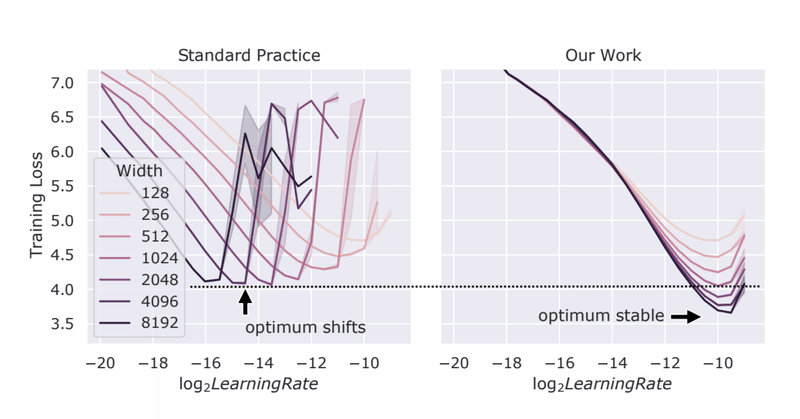
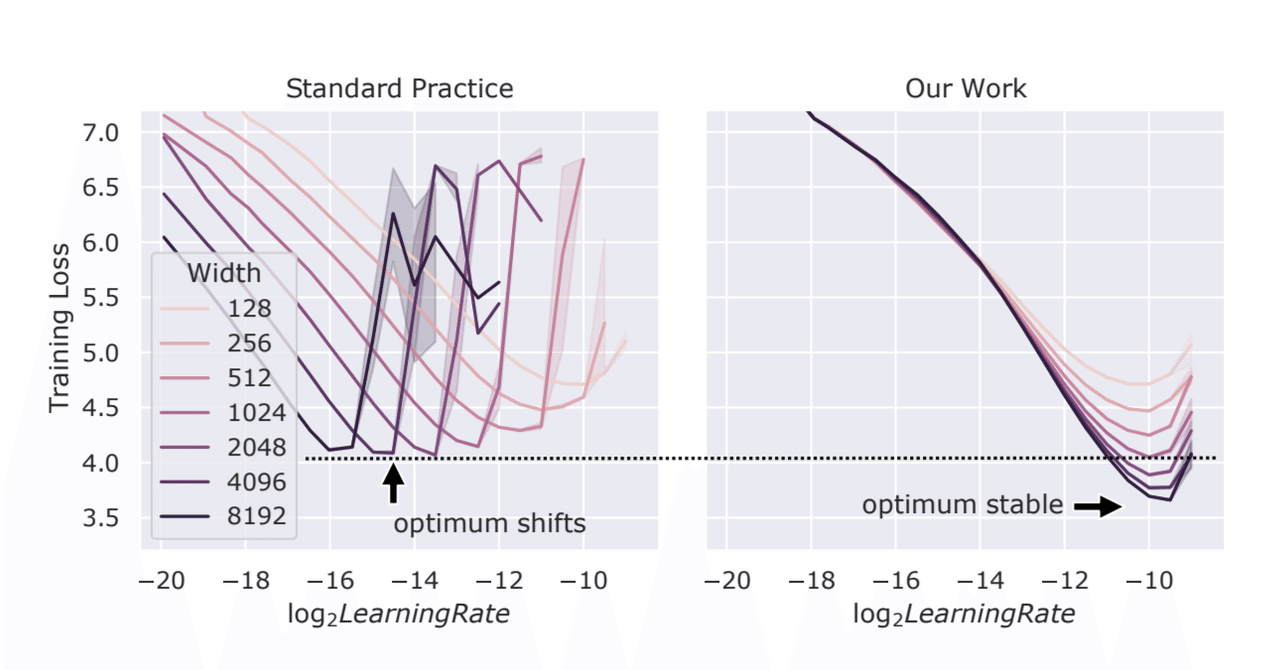
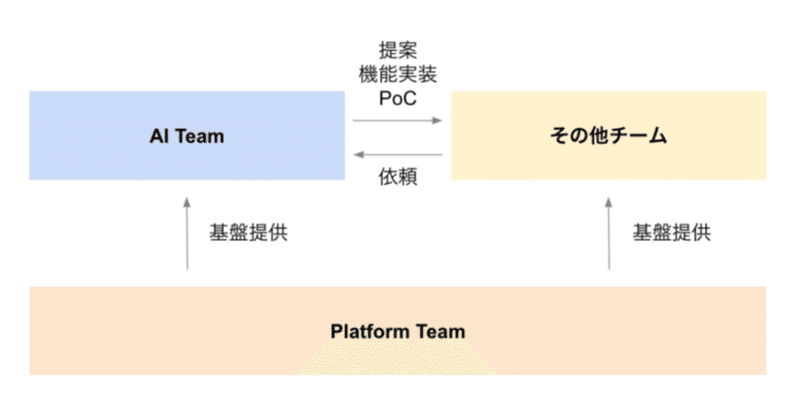
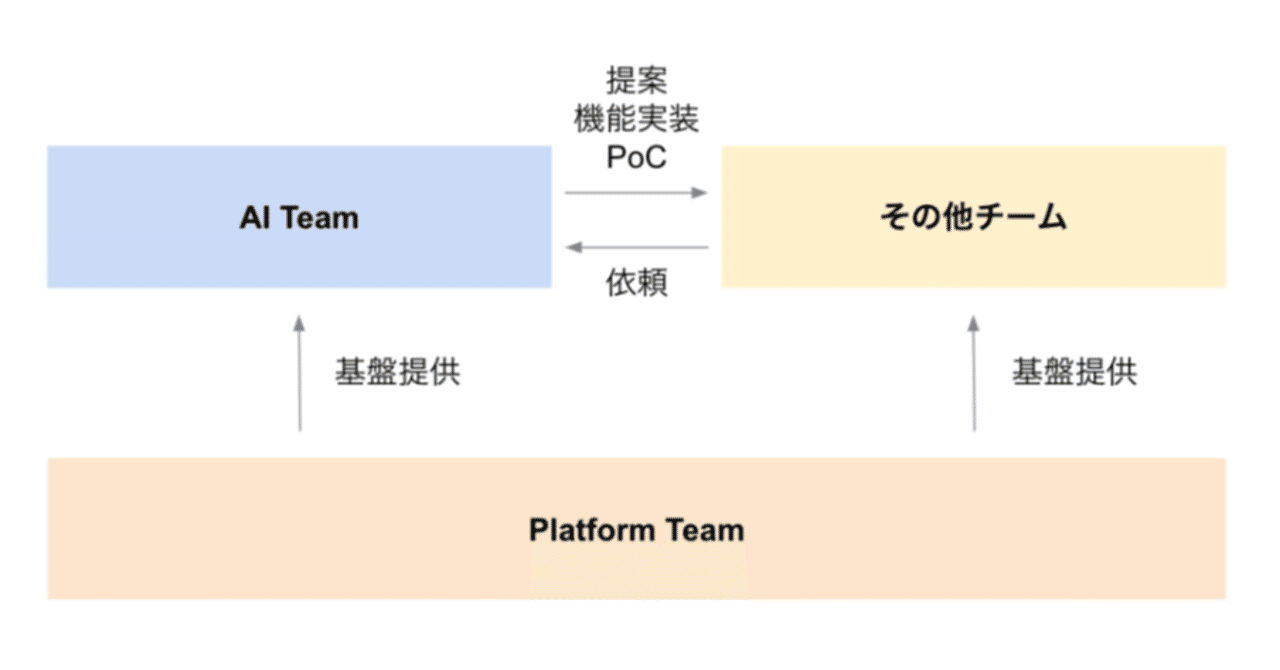
最近の記事



Pythonのlogging.getLogger()で作ったログのログレベルをDEBUGにしたら、外部パッケージのデバッグログが出力された件
タイトルが理解できた方はスルーしてください。もしどういうことかちょっとでも疑問に感じた方はお読みください。自分はこれを見落とし、ログ基盤に負荷を与えて痛い目にあいました。 論より証拠import loggingimport requestshandler = logging.StreamHandler()handler.setLevel(logging.NOTSET)formatter = logging.Formatter("%(name)s - %(levelname)