ABC170振り返り

ABC170の振り返りをします。
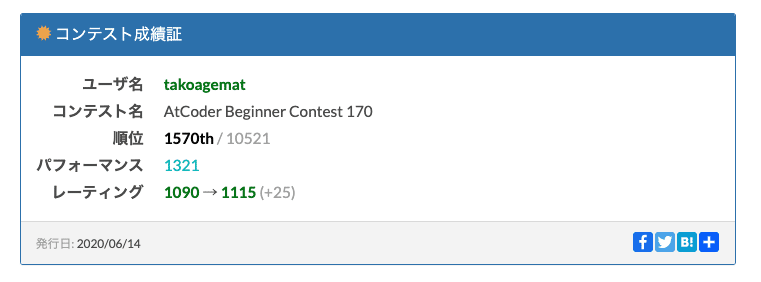
結果は31分A-D4完2ペナでレートが少し上がりました。
Dまで終わった段階でE,Fの問題を見て、E問題は実装が重そうで苦手だと感じました。対してF問題は問題がわかりやすく解けそうだったのでF問題に取り掛かりました。
後40分を残してTLEが2つ以外はACになったのでいけると思いましたが、解けませんでした。
コンテスト中
A問題
x_1からx_5まで見て0になっているものを見つけます。
int main(){
vector<ll> a(5);
rep(i,5) cin >> a[i];
rep(i,5){
if(a[i] == 0){
cout << i + 1 << endl;
return 0;
}
}
}
B問題
つるかめ算に関する問題です。
X匹での足の最小数は2X、足の最大数は4Xです。
足の総数は必ず偶数になることにも注意することでACできます。
int main(){
ll x, y; cin >> x >> y;
ll l = 2 * x;
ll r = 4 * x;
if(y >= l and y <= r and y % 2 == 0){
cout << "Yes" << endl;
}
else cout << "No" << endl;
}
C問題
ベクトルpに含まれない数で、最も整数Xに近い整数を求める問題です。
ベクトルに含まれる要素、X共に最大値が100なのでありうるpを真に内包する集合に含まれる整数を全て試していけば求められます。
int main(){
ll x , N; cin >> x >> N;
vector<ll> a(N); rep(i, N) cin >> a[i];
ll ans = 1e9;
SORT(a);
rep(i , 500){
if(!binary_search(a.begin(), a.end(), i)){
if( abs(ans - x) > abs(x - i) ){
ans = i;
}
}
}
cout << ans << endl;
}
D問題
ソートした長さNの数列Aに対して、それぞれの要素が他の全ての要素と互いに素であるかを判定していけば良いです。
従って、エラトステネスの篩と同じ構造が見えてきます。
例えば、
A = {2 , 4 , 5 , 6 , 10 , 18}
のときは
A_0 = 2に関して、Aの最大値まで2の倍数を潰していく、ansに+1
A_1 = 4はすでに潰されているのでskip
A_2 = 5に関して、Aの最大値まで5の倍数を潰していく、ansに+1
A_3 = 10に関してはすでに潰されているのでskip
….
といった具合にやっていきます。
計算量はソートにO(N log N)、エラトステネス同様の処理にO(A_max log log A_max)で間に合います。
Aに1が含まれるとき、同じ数値が含まれる時に注意しながら実装しました。
int main(){
ll N; cin >> N;
vector<ll> a(N); rep(i,N) cin >> a[i];
SORT(a);
ll ans = 0;
vector<bool> check(1e6 + 100);
rep(i, 1e6 + 100) check[i] = true;
if(N == 1 and a[0] == 1){
ans = 1;
}
if(a[0] == 1){
if(N > 1 and a[1] > 1){
ans = 1;
}
}
else{
rep(i,N){
ll tmp = a[i];
if(check[tmp]){
ans++;
if(i < N - 1 and(a[i] == a[i + 1])){
ans--;
}
}
while(tmp < 1e6 + 100){
check[tmp] = false;
tmp += a[i];
}
}
}
cout << ans << endl;
}
コンテスト後
E問題
multisetのデータ構造を利用することで、問題文通りに実装することで解けました。
multisetのeraseが複数の要素を同時に消してしまうことは知らず、コンテスト後にもACするのに時間がかかりました。
また、eraseはイテレータを指定することで複数同じ要素が存在しても、一つの要素のみを消去することができることを学びました。
データ構造はなかなかうまく使いこなせないので、理解を深めたいです。
multisetでは以下のような挙動をします。
int main(){
multiset<ll> s;
s.insert(1);
s.insert(1);
s.insert(2);
s.insert(3);
cout << s.size() << endl;
rep(i,s.size()){
auto p = next(s.begin() , i);
cout << *p << endl;
}
// 1,1,2,3が順番に出力される
s.erase(1); cout << s.size() << endl;
// 2が出力される
multiset<ll> t;
t.insert(1);
t.insert(1);
t.insert(2);
t.insert(3);
t.erase(t.find(1)); cout << t.size() << endl;
// 3が出力される
t.insert(10);
t.insert(100);
auto p = t.find(*(t.rbegin()));
t.erase(p);
// 最大値を削除する
cout << &p << endl;
// メモリの表示 0x7ff.......と出力される
cout << *t.rbegin() << endl;
// 10が出力される
}
各幼稚園の要素をいれるmultisetの他に、クエリごとに最大値を少ない計算量で更新するために、各幼稚園の最大値の要素を集めたmultisetも作成することが必要です。
各クエリに対して、幼稚園のmultisetの更新、幼稚園の最大値を集めたmultisetに更新、幼児の所属する幼稚園の更新を行っていきます。
平衡二分木の構造を持っているため、それぞれO(log N)の計算量で行えるはずです。
int main(){
ll N , Q; cin >> N >> Q;
vector<ll> a(N); vector<ll> b(N);
rep(i,N) cin >> a[i] >> b[i];
vector<ll> c(Q); vector<ll> d(Q);
rep(i,Q) cin >> c[i] >> d[i];
vector<multiset<ll> > s(MAX);
multiset<ll> maxs;
// multisetへの入力
rep(i,N) s[b[i]].insert(a[i]);
rep(i,MAX){
if(s[i].size() > 0){
// それぞれのsの最大値をmaxsに格納する
maxs.insert(*s[i].rbegin());
}
}
// クエリごとの処理
rep(i,Q){
// c[i] - 1の幼児が 幼稚園 b[c[i] - 1] から d[i] に移動する
// maxsの更新
auto p1 = maxs.find( *s[b[c[i] - 1]].rbegin() );
maxs.erase(p1);
if(s[d[i]].size() > 0){
auto p2 = maxs.find( *s[d[i]].rbegin() );
maxs.erase(p2);
}
// sの更新
auto ps = s[b[c[i] - 1]].find(a[c[i] - 1]);
s[b[c[i] - 1]].erase(ps);
s[d[i]].insert(a[c[i] - 1]);
// maxsの更新
if(s[b[c[i] - 1]].size() > 0) maxs.insert(*s[b[c[i] - 1]].rbegin());
maxs.insert(*s[d[i]].rbegin());
// 幼児の所属の更新
b[c[i] - 1] = d[i];
// for(auto p : maxs) cout << p << " ";
cout << *maxs.begin() << endl;
}
}
F問題
BFSでの解法で書くことができました。
それぞれの頂点からKマスまで直進することができるようなBFSを考えます。
通常のBFS同様に壁やいけないマスに到達した場合は直進をやめます。
また、スタート地点からの距離に更新しようとしている値以下の値がすでに書き込まれている場合も直進をやめます。
すでに距離が記してあるならば、そこからスタートして距離が伸びてしまうということがないからです。
これで各点に対して定数回しか見ないので計算量はO(HW)で書くことができました。
// 四方向への移動ベクトル
const ll dx[4] = {1, 0, -1, 0};
const ll dy[4] = {0, 1, 0, -1};
int main(){
ll H , W , K; cin >> H >> W >> K;
ll sx , sy , gx , gy; cin >> sx >> sy >> gx >> gy; sx--; sy--; gx--; gy--;
vector<string> field(H);
rep(i,H) cin >> field[i];
// 各セルの最短距離 (訪れていないところは -1 としておく)
vector<vector<int> > dist(H, vector<int>(W, INF));
dist[sx][sy] = 0; // スタートを 0 に
queue<P> que;
que.pu(mp(sx, sy));
while(!que.empty()){
pair<ll, ll> current_pos = que.front(); // キューの先頭を見る (C++ ではこれをしても pop しない)
ll x = current_pos.first;
ll y = current_pos.second;
que.pop(); // キューから pop を忘れずに
// 隣接頂点を探索
for (ll direction = 0; direction < 4; ++direction) {
repn(j , K){
ll next_x = x + j * dx[direction];
ll next_y = y + j * dy[direction];
if (next_x < 0 || next_x >= H || next_y < 0 || next_y >= W) break; // 場外アウトならダメ
if (field[next_x][next_y] == '@') break; // 壁はダメ
if(dist[next_x][next_y] <= dist[x][y]) break;
// まだ見ていない頂点なら push
if (dist[next_x][next_y] == INF){
que.push(make_pair(next_x, next_y));
dist[next_x][next_y] = dist[x][y] + 1; // (next_x, next_y) の距離も更新
}
}
}
}
/*
rep(i,H){
rep(j,W){
cout << dist[i][j] << " ";
}
cout << endl;
}
*/
if(dist[gx][gy] == INF) cout << -1 << endl;
else cout << dist[gx][gy] << endl;
}
解説にはDijkstra法を用いる計算量O(HW log (HW))の解法が書いてありましたが、こちらの方が計算量が少なく、自分にもしっくりきました。
アドバイスなどあればぜひお願いします。
よろしければ少額でもサポートお願いします。サポートの費用対効果は抜群です。