
自作の転置インデクスを導入する~プロダクトの価値検証時に検索機能を提供するコストを低減

検索のしごとをしていると「今、専門用語XXの検索はSQLのLIKE文で実装されている。しかし精度が厳しいので、Elasticsearchのような検索エンジンを使って精度を向上したい」という要望をもらうことがあります。
新規に Elasticsearch(Es)やSolrのような検索エンジンを使う場合、以下のようなタスクが考えられます。
クラスタの作成(QA、Staging、Production)
ECなどの分野でミッションクリティカルな検索サービスで使っているものとクラスタを分けたい場合
バッチスクリプト作成+設定(実行権限、中間ファイルのバケット etc)
クラスタに問い合わせるAPIサーバの作成
Es と接続する部分のテスト追加
上のように Es でインデクスを作ってそのままプロダクションに載せられるわけではなく、付随するタスクが多いです(モデルつくったらそのまま配備できるわけではないという意味で機械学習プロジェクトに近い印象を持っています)。
自作の転置インデクスを検討する状況
本来であれば Elasticsearch や Solr のような検索エンジンに載せ替えてちゃんと検索機能を提供したいのですが、十分な工数を取れない状況が発生します。工数が取りにくい状況には以下のような状況があります。
開発対象となる検索がサービスの重要な機能ではない
さらに、すでにSQLのLike文で部分的に検索機能が提供されている場合、期待される工数はより小さくなります
プロダクトの開発初期で価値検証を繰り返している場合
せっかく作ってリリースしても短い期間で機能を削除することも多く、構築した部分を削除するコストも侮れません。
オフラインのネイティブアプリケーションで検索クラスタにクエリを発行できない特殊な環境
ローカル環境にEsを建てるにしても、配布する際にインストーラを作るコストが発生
このような場合、簡易のオンメモリ検索インデクスを使って機能要件を満たしたことがあります。
他の方法でいいのでは?
他の実現手段として Elasticsearch や Solr の Docker コンテナを立ててそこにインデクスを作ってしまうの考えられます。しかしこの方法でもアプリのコードの修正部分以外で手続きが多く(テスト、開発環境の整備 etc..)、より早く本番環境で価値検証をしたい場合にはまだ速度感がたりません。
他の代替案としてはプラットフォームによっては提供されているOSSの検索インデクスです。たとえば Python には Whoosh という検索インデクスが存在します。このパッケージには提供される機能が多いのですが、逆に日本語文書でサクッとインデクスを構築、実際に動かすまでのステップが多いです。また、設定やチューニング方法もそれぞれ独自なものなので、余り起こらないケースのため各種設定やチューニング方法覚えるのも厳しい。。
簡易検索インデクスを自作する際の制約
先に述べたように要求される検索機能がシンプル(たとえば文書が一つの短いフィールドしか持た専門用語辞書の検索)で、かつ検索対象のデータが大きくなければ検索インデクスを自作して価値検証に進むことが稀にあります。
もちろんElasticsearchやSolrのような検索システムはつくれません。これらの検索システムを構築するにはインデクスの動的切り替えや、ハイライトのためのポジションオフセット情報、多言語に対応など多大な工数がかかるでしょう。
そのため作れる検索インデクスには大きな制約があります。
インデクスの更新はできない
アナライザの調整はプログラムでベタに記述する
リッチな機能は無い(分散、API etc)
負荷が少ない
インデクスできる文書は少ない(オンメモリ)
簡易検索インデクスの利点
上記のような大きな制約があっても機能の価値検証であれば、簡易検索インデクスで十分な状況はあります。この方法だとプロダクトの中に一つのコンポーネントとして記述(RailsであればRuby、FastAPIであればPython)し、それらをコード上でメソッド呼び出しして使用するので認証トークンどころかAPI呼び出しすら必要ありません。また、テストを作るのも必要なくなってから機能を削除するのもシンプルです。必要なくなった対象となるソースファイルをいくつか削除するだけ。
簡易検索インデクスをつくる
検索インデクスはいくつかの実現方法があります。ユーザからのアクセスが十分でなければ grepコマンドの呼び出しでも十分かもしれません。しかしある検索対象の要素が多い場合には検索インデクスを作る必要があります。検索インデクスにはいくつかの方法がありますが、転置インデクスは最もよく知られた方法で、実装もシンプルです。
転置インデクス
転置インデックスは各単語と単語を含む文書IDからなるテーブルです。たとえば、2つの英語の文書(1、2)があり、そのコンテンツがそれぞれ「私はアップルが好き」、「iPhoneがとても好き」であったとします。このとき、以下の表のような転置インデックスを生成します。
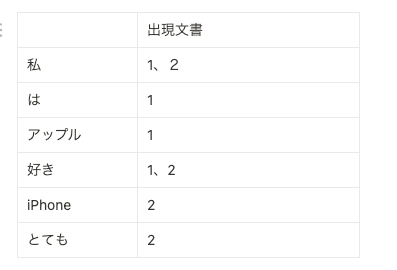
簡素な転置インデックスは辞書型のデータ構造で実装でき、単語をキーにして文書ID のリストを返します。
ユーザが検索クエリを発行した際、転置インデクスを使ってクエリ単語を含む文書を入手します。たとえばユーザが「アップル」という単語で検索した場合、上記の転置インデクスは文書1を返します。
入力処理
転置インデクスは文書が単語(もしくは文字列)に区切られていることを仮定しています。しかし文書は単語に区切られていません。そこで文書から単語を分割する処理が必要になります。単語に分割する際、形態素解析器とよばれるコンポーネントを使って文書から単語を抽出します。対象のアプリケーションが記述されている言語で形態素解析器が存在すれば形態素解析器を使って単語を抽出できます。
たとえば、Javaであれば Kuromoji、Pythonであれば Janome が存在します。もし実用的な形態素解析器が存在しない言語で記述されている場合には、規定数のオーバラップする文字列(Ngram)を使って分割します。
サンプル
簡易検索インデクスは本来はサービスやプロダクトのレポジトリ内の1コンポーネントとして作られます(簡易インデクスをプロダクトとは別レポジトリとしてしまうと、そこでコストが大きくなってしまうので)。今回はわかりやすさのためにサンプルとして切り出したPythonコードを作ってみました(https://github.com/takahi-i/tiny-index-sample )。検索対象の文書(専門用語)のリストを与えてインデクスを初期化し、検索します。
index = Index(['日本百景', 'ドイツ旅行'])
results = index.search('にほん')本体(index.py)が50 行程度に収まっています。読んでもらうと分かるようにホント簡易なんですが、数千〜数万の要素をもつ専門用語辞書を検索するなどの用途では問題なく使えます。
コードを見ると改善点は多く見つかります。検索結果のランキング良くするためにTF-IDFをつかったり、さらにBM25を導入したりしたくなります。たとえば、Pythonで検索エンジンを自作する方法 や Create A Simple Search Engine Using Python は本格的な検索インデクスの実装を解説しています。
ただ、今回のケースのように窮余の策として作る場合には、作り込むほどに簡易インデクスの最大の利点「導入までの早さ」が失われてしまいます。精度の向上が必要な場合、導入後に最小のコストでできるものを順次投入するといいでしょう。
まとめ
本格的な検索エンジンを導入しにくい状況で、簡易インデクスを作って少しの間代用機能を作る話をしました。本稿で解説したのはあくまでその場しのぎの方法なので、検証の結果十分な価値が認められればElasticsearchやSolrなどに載せ替えるようにしましょう。
参考
この記事が気に入ったらサポートをしてみませんか?