
Preppin Data Practice #06 (24年9月 2024: Week 35 - Premier League Results

Tableau Prepユーザー会のNakajima2です。
Japan Preppin Data Fam 第6回目のPreppin Data勉強会、24年9月のYouTube動画公開は、24年8月にPreppin' Dataで出題された全4題(W 32 〜35)から2024W35 の課題にチャレンジです。

今回取り上げたWeek 35のチャレンジでは、イングランド プレミアムリーグのサッカーシーズンの成績を整理する課題です。
データソースはExcel形式で提示されていますが、ゲームの動画配信サービスの情報からコピペなどでデータ収集したと思われるもの。データ表記や書式に揺れが多く、データの分析に適した構造になっていません。
問題の多いデータソースの文字列情報を、整理整頓することが今回の大きなテーマです。とても大変。
この課題に、勉強会の参加者がどの様な対応で乗り切ったか?
データの見方や、対応方法のTips満載の会となりました。動画 下記のアーカイブと、参加者が実際に作成したPrepフローファイルと合わせ、ご覧頂ければと思います。
Preppin Data勉強会の配信動画(YouTube)はこちらです。https://youtu.be/Mp4idloBx-s?si=eHV_BEiVEU4RnvkA
1)課題の内容
今回取り上げたW35のPreppin Data 課題は、下記を参照ください。
https://preppindata.blogspot.com/2024/08/2024-week-35-premier-league-results.html
・出題の背景、対応項目
今回の課題は、その後のPreppin’ Dataで連続シリーズものとして利用される元データの作成となります。
最初のデータ整理が大変重要ですが、与えられたExcelデータは、セル内で改行されており、2つのフィールドにおいてデータの記入が無いセル、改行位置が微妙にずれているもの が含まれています。
今回の課題は、この書式、データの揺れに対する勉強会参加メンバーの対応方法が、ひとつ大きな見どころになります。
FT\n1 Feb 24\n\n\nMatch highlights, duration 3 minutes and 1 second► 3:01\n\n 3\n\nWolves\nWolves\n 4\n\nMan United\nMan United
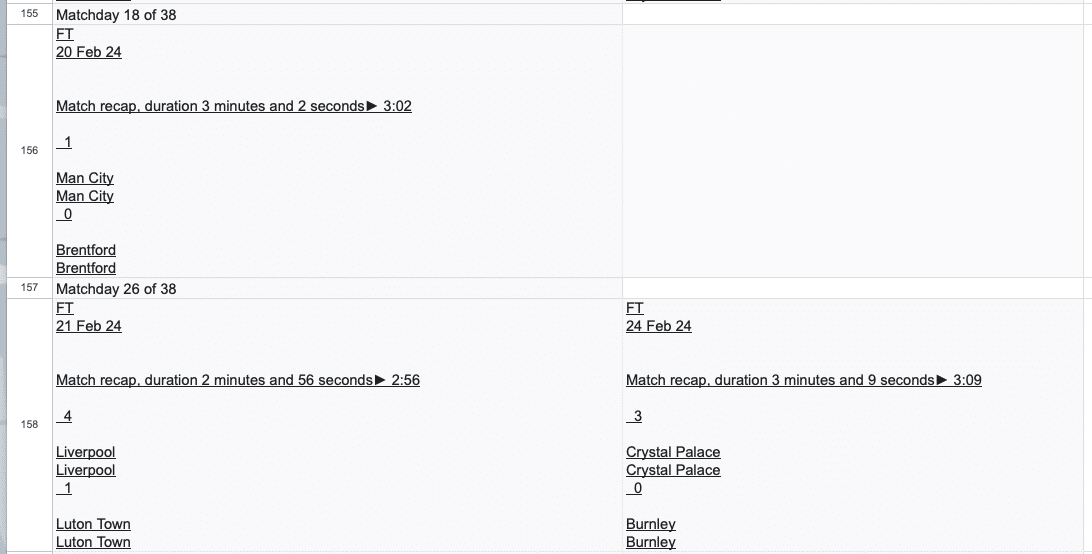
サッカーリーグに関するドメイン知識
イングランドサッカーのプレミアムリーグでは、参加20チームが週1〜2回 総当たりのゲームを行います。
全10ゲームとなる1回の総当たりをMatchday と称して合計38回行い、1シーズンの年間王者を争います。
Requirementsに記載がないのですが、シーズンを通した合計の勝ち点で年間王者が決まるシステムになっています。各ゲームでの勝ち点は、勝ちチームに勝ち点3、負けチームは勝ち点0(無し)、引き分けは両チームに勝ち点1が付くルールになっています。
各Matchdayでの順位付けは、合計勝ち点が同じ場合は、詳細な決まりが定められています。今回の課題ではこの点についてのみ Requirementsに記載が示されていますので、Requirementsに準じた処理が必要です。
Requirementsに記載されていないドメイン知識への配慮。最近のPreppin' Data出題は、このケースが多くなっており、実務では良くある要件定義やその背景の抽出を暗黙に求める課題になっている傾向があります。
・データソース、Outputデータ
データソース
Excelファイルで提供されたワークシートになります。
アウトプット
7フィールド、380列になる次のようなデータです。
17 data fields:
Away Score
Away Team
Home Score
Home Team
Matchday
Source Row Number
Date
380 rows (381 incl. headers)
2)対応のポイント(Requirementsのポイント)
要求項目から、処理として対応すべき概要は次の通りです(要約した内容です)。
データセットをインポートする
最初にExcelファイルをTableau Prepなどのツールにインポートします。ソースの行番号を追加
これは来週の課題で役立つため、インポート元の行番号を各行に割り当てます。試合日の番号を示す列を作成
各試合が38試合のシーズン中の何番目の試合日か(Matchday)を示す列を作成します。試合情報がない行を削除
データセットにゲーム情報が含まれていない行がある場合、それらの行は削除します。試合情報を1列にまとめる
インプットに2列で表現されている試合情報を1列にまとめます。改行文字 (\n) を別の文字に置き換える
改行文字 (\n) を別の文字、たとえば2つのパイプ文字 (||) に置き換えます。Prep Builderでは改行文字はchar(10)として認識されます。次の項目に対して個別の列を作成する([Away Score] , [Away Team] , [Home Score} , [Home Team] , [Matchday] )
結果を出力する
整形した結果を出力します。
3)参加者の解答例、Tipsなど
対応のポイントに沿って、参加者の回答方法を説明します。
読み込まれないヘッダ行への対応
今回提供されたデータソースのExcelファイルを接続すると、ヘッダ行が上手く取り込まれず、[Matchday 1 of 38] と [F2] の名称となるフィールドが作成されてします。
勉強会参加者の多くは、このままの状態で処理作業中に [Matchday 1 of 38] からの数値抽出を行なっていました。
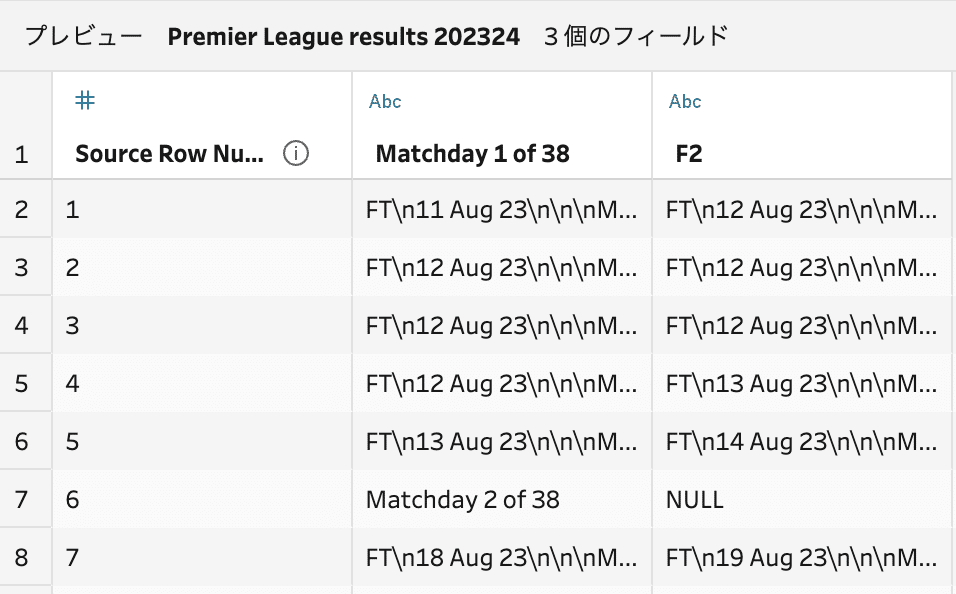
Mr.もりたは、ヘッダの調整を行う処理をひとつ入れて、「Matchday 1 of 38」をフィールド名ではなくデータ側に取り込めるよう、ヘッダ作成用のクリーニングステップ分岐処理を行い対処をしています。ここでヘッダ作成を行っておくことで、後で行う 下を埋める 処理がスムーズに行える様になります。
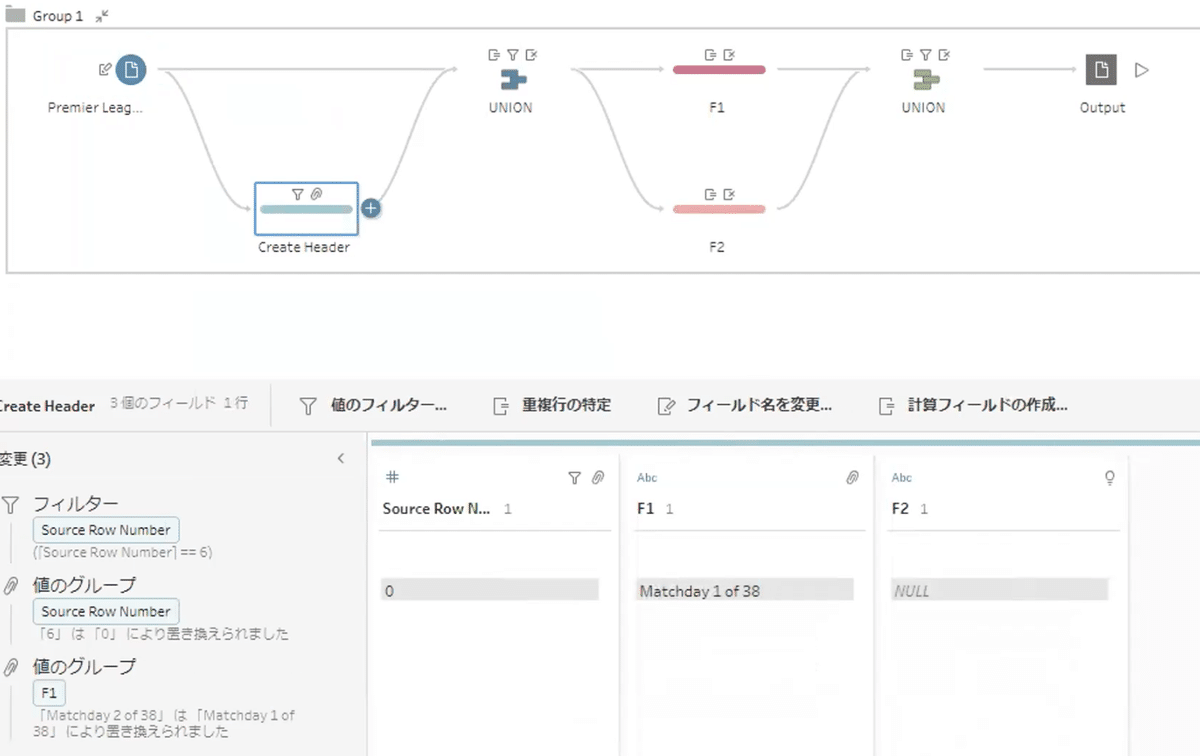
たっくんさんは、Excelでデータ接続をする際のヘッダ行がなくなることの対処検討として、データソースをCSVに変換してからデータ接続する試みを行なっています。
CSVに変換すると、データ行数が異常に増えて、データ処理に扱える型にならない様です。WEBからのデータをコピペして作成されたデータなどでは、CSV形式では利用が難しいケースがあるためと思われます。
[Matchday] フィールドの作成 (下を埋める)
Matchday の情報は、文字列データの中に「Matchday 10 of 38」の様な表記で含まれています。この「10」の数値データを取り出したフィールドを作り、「NULL」の部分を 下を埋める 処理を行うことで、各ゲームのデータにMatchday の情報を並べる様にします。
処理の概要は、Shiiharaさんのフローでご紹介します。
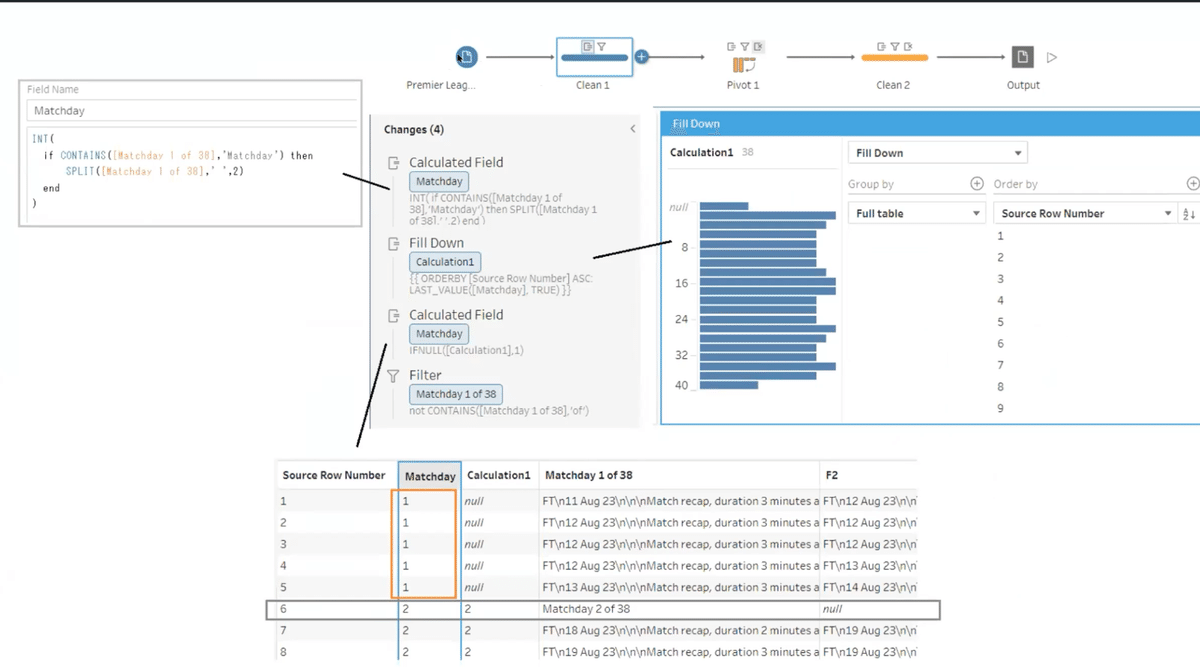
具体的な処理方法を、Yamaguchiさんの報告から示します。
IF CONTAINS([Matchday 1 of 38],"Matchday") THEN [Matchday 1 of 38] END
{ ORDERBY [Source Row Number] ASC: LAST_VALUE([Matchday],TRUE)}
INT(TRIM( SPLIT( MID(IFNULL([Matchday],"Matchday 1 of 38"),9), "of", 1 ) ))
Riekoさんは、正規表現を上手に利用し、Matchdayの数字を抽出する処理をしています。
if CONTAINS([Matchday 1 of 38], "Matchday") THEN
int(REGEXP_EXTRACT([Matchday 1 of 38], '(\d+)'))
else null END
//"Matchday"が含まれていたら、"Matchday n of 38"のnだけ取得
mitamuuさんは、上記の2つの処理を一つの計算式にまとめています。
{ORDERBY [Source Row Number] ASC:
LAST_VALUE( INT(TRIM(
MID( (IF CONTAINS([Matchday 1 of 38],"Matchday") THEN [Matchday 1 of 38] END) ,10,2) ))
,TRUE)}
komatsu1さんは、2023.2バージョンを利用していることから、下を埋める 処理が使えず、window_sum関数を利用し [Matchday] の数値抽出を行なっています。

2列の文字列フィールドを1列にまとめる
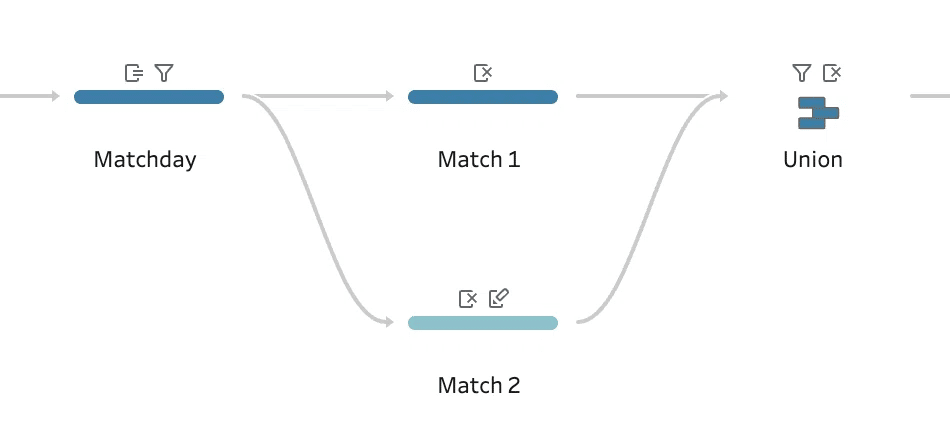
[Matchday 1 of 38] および [F2] の2列の文字列フィールドを1列にまとめる方法は、1)クリーニングステップで分離しユニオンする、2)ピボットを使う 2種の方法が使われていました。


改行文字の置き換え
改行文字 (\n) を、REPLACE関数などを用いて別な文字列に置き換えます。Prepにおいて、改行文字はchar(10)として認識されます。置き換えの関数例は次の通りです。
REPLACE([Data],char(10),'||')
日付フィールドの作成
日付の情報は、文字列の最初側に含まれています。
(例) FT\n1 Feb 24\n
SPRIT関数などで日付の情報(「1 Feb 24」の部分)を取り出し、日付形式に変換します。
日付の情報が、直ぐに日付型への型変換で対応出た方もいましたが、多くの方が型変換では処理が出来ず、関数式を記述して処理をしています。
DATE(
'20' + TRIM( SPLIT( [Date], " ", 3 ) )
+'/' + TRIM( SPLIT( [Date], " ", 2 ) )
+'/' + TRIM( SPLIT( [Date], " ", 1 ) )
)
DATE(
"20" + TRIM(SPLIT(TRIM( SPLIT( [Date], "||", 2 ) )," ",3))
+ "-" + TRIM(SPLIT(TRIM( SPLIT( [Date], "||", 2 ) )," ",2))
+ "-" +TRIM(SPLIT(TRIM( SPLIT( [Date], "||", 2 ) )," ",1))
)
この日付データには、9月だけ月を示す文字列が3文字ではなく4文字の「Spet」になっていたことから、日付データへの変換に手間を要するケースもあった様です。データソースが整っていない事例ですね。
4)文字列からのデータ抽出(REPLACE、SPRIT)
今回の課題で、最も難関と思われた処理になります。参加者の様々なアイディアが提示されました。
処理のポイントは、文字列のデータを良く確認し、ScoreとTeamに関するデータの並び方、法則性が見つかれば、そのルールに従いシンプルな処理が出来ます。
データの並びを見ながら、デフォルト機能で整理
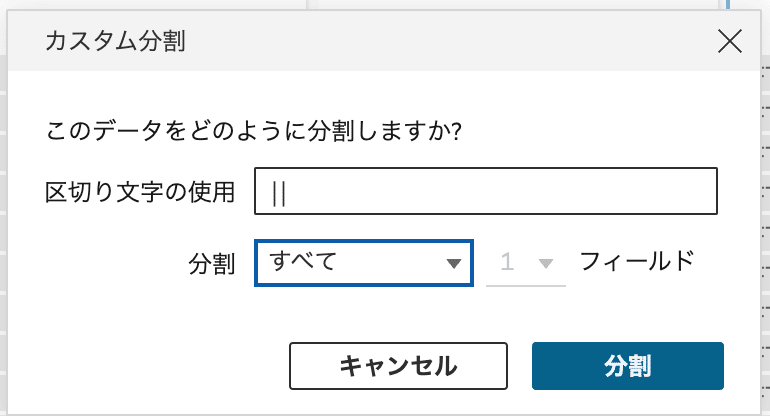
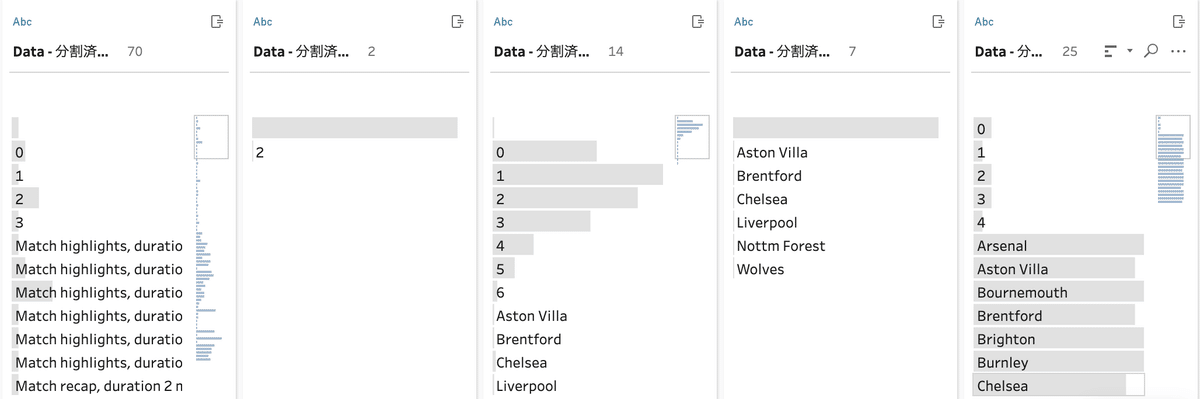
Nakajima2が行った、データの並びを見ながらその場で力技で整理をしていく方法です。
1つにまとめた文字列データを、 || を利用して分割します。
ScoreとTeamに関する分割後データの並びが複数列にまたがっているため、デフォルト機能を使って複数列のデータを数値(Score)や文字(Team)で整理して、マウス操作の列マージで揃える処理をしています。
改行文字の処理を進めながら、文字列の状況に合わせて整理
文字列の文字並びを詳しく確認しながら、関数による置き換え処理などで改行文字を揃える処理方法です。
Shiiharaさんは、まず改行文字が3つある場合を2つに減らす処理をしています。
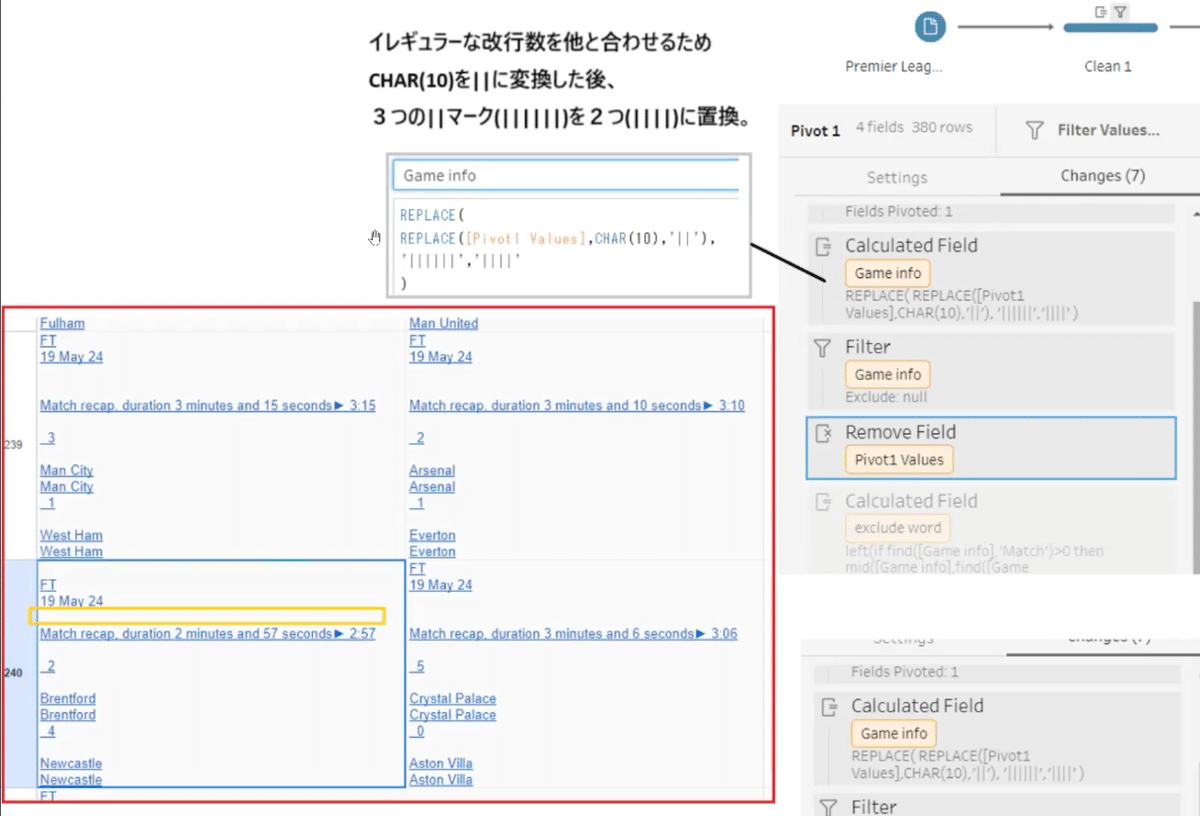
その後、文字列中に「Match」が含まれているか否かで文字の並びルールを区別し、最終的に改行文字の場所揃え整理を行なっています。
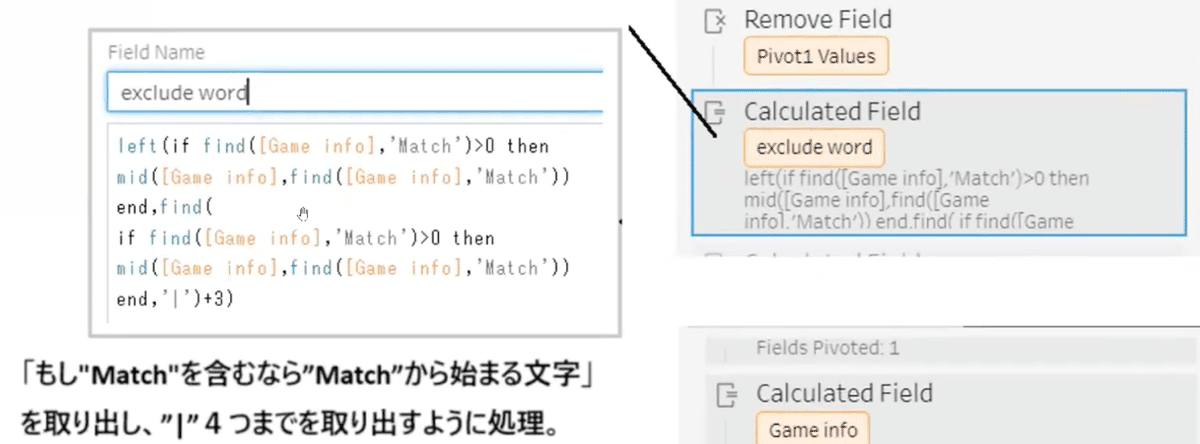
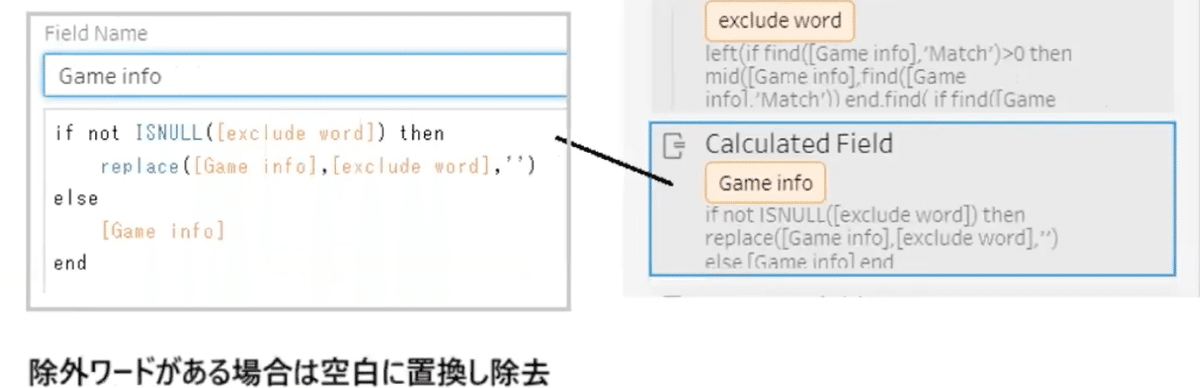
文字の位置で整理
Yamaguchiさんは、文字列に「Match」が含まれているかを確認し、その有無で抽出する位置を計算式で調整しています。
18文字目以降の文字の並びをしっかり確認した対応方法です。
REPLACE(
IF CONTAINS([Matchday 1 of 38],"Match") THEN
REGEXP_EXTRACT([Matchday 1 of 38], '[0-9]{1,2}:[0-9]{2}[^0-9]*([\s\S]*)')
ELSE MID([Matchday 1 of 38],18) END
,CHAR(10),"|")
// Matchが含まれているかを確認
// 含まれている場合は時間の後を取得
// 含まれていない場合は18文字目以降を取得
上記の処理で、ScoreとTeamに関するデータに関する位置が揃うため、SPRIT関数を用いひとつのフィールドを抽出することで、必要となるフィールドを作ることが出来ます。
[Away Score]
INT(TRIM( SPLIT( [Matchday 1 of 38], "|", 5 ) ))
また、たっくんさんは、データのビデオ再生ボタンを示す「►」を含む部分をフィルタで取り除いた後に、データ抽出を行なっています。
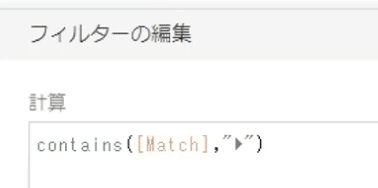
改行文字の位置を揃える 改行文字の数を揃える
Riekoさんは、正規表現を利用して改行文字が2つある場合に改行文字を1つに揃える処理を行なっています。
REGEXP_REPLACE([Matchday 1 of 38], '||||+', '||')
//改行が2つ以上のため記号が連続している場合は、一つにまとめる
komatsu1さんは、改行文字が3つある場合に2つに、2つある場合は1つに順に減らしていくことで、改行文字を揃える処理を行なっています。

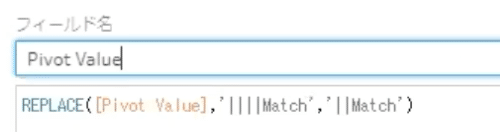
Mr.もりたは、REPLACE関数をネスト処理(複数回繰り返して実施)することで、改行文字を一度にひとつに減らす処理を1度に行っています。

SPRIT 後ろから
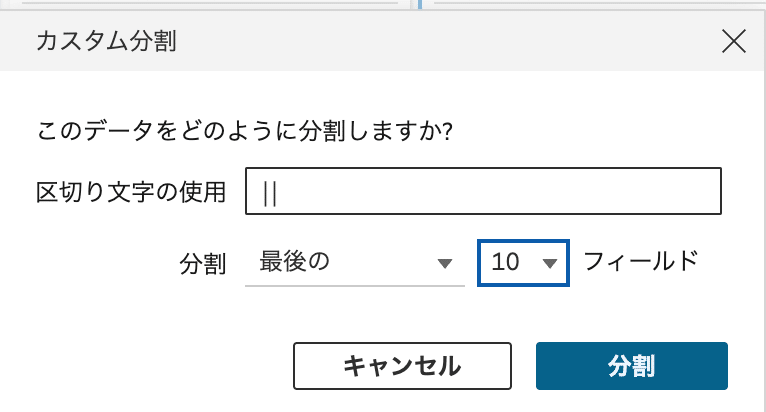
今回の課題への対処方法で、最も効率的な内容です。
Mitamuuさんは、ScoreとTeamに関するデータが文字列の後ろから綺麗に順番に並んでいることに気づきました。
カスタム分割から、最後の10フィールドで分割する作業を実施し、必要な分割処理だけをフィールド名を変更することで処理を完結させています。
データ並びの法則性を見つけたことだけでなく、デフォルト機能での分割で「最後の」、複数フィールドを選ぶ対処に気付いたところが流石です。
[Home Score]
NT(TRIM( SPLIT( [Date], "||", -8 ) ))
5)その他
SPIRIT処理など、デフォルト機能で処理した後のフィールドおよび関数などの有効利用に関する MitamuuさんからのTipsです。
SPRIT処理は、デフォルトで複数のフィールドに一括分割する処理をよく使うと思います。処理の際、不要になるフィールドは残さずに分割処理後すぐに X を押して削除することをお勧めします。

また、分割処理してそのまま利用できるフィールドは、フィールド名を直ぐに修正して利用すると、余分なステップを増やさなくて済みます。

また、デフォルト機能で自動生成された関数を、コピペして他の計算式で利用することも作業性向上で有効です。複数の処理ステップでの関数式を、ひとつの処理ステップにまとめてステップ数を減らすなど、処理速度の工場に貢献出来るTipsもあります。
DATE(
'20' + TRIM( SPLIT( [Date], " ", 3 ) )
+'/' + TRIM( SPLIT( [Date], " ", 2 ) )
+'/' + TRIM( SPLIT( [Date], " ", 1 ) ))
[Home Score] などの抽出処理において、改行文字のずれがある際に正規表現を使い上手に処理を行うことが出来ます。
Riekoさんは、改行文字がひとつづつずれているケースにおいて、次の関数式で処理を行なっています。
[Home Score]
if REGEXP_MATCH(SPLIT([Matchday 1 of 38], "\", 4), '^[A-Za-z ]+$') then
int(SPLIT([Matchday 1 of 38], "\", 3))
else int(SPLIT([Matchday 1 of 38], "\", 4)) end
//正規表現で4番目が「アルファベットと空白」だったら3個目を、そうでなければ4個目を取得
[Away Score]
if REGEXP_MATCH(SPLIT([Matchday 1 of 38], "\", 6), '^[A-Za-z ]+$') then
int(SPLIT([Matchday 1 of 38], "\", 7))
else int(SPLIT([Matchday 1 of 38], "\", 6)) end
//正規表現で6個目が「アルファベットと空白」だったら7個目を取得、そうでなければ6個目を取得
6)参加者が回答したPrep フローファイル
勉強会に参加したメンバーが作成したPrepフローのファイルを公開致します。
このブログ、動画アーカイブをご覧頂いたみなさまで、ご自分で手を動かしフロー作成をされた方の少しでもご参考になればと思っています。
下記のリンク先にフローファイルを保存しています。みなさまのお役に立てれば幸いです。
https://drive.google.com/drive/folders/1MkHSulsEm3NFTKS5_4TFmXDcEHBfwEPJ?usp=sharing
7)おわりに
今回で6回目の勉強会 公開配信(ビデオ解説)になります。
毎回感じることですが、他のメンバーから聞く発表で新たな発見があり、知識の習得、定着が深く図れていると感じています。
今回は、マーケティング部署などで良く扱うアンケートやWEB情報からのデータを文字列処理するケースが想定された課題でした。
これはひどいデータと感じつつも、実務あるあるで処理対応する際のTIpsが多くあったと感じています。やはり、データソースの内容は、じっくり眺めて処理の方法を考えていくことが重要であると改めて感じた会でした。
勉強会参加者からの学びは多く、ほんとに 関連知識が増えます。
よければ、是非ご一緒に学び合いの場にご参加頂ければと思っています。
Preppin Data勉強会(Japan Preppin Data Fam)では、新規参加者を募集しています。
初心者の方も大歓迎。Tableau Prepが使い慣れた中級以上の方も、目から鱗いっぱいありますので、是非ご参加ください。
参加希望の方は、下記までメールご連絡をお願いします。
Tableau Prepユーザー会 : tableauprep.usergroup@gmail.com
この記事が気に入ったらサポートをしてみませんか?