
update:機械学習で競馬を予想しよう(プログラミング超初心者向け)/前準備編

2022/3/22に記事をアップデートしました。疲れた・・・
私は昭和生まれでプログラミングとはかけ離れた職業に就いているのですが、近年の競馬AI(ほとんどが機械学習でしょうが)の活躍ぶりに「よし、俺も参戦だ」とちょっと間違った方向に尽力してしまい何故か昭和生まれのおっさんが機械学習で競馬を攻略する、という記事を書くはめになりました。
構想1年、実際の実装に1年半くらいです。
何故機械学習なのかというと、競馬予想していて「穴の本命が来た!」→紐抜けが余りにも多くて人気でもキッチリ来る馬を予想すべきだなぁと2月の仕事がない時期に5万負けて実感したからです。死んじゃう。
まずは下調べをしなければならない。
昭和生まれのおっさんがいきなりPCを立ち上げプログラミングなんぞ出来るわけがない。
Googleで検索をかけまくり「python 競馬 儲かる」「python 初心者 億万長者」と検索しまくって浪費する日々を過ごしながら少しづつpythonと機械学習に向き合う日々を過ごした結果

中々に優秀なものが出来たかな、と思ったので記事にしました。
ただこれはあくまで試験段階。実際に昭和生まれのおっさんが機械学習が出来るまでを書いてみます。
何はなくともデータが必要だ
というわけで機械学習するにはデータが必要な訳で、数秒考えたのですが私が今使っているTARGET Frontierでどうにかなるんじゃないかと思ったわけで。詳しい情報は後述しますが、JRAが有償で配布しているデータを分かりやすくソフトに取り込んで予想できる予想支援ソフトです。かなり有名。
というわけでここではTARGET Frontier JVのユーザー向けに機械学習が出来るような記事を書いていきたいと思います。無料でやっている方はもう少しお待ち下さい。ただ忠告しておきますがhtmlやRなどの知識等がないと実装段階、将来的に詰みます。
何故TARGET Frontier JVユーザー向けなのか
昭和生まれ、PCを触れる競馬ファンの方は大体TARGET本体に様々なデータを入れていると予想しました。レース印を始め馬印やコメントなど人によって森羅万象なデータを投入していると思います。それをなるべく無駄にしないようにこれから機械学習の基礎中の基礎「前処理」をハードルの低い方法でしていきます。「分からねえぞ!」という人はGoogle検索しましょう。因みに「競馬初心者がPythonで機械学習した結果、回収率が100%超えました」みたいな記事はPythonの入り口としては読む価値はありますが、慣れてくると「これ、役に立たねえな」とすぐに気づきます。
私の目的は「機械学習」を「競馬ファン・特に40代くらい」に浸透させてゆくゆくはオッズを適正化する為です。大きすぎてちょっと良く分からない目標だ。
注意:ある程度excelの知識がないと苦しみます。なるべく細かく説明しますが、あしからずご了承を。
機械学習に必要なデータを出力する

TARGETを立ち上げたらレース検索をクリック
レース検索条件検索設定の「レース条件」タブは芝、ダートをチェック
障害戦を除外するためですね。

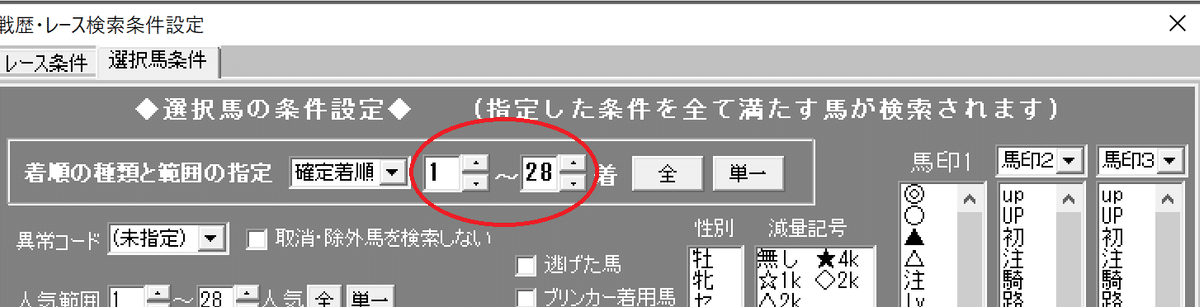
選択馬条件は1-28を選択。近年のデータを使う想定なので18でも良いはず。

機械学習で使うデータは多いほど良いみたいな風潮なのですが、少しやってみると多いほど良いのは特徴量(予想するための項目、競馬で言うとオッズとか騎手とか種牡馬とか)と個人的には思います。
検索を実行しましょう。
今回は2022年の3月3日から2019年の1月1日までを検索します。
何故この期間かというと単なる勘です。
機械学習の目安が確か過去3年が良いみたいな記事をどこかで読んだだけなので将来的には年数を増やしても良いと思いますが、中京競馬場の馬場改修が2012年の1月に終わっていますので2013年くらいまでが良いのではないでしょうか。
さて検索には結構時間が掛かりますが気にしてはいけません。
データ分析には我々のような中古PCユーザーには時間がかかるのものです。お茶でも飲んで一服しましょう。


レース検索が終わったら★1を選んで項目を画像のように追加して上画像の馬データ読み込みと前走成績を読み込みます。
項目は着順じゃなくて確定着順を選ぶこと。あとから説明しますが面倒になるので。何故この項目にしたのかも実際にコードを書くときに分かります。
★1はあくまで例ですので★3でも★4でも良いです。
時間がかかるのでカップラーメンでも食べましょう。
2022/03/22追記、通過順1-4が入っているのに気づいたので画像を差し替え。出力した方はCSV開いて直接削除したほうが楽かもです。


2022年3月3日から2019年の1月1日までレース検索をすると上記のような画面になるかと思います。

出力をクリックして

画面イメージ(CSV形式)をクリックするとCSV形式でTARGETをインストールしたフォルダ内のTXTフォルダ内に出力出来ていると思います。

私はDドライブにTARGETをインストールしているのでこのような感じですが通常はCドライブにインストールされていると思います。
私はTFJVフォルダ内のTXTフォルダに今回はnoteseiseki.csvという名前で保存しました。ファイル名はなんでも構いませんが日本語は辞めておいたほうが良いです。たまに読み込まなくなりますし、機械学習に興味が出てさらなる開発を行うなら英語にしておきましょう。(私の環境だけかもですが)
この項目名の変更はPythonで出来ます。次回にでも。過去データ検索はこれで終了。
次にTARGETの出馬表を出力します。出馬表分析をクリックして


オッズ・結果読と前走読をクリックして読み込んだあとに上のレース検索後の出力時に設定した★1の項目を探して同じように設定します。画面下の出力でCSVを出力しましょう。CSV形式出力選択メニューの画面イメージCSV出力ですね。私はsyutsuba.csvという名前で出力しました。何故出馬表分析画面かと言うとお手軽だからです。これも次回くらいに説明します。

2022/3/22追記。前処理段階のコードに致命的なミスを発見したので下記手順を追加してください。
追記・競馬には種牡馬という予想家さんによってはメイン武器になり得るものがございまして。これを機械学習で使う場合、通常なら
df_pre = pd.get_dummies(df_pre, columns = ['種牡馬'])とダミー関数の1行で済ますことが多いのですが、競馬ファンの方ならご存知と思いますが種牡馬は数が多いんです。
これを上記のダミー関数でやると6000とか8000とか項目名が増え、我々のような中古PCユーザーのPCでやると爆発してしまうかもしれません。
爆発は無いでしょうが後々の処理がとんでもなく重くなることが目に見えており、やる気を削がれビールを呷る事になります。なので後述のコードではラベルエンコーディングで解決しようと思ったのです。ラベルエンコーディングとはなんぞや、という疑問はこちらを参照していただくとして簡単に説明すると
種牡馬名・ディープインパクト 1
種牡馬名・キングカメハメハ 2
といった感じに数値化していく処理方法なのですが、落ち着いて考えると
成績データの種牡馬数と出馬表データの種牡馬数が違いすぎる事ともう一つはちょっと専門的な話なのですが、別々のファイルでラベルエンコーディングを施した場合、数値化処理の整合性が取れるのか分からないという問題がありました。
私はこの記事を公開した翌日に「あ、これマズいな」と思って即修正記事を書いていたのですが

具体的な指摘をTwitterのDMでいただきまして、あれこれどうしようかと思っていましたがようやく解決したので修正記事を書くことにしました。
指摘いただいた馬券太郎@keibataro1さん、ありがとうございます。
皆さん馬券太郎さんのtwitterをフォローするように。
というか酒を飲んでコードを書くものではない。バカなの?この記事書いた人。
だいぶ前置きが長くなりましたが、追加手順に行きます。
TARGETメニューの種牡馬をクリック

次に検索対象年齢を2-30にする。何故かと言うと勘です。

追加読込押した後に下部出力をクリックして、基本データ一覧を選んで出力。ファイル名はbloodにしました。基本的に先に出力したファイル名も好みで付けていただいて構いません。その時はコード内のファイル名も変えてください。

はい、ここでひと手間掛けます。

私の環境だけかもですが、データにヘッダーが無い。このままだと機械学習出来ないので・・・

セルを一番上に挿入して画像のように入力してください。
この作業が面倒くせえという人はこことか参照してコードを回せばいいと思いますが、サイズも軽いしお手軽なので私はこの方法で。
正しく出力が出来たらTARGETは閉じて構いません。
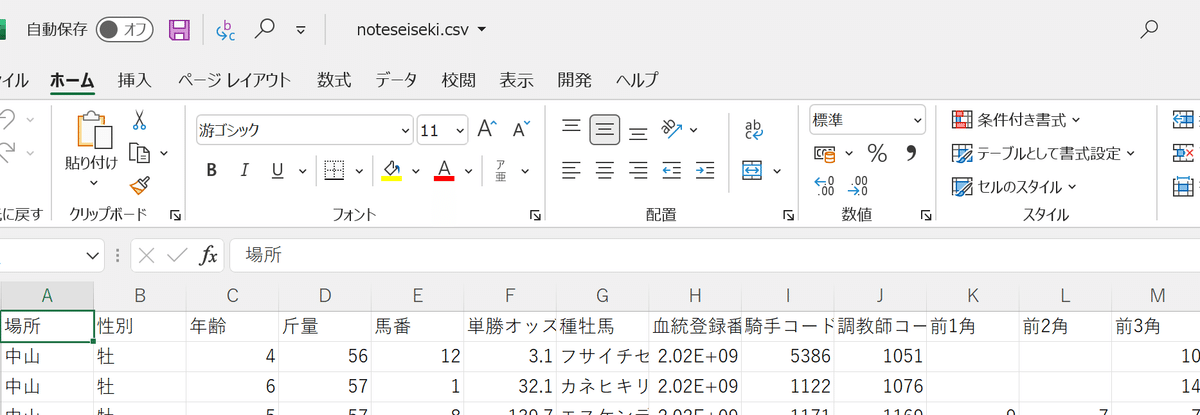

CSVファイルを表計算ソフト(Excelでもなんでも良い)で開いてみるとこんな感じ。あ、言い忘れましたがCSVはファイル形式を
画像のようにしておいてください。

さてここで機械学習において最も大事なことのひとつを言います。
それは学習データ(ここではnoteseiseki.csv)と実際に予想するデータ(ここではsyutsuba.csv)の出力項目名が一致しているか、です。学習するデータと予想するデータが異なるとエラーが起きたりします。(ドメインシフトとか言った気がしますが、良く覚えていない)
なのでここでは一致させておきます。何も考えず、「項目を一致させる」「項目を一致させる」と「目標をセンターに入れてスイッチ」みたいな集中力で行ってください。要は数学の勉強をするのに数学と国語と物理の教科書を持って勉強するような感じです。はい、自分でも何を言っているのか分かりませんがとにかく学習データと予想するデータの項目名は同じにしておきましょう。何故と考えてはいけません、おまじないです。数学で1+1は2ですが哲学を加えるともしかして2じゃないんじゃ・・・?とか考える人達もいますが機械は哲学を持たないのでこれで良いのです。
さてCSVの出力が終わったので、いよいよ前処理、Pythonを使ってCSVを処理していきます。
まずは環境を構築することが大事です。
私はanacondaを使用しています。
詳しくはこちらを参照。
Windows版Anacondaのインストール: Python環境構築ガイド - python.jp
anacondaが導入できたらwindowsのスタート(windowsマーク)をクリックしてみるとこのような項目があるかと思います。

ここのJupyter Notebookを使って実際にCSVの前処理をしていきます。
Pythonをある程度使っている人、慣れている人は個人の環境に合わせてください。Google Colobでも良いと思いますが、私の環境だとコードが上手く動かなかったりします。
まずはanacondaを起動しましょう。Anaconda Power shell Promptです

まずはanaconda本体のアップデート。
conda update -n base conda次はanacondaの全パッケージのアップデート
conda update --allはい、anacondaの準備は完了ですので閉じましょう。
さてここで注意点ですが、ありのままでanacondaを使おうとするとanacondaの作業場所はローカルディスク→ユーザー→ユーザー名のフォルダ(例えばtetorakeiba、パブリックみたいに別れているかと思います)が作業フォルダ、(カレンディレクトリとかいいます)になるのでそこに先程出力したCSVをコピーしておきましょう。
そしてJupyter notebookを起動。

NewをクリックしてPython 3を選択(3は私の環境です、個人個人で違うと思います)
追記・コードを追記しています。前とは若干違うので注意。
pd.read.csvでCSVを読み込みます。
import pandas as pd
import numpy as np
#df_preは成績データ/skipinitialspaceは前後の空白を無視する意味、df_seisekiとかでも良いです
df_pre = pd.read_csv('noteseiseki.csv'
, dtype = 'object'
, encoding = 'UTF-8'
, skipinitialspace = True
)
#df_testは予想したいデータ、df_syutsubaとかでも良いです
df_test = pd.read_csv('syutsuba.csv'
, dtype = 'object'
, encoding = 'UTF-8'
, skipinitialspace = True
)
#種牡馬データ読込
df_blood = pd.read_csv('blood.csv'
, dtype = 'object'
, encoding = 'UTF-8'
, skipinitialspace = True
)種牡馬データを使って成績データの種牡馬名をキーにして種牡馬データの血統コードを返すカラムを作成する
#noteseisekiの種牡馬データ処理・こちらが修正部分
#成績データに対して、同一のキーを持つカラムを作る:カラム名は血統コード
df_pre.insert(2,'血統コード', df_pre['種牡馬'])
#先程作った、カラム名のキーと同一のキーを持つ「血統コード」の行を挿入
df_pre['血統コード']= df_pre['血統コード'].replace(df_blood ['父名'].to_list(), df_blood ['血統コード'])
print(df_pre)
同じようにdf_testも種牡馬処理。
#syutsuba.csvの種牡馬データ処理・こちらが修正部分
#出馬データに対して、同一のキーを持つカラムを作る:カラム名は血統コード
df_test.insert(2,'血統コード', df_test['種牡馬'])
#先程作った、カラム名のキーと同一のキーを持つ「血統コード」の行のデータを当て込む
df_test['血統コード']= df_test['血統コード'].replace(df_blood ['父名'].to_list(), df_blood ['血統コード'])
print(df_test)そして成績データと出馬データの項目名を変更
#成績データの項目名を英語表記に変更
df_pre = df_pre.rename(columns={'場所':'place','性別':'sex_type','血統コード':'b_code','年齢':'age','斤量':'weight','馬番':'h_num','単勝オッズ':'odds',
'種牡馬':'blood','血統登録番号':'h_num','騎手コード':'jockey_code','調教師コード':'train_code',
'前1角':'rank1','前2角':'rank2','前3角':'rank3','前4角':'rank4','確定着順':'order',
'前走決め手':'b_legtype','前走上り3F順':'b_3ftimerank','前走人気':'b_pop'})
df_pre.info()#項目名を英語表記に変更、出馬表は項目名が独特なのでここで綺麗に整理/この問題はTARGETを使う限りつきまといます
df_test = df_test.rename(columns={'場所':'place','性':'sex_type','血統コード':'b_code','齢':'age','斤量':'weight','馬番':'h_num','単オッズ':'odds',
'種牡馬':'blood','血統登録番号':'h_num','騎手コード':'jockey_code','調教師コード':'train_code',
'前通過1':'rank1','前通過2':'rank2','前通過3':'rank3','前通過4':'rank4',
'前走決め手':'b_legtype','前3F順':'b_3ftimerank','前人気':'b_pop'})
df_test.info()TARGETでCSV出力すると項目名に相違があるので表記を合わせて同じデータになるように整形。TARGETのデータを触ってみてベスト3に入る苛立ちでしたね。
例:成績データ:性別、出馬表分析データ:性
まぁこうする理由が色々あったんだろうなぁとは思いますがここで躓く人は大勢いると思います。
この項目名で目を引くのは騎手コード、調教師コード、血統登録番号辺りと思うのですがこれはそれぞれ
騎手コード:TARGET内で表記される騎手の識別番号
調教師コード:TARGET内で表記される調教師の識別番号
血統登録番号:TARGET内で表記される馬ごとの識別番号
と捉えておいてください。
機械は数値とカラム名でしか判断がつかないのでこの方式を取っています。
2022/3/22追記・コード修正
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
#ラベルエンコーディングで性別を変換
le.fit(df_pre['sex_type'])
df_pre['sex_type'] = le.transform(df_pre['sex_type'])
#成績データを整形
df_pre['b_legtype'] = df_pre['b_legtype'].map({'逃げ':1, '先行':2, '中団':3,'後方':4,'差し':5,'マクリ':6,'追込':7,'不明':8})
df_pre['place'] = df_pre['place'].map({'札幌':1,'函館':2,'福島':3, '新潟':4, '東京':5, '中山':6, '中京':7, '京都':8, '阪神':9, '小倉':10})
#斤量の印を外す
df_pre['weight'] = df_pre['weight'].str.extract('(\d+)', expand=False)
# オッズが数値以外のものを置換
df_pre["odds"] = df_pre["odds"].replace("---.-", np.nan).astype(float)
#欠損値を0で穴埋め
df_pre.fillna(df_pre.fillna(0), inplace=True)成績データを整形。欠損値は今回は0埋めしていますが機械学習の手段によっては削除、除外したほうが良いときもあるのでそのときは
# 欠損値があるレコード除去
df_pre.dropna(how='any', inplace=True)
#df_preの部分は自分の環境(保存するファイル名)に変えてくださいこちらで良いかと思います
さて出馬データも整形。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
#ラベルエンコーディングで性別を変換
le.fit(df_test['sex_type'])
df_test['sex_type'] = le.transform(df_test['sex_type'])
#出馬表データを整形
df_test['b_legtype'] = df_test['b_legtype'].map({'逃げ':1, '先行':2, '中団':3,'後方':4,'差し':5,'マクリ':6,'追込':7,'不明':8})
df_test['place'] = df_test['place'].map({'札幌':1,'函館':2,'福島':3, '新潟':4, '東京':5, '中山':6, '中京':7, '京都':8, '阪神':9, '小倉':10})
#斤量の印を外す
df_test['weight'] = df_test['weight'].str.extract('(\d+)', expand=False)
# オッズが数値以外のものを置換
df_test["odds"] = df_test["odds"].replace("---.-", np.nan).astype(float)
#欠損値を0で穴埋め
df_test.fillna(df_test.fillna(0), inplace=True)続いてデータ内の種牡馬名を削除。種牡馬は血統コードで判別されるので問題なし。
#機械学習くんは日本語、英語を読み取れないので種牡馬名の列を削除
df_pre.drop(['blood'], axis=1, inplace=True)#出馬データも種牡馬名の列を削除
df_test.drop(['blood'], axis=1, inplace=True)さて最後の仕上げ。これ忘れてた
# データフレーム全体の型を変更/ここでエラー出るならcsvのデータに英字などの文字が含まれている可能性大
df_pre = df_pre.astype(float)# データフレーム全体の型を変更/ここでエラー出るならcsvのデータに英字などの文字が含まれている可能性大
df_test = df_test.astype(float)データフレームの型をfloatにしておきましょう。何故なのかというと浮動小数点を扱う必要があるからです。気づきましたね、そう分からない単語はググりましょう。Python floatとかで検索です。
ここまでで前処理編は終了。
ここからは補足編をコピペした機械学習豆知識になります。
Pythonで私が躓いた一因はコードがエラーを起こす、というものでその原因は大体CSVの内容に日本語が含まれていることです。
競馬データ、JV-LinkやJRDBは日本語表記が多く含まれていますし機械は数値しか読み取れないので、日本語表記を数値などに変換してあげる事が大事です。
df_pre['b_legtype'] = df_pre['b_legtype'].map({'逃げ':1, '先行':2, '中団':3,'後方':4,'差し':5,'マクリ':6,'追込':7,'不明':8})このコード辺りがまさにそうなのですが、TARGET Frontierは兎にも角にもレース検索後の表記と出馬表の表記が違いすぎて何度頭を掻き毟った事か。

なので他の項目を追加してあげるときは、そこら辺も考えてあげないといけません。出馬表分析画面に間隔の項目でも入れてみますかとなるとデータのどこかに「初走」とか「連闘」とか入っています。こいつのせいでエラーが出て何だこれは、となりビールを呷る事になります。
じゃあこいつをコードで修正するか、と書いてみたのですが何度やっても半角空白を挿入しやがってエラーを起こしビールを呷る事になります。
私の環境なんでしょうけどね。じゃあどうするか、というと。
CSV開いて置換すれば良いじゃないとなりますわね。面倒だけど。
将来的にTARGETから出力→データベースにして色々とやろうとした時にCSVでコードで動かしてエラーになる最も多い原因がTARGETから出力したデータには意味のわからないところに半角スペースが挿入されている事です。
何度も経験しています。TARGETの馬印を試しに項目に追加して「あれ、処理が何だか変だな」と思ったら馬印の後半部分に半角スペースが鎮座していたとかありましたねぇ。それに気づいた時は流石にブチ切れてビールを3リットル飲みました。
df_pre['間隔'] = df_pre['間隔'].map({'初走':9999, '連闘':0})とここまで書いてふと思ったけど、上記のコードで良いんじゃないだろうか。試す余裕はない。初走には新馬戦も含まれるだろうし、予想するデータからは削除しておいた方が無難な気もします。私は新馬戦だけは機械学習じゃなく、まるっきり違う方法で予想しています。厩舎、血統、騎手は一切考慮していません。まぁ条件が合わないことが多いので買う機会は少ないですが。話が脱線しましたが「これをやりたいがPythonが分からん」って人はCSVの状態で文字を数値に変換しておくのも良いかもしれません。エクセル使える人だとXLOOKUP関数とかは役に立つんじゃないでしょうか。まぁ.mapで大体の変換は可能なはずです。馬コメントとか使っている人は馬印を利用してあとから一気に置換するのも良いかもしれないですね。
はい。長々と前処理部分の補足をしましたが、分からない事は大体ネットに転がっています。検索しましょう。Pythonのコードはじっくり読むと完全文系の方が読み取れるはずです。あとはおまじないを覚えましょう。
.mapは置換、.replaceは文字列操作・置換とか。
エクセルでコツコツ色んなデータを数式とかで弄っていたであろう世代の方なら覚えられるはずです。
そういえばTARGETのレースIDについてですが、出力する時にTARGETの環境設定からCSV出力設定でコードの先頭に記号をつけるにチェックしておいた方がCSVにしたときに綺麗に読み取ってくれるはずです。
特にエクセルで何かしらデータを弄ってCSV形式で保存した時にレースIDの数字部分が確か全部ゼロになってた気がします。なので先頭にRXを付けて出力して出馬表データの整形時に
#レースIDの先頭RXを削除
df_test['raceid'] = df_test['raceid'].str.strip('RX'"")上記のコードで一気にRXだけ削除できます。他にも応用できますので覚えておいて損は無い・・・と思います。たぶん。
#前レースIDの英数字を削除/上手いコードが思い当たらなかった
df_test['b_raceid'] = df_test['b_raceid'].str.replace('A',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('B',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('C',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('K',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('M',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('F',"")
df_test['b_raceid'] = df_test['b_raceid'].str.replace('G',"")
そういや前走レースIDにはたまにアルファベット君が同伴していますので上記コードの応用で消しましょう。確か上記のアルファベットだけと思うのですが、将来的に増えるかもしれません。これはJV-Linkのせいです。増えたらコードをコピペして貼り付けて少し変える。おっさん初心者プログラマーの必須スキルです。
さて一気にCSVの前処理と補足記事まで進めたのですが、実際に予測してみる、の記事読みたいですか?
コードとしてはあと30行くらいです。
お金取っちゃうか・・・?とか私の中の悪魔が囁くのですがまぁ無料で出すと思います。ただ今は気力がない。
因みにここまで前処理していると、あとは予測モデルを作るだけで自分で出来る人もチラホラいると思います。ここから特徴量増やしたらまた違いますが。
願わくば昭和生まれのおっさん馬券師の一助になることを祈って記事を締めたいと思います。
ここまで読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?