数値予報とは その3 観測データから初期値を作成する(データ同化)

点の情報から面、そして3次元格子の情報へ
数値予報では、流体力学や熱力学の方程式などから各格子で時間刻みΔt時間での物理量の変化量を計算し、時刻tでの値に変化量を加えることでt+Δtでの値を求める、と次々と計算することで、24時間後、72時間後、さらには120時間後の値を求めます。24時間後の各格子の値が求まれば、それを用いて例えば地上の予想天気図も描くことができて、天気予報に使える資料となります。
初期条件が各格子で与えられれば、このように未来の値を計算できるのですが、時刻0での値をどう決めるか、これが実は重要な課題です。数値予報の原理に立ち返って見れば、数値予報の精度には、数値予報モデルが自然界の法則への近似度が高いか、そして初期条件が実際の大気の状況に近いのか、この2点が重要であることがわかります。
観測データは基本的に点のデータですし、数値予報モデルの格子に合わせて観測されるわけではありません。地球全体を格子で覆いますが、南半球や海上、あるいは成層圏など観測点が格子の数に比べてはるかに少ないところもあります。このように限られた観測の情報から全地球の3次元の格子の値をどう決めていくか、これが初期値解析のポイントとなります。
実は、数値予報が生まれる前から予報官が実況の天気図を描き、それをもとに明日の天気図を予想するという作業は、天気予報のコアな技術でした。当時は高層観測も衛星観測もなく、基本的に地上観測から天気図を描いていました。現在でもそうですが、当時は今以上に観測の空白域は広がっていました。そこでの作業は限られた点の観測情報から面の情報である天気図を作成するというものとなります。高気圧や低気圧の位置、前線をどう描くか、等圧線をどう引くか、限られた情報から予報官の経験、知見を駆使して、例えば低気圧の構造などを頭に置きながら作業していました。前日作成した天気図と予想天気図も参考にしていました。予想天気図を基本に、入電した観測データを使って等圧線を修正していくことなど、観測情報と予測情報との融合作業も行われていました。このような形の天気図解析を主観解析と呼ぶこともあります。
これに対して数値予報で行われる初期値解析は客観解析と呼ばれますが、予測天気図をもとに観測データで修正を行うという発想は、予報解析サイクルという形で引き継がれました。予報解析サイクルとは何かというと、ある日の9時(00UTC世界標準時)の初期値解析から数値予報モデルで6時間先の予測をおこないます。9時の6時間先は15時ですので、15時の推定天気図が得られます。15時の観測データが得られると、この推定天気図を観測データを使ってより実際に近い天気図にしてそれを15時の初期値解析とします。これを初期値として再び6時間先の予測をおこない、21時の推定天気図ができます。ここに21時の観測データを使って21時の初期値解析とします。この予報と解析のサイクルを繰り返していくことで、モデルと観測データの融合した解析値が6時間毎に得られることになります。
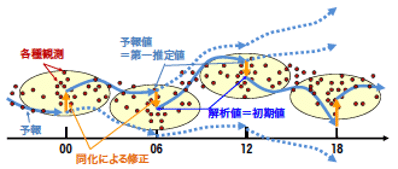
平成30年度数値予報解説資料よりhttp://www.jma.go.jp/jma/kishou/books/nwptext/51/2_chapter1.pdf
もう少しイメージをつかむため、次の図を掲載します。地図上の格子がモデルの格子、○が観測の位置で観測で得られた値を色で示しています。第一推定値とは、6時間前の初期値からの6時間予測の結果です。観測データにより、第一推定値から修正された解析値が得られている様子がわかります。
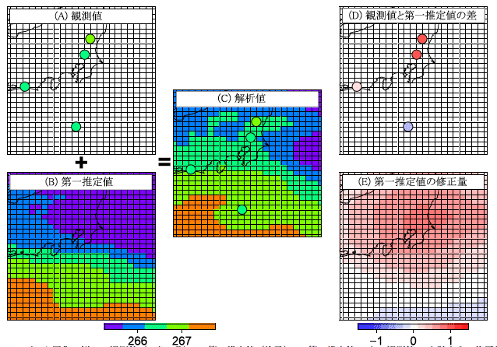
平成30年度数値予報解説資料よりhttp://www.jma.go.jp/jma/kishou/books/nwptext/51/2_chapter3.pdf
この例のように格子の数に比べて観測データの数が少ない場合でも、予測データを活用することで各格子の解析値を決めることができます。観測データと数値予報モデルとの融合、あるいは数値予報モデルへの観測データの同化、といったイメージをつかんでいただければと思います。上の図の修正量を具体的にどう決めたらよいのか、予測結果にも観測結果にもそれぞれ誤差がある中で、真の値(神のみぞ知る)にもっとも近い最適値をいかに得るのかがデータ同化の目指すところとなります。
データの品質管理
観測データにはさまざまな誤差が含まれます。ガウス分布に乗るような統計的にきれいな誤差は対応しやすいのですが、人為的なミスが絡んでいたり、何らかの故障でセンサーのバイアス誤差が増大したり、対応の難しい誤差もあります。こうした誤差にはデータをていねいに品質管理することで誤データを除去したり補正したりすることで解析品質への悪影響を防がなければなりません。

平成30年度数値予報解説資料よりhttp://www.jma.go.jp/jma/kishou/books/nwptext/51/2_chapter2.pdf
データ同化の威力とは
最適値を得るための手法として、さまざまな手法が使われてきました。当初は単純な手法も使われていたのですが、今では力学理論や確率論を踏まえベイズ統計を軸に展開した手法が主流となっています。ベイズ統計、PCR検査の偽陽性や偽陰性を推定する際にも使われるので、この言葉を今年よく聞かれたかもしれません。このような高度な手法を導入することで数値予報の精度が大きく向上してきたのも事実です。その背景には衛星観測データの情報価値をより多く引き出すことができることなどがあります。そして当初の点の観測を面のデータにするということを大きく超えるような役割を果たして来ています。
たとえば、アメダスの観測では気温、風向・風速、降水量、日照時間といった要素を観測していますが、観測では要素に応じてセンサーを用意します。観測の難しい要素もありますし、予算の制約もありいくつかの要素に限定して観測されるのが普通です。データ同化ではさまざまな要素の関係式を含むモデルを使うことにより、一つの要素の観測を他の要素の解析に反映することができます。
また衛星観測の基本は電磁波の情報です。衛星観測が開始された当初は、この電磁波の情報から気温などの要素を推定するリトリーバルを経て気象データとして活用していました。このリトリーバルには誤差が伴います。誤差を大きくした観測データを使って解析することになりますので、初期値の誤差も大きくなります。これを最近の手法では変分法を活用するなどにより電磁波の情報から直接格子の気象要素を解析し初期値解析の誤差を小さくすることができました。
他にも気象状況に応じた誤差の性質を推定してそれを観測データの反映に活用するなどさまざまな高度な技術が使われるようになりました。これらの技術革新にモデル改良の効果が加わり、予測精度の向上が図られ、1980年代の1日予報の精度で今では3日先の予報ができるようになりました。さらに天気予報の初期値作成という目的から脱皮したデータ同化の利用も広がってきています。3次元の解析の時間変動という意味での4次元解析データ自体が大気を包括的に記述する基礎データとして気象学の重要なデータとして位置付けられるようになりました。この目的で最新の技術で過去の気象解析を再現することを再解析とよび、地球全体の再解析としては、欧州ECMWFと米国NCAR/NCEPそして日本の気象庁の再解析が広く世界で使われています。
さらに観測の有効性を調べるツールとして、OSE(Observation System Experiment)、OSSE(Observation System Simulation Experiment)のプラットフォームとしてデータ同化システムが使われるようになっています。OSEは観測結果が利用できる場合にその観測データのインパクトを調べる実験であり、OSSEは将来打ち上げる衛星の観測データなど観測が実現していない場合にそのインパクトを推測する実験です。
データ同化研究のひろがり
天気予報が動機付けとなって発展してきたデータ同化ですが、現象の時間発展を記述する法則がわかっていて、現象の一部を捉える観測あるいは実験データが取れるのであれば、気象と同様にデータ同化は有効なツールとなりえます。海洋学などの地球科学分野はもちろん、工学や医学分野への応用も広がってきています。たとえば情報・システム研究機構にはデータ同化研究支援センターがあり、企業を含めさまざまな分野でのデータ同化研究をサポートしています。http://daweb.ism.ac.jp/cara/ja/
気象学のデータ同化を現業的に実施しているのは気象庁ですが、研究として進めているのが理化学研究所のデータ同化研究チーム、そのチームリーダーの三好さんは、気象庁の現業データ同化システムの開発からこの世界に入った研究者です。10年、20年先に実用化されるかもしれない最先端の天気予報を京コンピュータ、そしてこれからは富岳を使って研究を進めています。
この記事が気に入ったらサポートをしてみませんか?