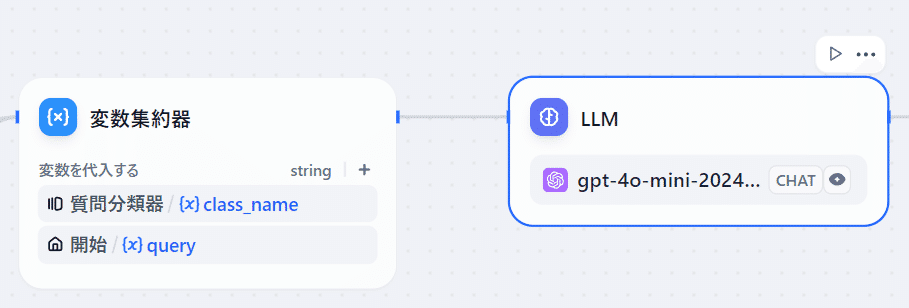
LLMの詳細設定にも、システムプロンプトやコンテキストの追加が可能です。
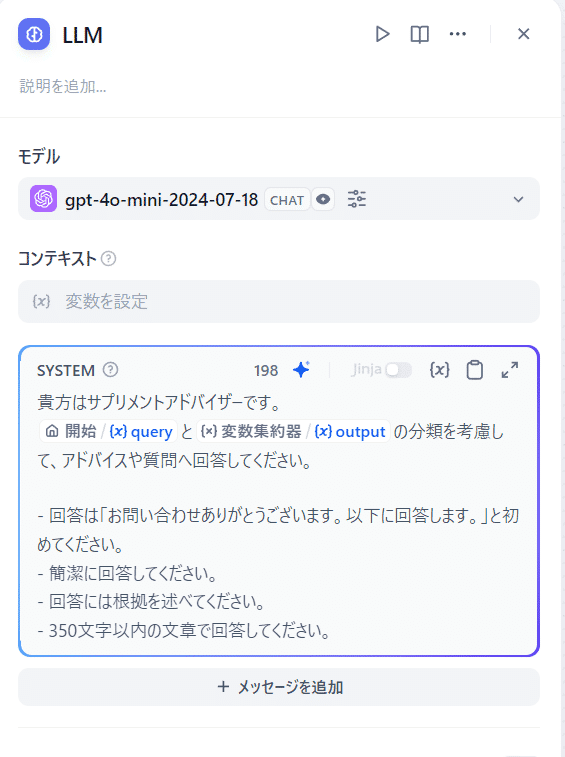
デバッグ画面
フローチャート作成画面では、実際のレスポンス(JSON)の詳細が、画面右側のパネル上から確認できます。

出力がうまくいかない場合は、デバッグ画面の [トレース] からレスポンスを確認して原因を特定します。
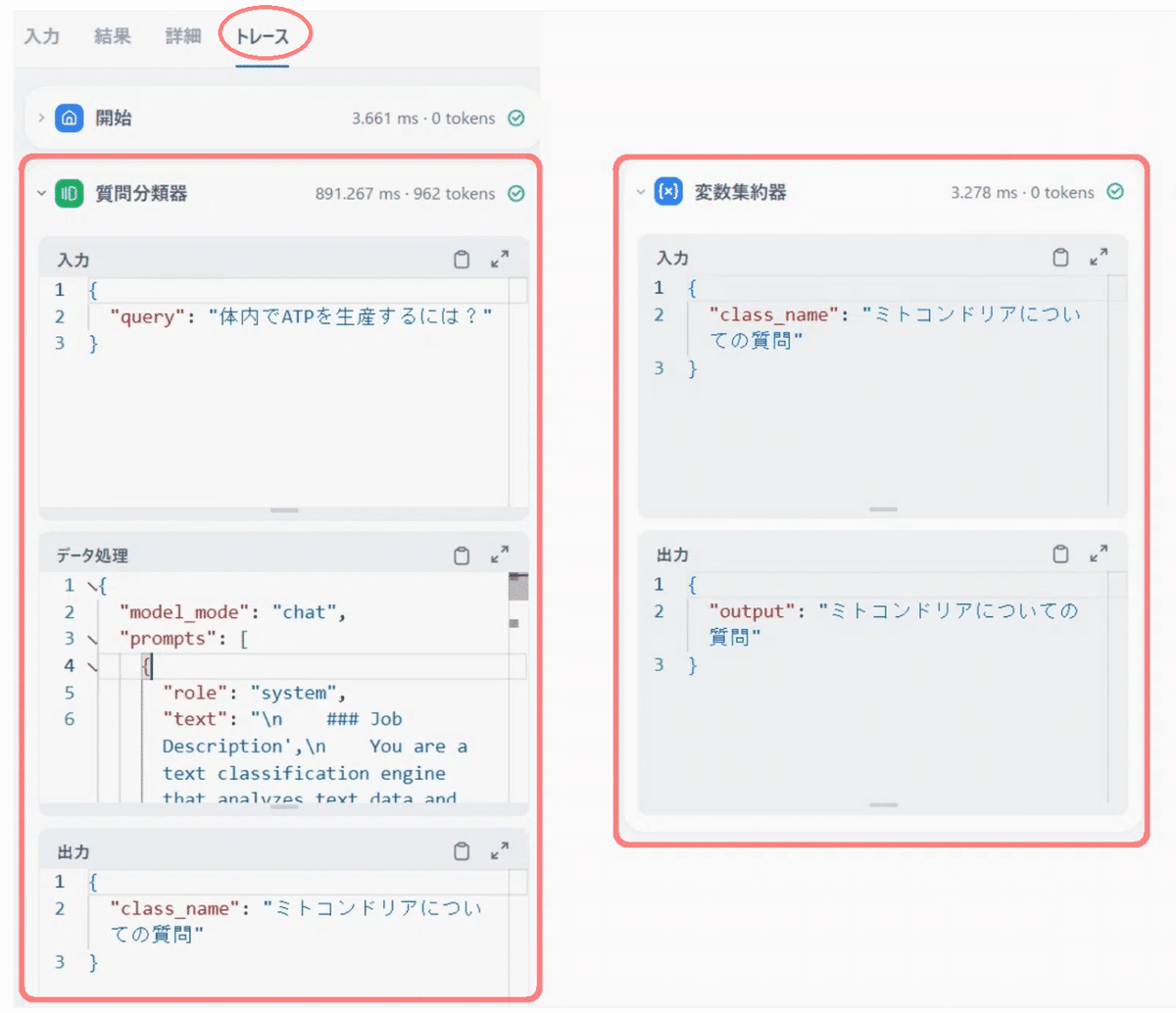
上記の出力結果で適切に分類ができているとわかりました。こんな感じで簡単なワークフローならすぐに作成することができます。
・・・条件分岐と反復処理はパッと記事にかけそうなお題が思いつかなかったので、これは次回に書いていきます。
おわりに
本記事では、Difyの特徴と簡単な設定方法を紹介しました。
特にDifyでは [コンテキスト] を追加できるだけでなく、その後の前処理などを簡単に設定可能にしているのは大きな特徴だと感じています。
個人的には、LangChainやLangGraphなどを学ぶにあたって「設定項目」は初歩的な知見として有益だと感じました。加えて、それらフレームワークで本格的な実装を行う前の「動作検証」にも有効ではないかと感じました(どうなんでしょう?)
最新の開発現場の方にとっては既知で、陳腐化された内容かもしれませんが、Difyの設定項目には、それまで実務で必要とされた「典型的なパターン」が用意されているはずです。設定後にレスポンス結果がどう変化するか?などを把握することは、勘所や限界を知る上で非常に価値があると感じました。
勘所や限界を知る上で「とりあえずやってみる」のハードルが低くなることは今後のLLM発展や社会実装にとっても悪いことではない思いました。
・・・とりあえず条件分岐と反復処理のネタを見つけねばならない。
注釈
(*1) とはいえノーコードツールで実現する際の弊害もたくさんあります。「返って手間がかかってしまった」とならないように注意が必要です
(*2) LLMに外部情報を与えても、期待通りの結果が得られるわけではありません。それどころか、かえって的外れな回答になる可能性もあります。幻覚については最新の論文[1]でも課題とされており、この点については試行錯誤→コントロールできない部分を見極めて、回答させない工夫[2]や利用シーンに合わせてちょっとした利便性(及第点な使い方)の模索が必要だと感じています。
確信度に関する重要そうな知見(メタレベルの指示解釈)
画像認識等の分類問題を深層学習で解かせるとき、普通は最もconfidenceが高いクラスを解として出力するわけですけど、confidenceが絶対的に高いかどうかは考慮されないんですよね
— takeo (@bonotake) August 9, 2024
解のconfindenceが低い場合は除外する、といった処理は別にやらないといけない
それと同じ理屈だと勝手に解釈してました
プロンプトで自己認識を活性化させる的な・・なるほど・・・
それは、LLMがプロンプトに書かれたメタレベルの指示を解釈可能だからじゃないですか
— takeo (@bonotake) August 9, 2024
プロンプトに書かれないことは意識しないかもしれないが、プロンプトに書かれると、そこに含まれる範囲で自己を認識できてしまう、というか
また、四則演算の問題が苦手[3]な状況は最新モデルでも残っています(一方で、算数や数学問題については隠れた推論プロセスを内部に持っている可能性を示唆[4]する研究もあるようで面白い)。
[1] Training Language Models on the Knowledge Graph:
[2] LLM Internal States Reveal Hallucination Risk Faced With a Query
[3] GPT-4による足し算実験から示唆されるLarge Language Modelsの課題
[4] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
(*3) 試行錯誤が簡単になったことで初めてスタートラインに立てます。そのことで誰でも実現可否を検証できるようになったのは重要だと感じました。
この記事が気に入ったらサポートをしてみませんか?