
ディープラーニングでディズニーとサンリオのキャラクター識別を作る

1.背景
AidemyのE資格対策講座とAIアプリ開発講座が終わった。
せっかくなので習ったことを詰め込んだものを作成しようと思い、ディズニーとサンリオのキャラクターを識別できるWebアプリケーションを作成することにした。
今回は「ディズニー」と「サンリオ」の二値分類だが、多項分類も少しソースを変更すればできるようにした。
2.開発の流れ
2.1 開発の流れ
下記の流れで開発を行う。
・「スクレイピング」で教師用画像データを取得
・取得した教師用画像データの「水増し」を行う
・「転移学習」を利用して「画像識別モデル」を作成
・画像識別モデルを「Webアプリケーション」として公開
2.2 開発環境
開発環境は下記の通り。
・macOS Ventura 13.2.1
・python 3.10.9
・Visual Studio Code 1.76.1
2.3 使用ライブラリのバージョン
beautifulsoup4 4.11.2
requests 2.28.1
lxml 4.9.2
chromedriver-binary-auto 0.2.3
tensorflow 2.11.0
keras 2.11.0
scikit-learn 1.2.2
3.開発
3.1 スクレイピング
まずはディープラーニングの学習に使う教師用学習画像を取得するためにスクレイピングのモデルを作成する。
今回は、Googleの画像検索ページを利用し、ディズニーとサンリオの検索結果を100枚ずつ取り込んだ。
#利用するライブラリ (モジュール)をインポート
import requests
from time import sleep
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import os
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
import base64
def my_scraping(actor_name, get_limit, save_dir):
"""画像のスクレイピングを行い、指定フォルダに保存する
Args:
actor_name (string): 検索ワード
get_limit (int): 最大取得画像数
save_dir (string): 取得した画像を保存するフォルダ
"""
# ChromeDriverを使うための設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# ChromeDriverを確実に破棄するためにwithで宣言
with webdriver.Chrome(ChromeDriverManager().install(), options=options) as browser:
# 画像検索ページを開く
url = "https://www.google.co.jp/imghp?hl=ja"
browser.get(url)
# 検索欄のinput要素を取得
search = browser.find_element(By.NAME, 'q')
# 検索ワードを入力し、エンターキーを押下、検索
search.send_keys(actor_name)
search.send_keys(Keys.ENTER)
# imgタグのsrc情報を取得する
img_urls = []
img_count = 0
# 事前にスクロールして画像を表示しておく スクロール1回あたり二十枚だが、余分にスクロールしておく
scloll_cnt = get_limit//5
print("スクロール回数:", scloll_cnt)
for s in range(scloll_cnt):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(1)
#BeautifulSoupで画像検索したページの画像を取得する
soup = BeautifulSoup(browser.page_source, "html.parser")
# imgタグを取得
img_tags = soup.select("img")
# imgタグのsrcの中を取得し、配列にする
for img_tag in img_tags:
# 画像の取得上限を超えたら終了
if img_count >= get_limit:
print("上限を超えたので修了")
break
# src属性の中身を取得
url = img_tag.get("src")
# src属性の中身が空の場合は処理をスキップ
if url is None:
continue
# ファビコンやpng、svgなどの場合はスキップ
if ('favicon' in url) or ('.png' in url) or ('.svg' in url) or ('data:image/' in url):
continue
# 一覧に追加
img_urls.append(url)
img_count += 1
# 一覧にしたURLから画像を取得して保存する
# 保存フォルダの確認 なければ作成する
if not os.path.exists(save_dir):
os.mkdir(save_dir)
#取得した画像のデータを保存する
i=1
for url in img_urls:
# print(i)
try:
# base64形式の場合、デコードして保存
if 'data:image/' in url:
with open(save_dir + "image_" + str(i) + "_0.jpg", "wb") as fp:
fp.write(base64.b64decode(url.split('base64,')[1]))
# URLの場合
elif "http" in url:
# 画像のURLを取得
r = requests.get(url)
# 取得したファイルの保存
with open(save_dir + "image_" + str(i) + "_0.jpg", "wb") as fp:
fp.write(r.content)
else:
continue
# インクリメント
i += 1
# 連続取得を避けるため、スリープ
sleep(0.1)
except:
# エラーを握りつぶす
pass
browser.quit()
if __name__ == "__main__":
# ディズニーの画像を取得
print("ディズニー")
actor_name = "ディズニー キャラクター イラスト" # 検索ワード
get_limit = 100 # 最大取得画像数
save_dir = "./img/desny/" # 取得した画像を保存するフォルダ
my_scraping(actor_name, get_limit, save_dir)
# サンリオの画像を取得
print("サンリオ")
actor_name = "サンリオ キャラクター 公式" # 検索ワード
get_limit = 100 # 最大取得画像数
save_dir = "./img/sanrio/" # 取得した画像を保存するフォルダ
my_scraping(actor_name, get_limit, save_dir)3.2 水増し
3.1 スクレイピングでディズニーとサンリオの画像を100枚ずつ取得したが、ディープラーニングの教師データとしては足りないので、水増しを行う。
今回は下記の水増しを行った
・画像の左右反転
・閾値処理(二値化)
・ぼかし
・モザイク処理
・収縮
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2
import glob as glob
def scratch_image(img, flip=True, thr=True, blur=True, resize=True, erode=True):
# 水増しの手法を配列にまとめる
methods = [flip, thr, blur, resize, erode]
# 画像のサイズを習得、収縮処理に使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
# 画像の左右反転
lambda x: cv2.flip(x, 1),
# 閾値処理
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
# ぼかし
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
# モザイク処理
lambda x: cv2.resize(x, (img_size[1] // 5, img_size[0] // 5)),
# 収縮
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で画像データ(images)を水増
for func in scratch[methods]:
images = doubling_images(func, images)
return images
def all_acratch_image(folder_path):
""" 指定したフォルダの全画像を水増しする
Args:
folder_path (str): フォルダパス 例)./img/sanrio
"""
# フォルダ配下のファイルを全て読み込む
files = glob.glob(folder_path + "/*")
# 取得したファイルのループ
for i, file in enumerate(files):
# 画像の読み込み
cat_img = cv2.imread(file)
# 画像の水増し
scratch_cat_images = scratch_image(cat_img)
for num, im in enumerate(scratch_cat_images):
# まず保存先のディレクトリ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(folder_path + "/image_" + str(i) + "_" + str(num + 1) + ".jpg" , im)
if __name__ == "__main__":
# ディズニー
all_acratch_image("./img/desny")
# サンリオ
all_acratch_image("./img/sanrio")上記を実行した結果、ディズニー、サンリオの教師用画像が3,300枚ずつに水増しされた。
3.3 転移学習を利用して画像識別モデルを作る
今回は転移学習としてVGG16モデルを利用する。
VGGの特徴抽出部分のみを用いてそれ以降のモデルは自分で作成したモデルと結合させる。
学習用データとテスト用のデータは8:2で分けて精度測定を行った。
import cv2
import numpy as np
import glob as glob
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Flatten
import pickle
from tensorflow.keras import optimizers
# 設定
classes = ["desny", "sanrio"] # ラベル(分類名)
num_classes = len(classes) # ラベル数
image_size = 50 # イメージをリサイズするサイズ
# 画像を読み込む
X_train = []
y_train = []
# フォルダ(クラス名)のループ
for index, classlabel in enumerate(classes):
# フォルダ配下のファイルを全て読み込む
photos_dir = "./img/" + classlabel
files = glob.glob(photos_dir + "/*")
# 取得したファイルのループ
for i, file in enumerate(files):
img = cv2.imread(file) # ファイルの読み込み
img = cv2.resize(img,dsize=(image_size, image_size)) # リサイズ
X_train.append(img) # 画像をappend
y_train.append(index) # ラベル(クラス名)をappend
# 正規化
X_train = np.array(X_train)
X_train = X_train.astype('float32')
X_train /= 255.0
# ラベルの変換
y_train = np.array(y_train)
y_train = np_utils.to_categorical(y_train, num_classes)
y_train[:5]
# 学習データとテストデータに分ける(テストデータ2割、学習データ8割)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# VGG16をロード
input_tensor = Input(shape=(image_size, image_size, 3))
base_model = VGG16(weights='imagenet', input_tensor=input_tensor, include_top=False)
# 自分で追加する層
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(num_classes, activation='softmax'))
# 結合
model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
# 学習させない層(ロードしたVGG16は19層あるが、後半4層+自分が追加した層を学習させる設定)
for layer in model.layers[:15]:
layer.trainable = False
print('# layers=', len(model.layers))
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
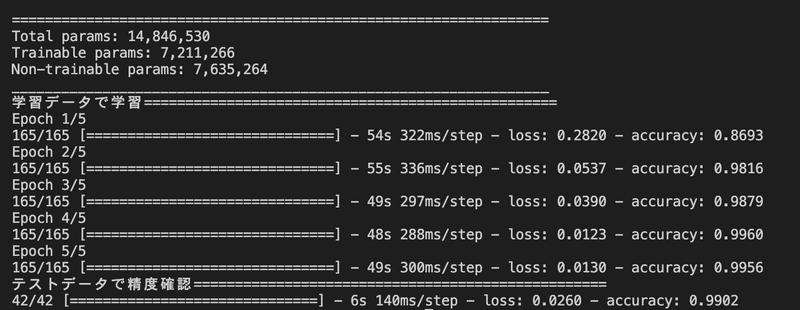
print("学習データで学習==================================================")
# 学習データで学習
model.fit(X_train, y_train, epochs=5, batch_size=32)
print("テストデータで精度確認==================================================")
# テストデータで精度確認
score = model.evaluate(X_test, y_test, batch_size=32)
# クラス名の保存
pickle.dump(classes, open('./output/classes.sav', 'wb'))
# モデルの保存
model.save('./output/cnn.h5')ハイパーパラメータとして、バッチサイズ、エポック数、リサイズの値を色々と試行錯誤した。
教師データが変わればこのあたりの値が必要かもしれない。
テストデータで精度確認した結果、accuracyが0.9902になったのでハイパーパラメータの調整を終了した。
3.4 Webアプリケーション公開
3.3 で作成したモデルファイル(model.h5)を利用して画像の判定を行う。
Webアプリケーションの公開は、flaskを使ったが、方法は割愛して、model.h5を利用した予測方法を記載する。
image_size = 50
#学習済みモデルをロード
model = load_model('./model.h5')
classes = ["desny", "sanrio"]
#受け取った画像を読み込み 、np形式に変換
img = cv2.imread(filepath) # ファイルの読み込み
img = cv2.resize(img, dsize=(image_size, image_size)) # リサイズ
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"ちなみに自分の顔写真を識別させた結果、desny顔だったことが判明。
ディズニーランドに行ってキャラクターと間違われたらどうしよう。

4.総括
今回は「ディズニー」か「サンリオ」かという識別にしたが、ソースを少し変更するだけで、「犬種の識別」、「芸能人の名前識別」など色々応用ができそうなものが作成できた。
また、おおざっぱな分類の後で詳細な分類モデルを動かすのもいいかもしれない。
例えば「犬か犬以外か」というモデルで最初に識別を行い、犬の場合は、2つ目のモデル「犬種の識別」など、といった活用方法だ。
この記事が気に入ったらサポートをしてみませんか?