
Tableau Prepの作業を変えるTips集16 ー重複行の削除ー

Tableau Prepユーザー会のNakajima2です。
Japan Preppin Data FamメンバーのPrep Tips集をご紹介します。
今回は、2024年6月13日開催の第9回Tableau Prepユーザー会イベントで登壇者の たっくん さんが発表された「実務あるある! 重複への対処 ~Prepでの取り組み紹介~」 の発表内容から、重複行 削除操作の基本と、たっくん さんの実務事例についてまとめてみました。
Prep Tips (31) : 重複行の削除
重複行 削除操作の基本として、第9回イベントでご紹介した [商品マスタ] と [販売データ] を結合で並べた表を作る事例でご説明します。
この事例では、 [商品マスタ] の「みかん」が2行同じデータで重複した形になっています。結合処理の基本は、1対1 対応したデータの組合せで実施 になります。この事例は、マスタデータの重複した 多対多 対応. (この事例は 2対1 対応)になっているため、結合後の金額集計が求めたい値の2倍になっています。これは求めたい正しい処理にはなっていません。
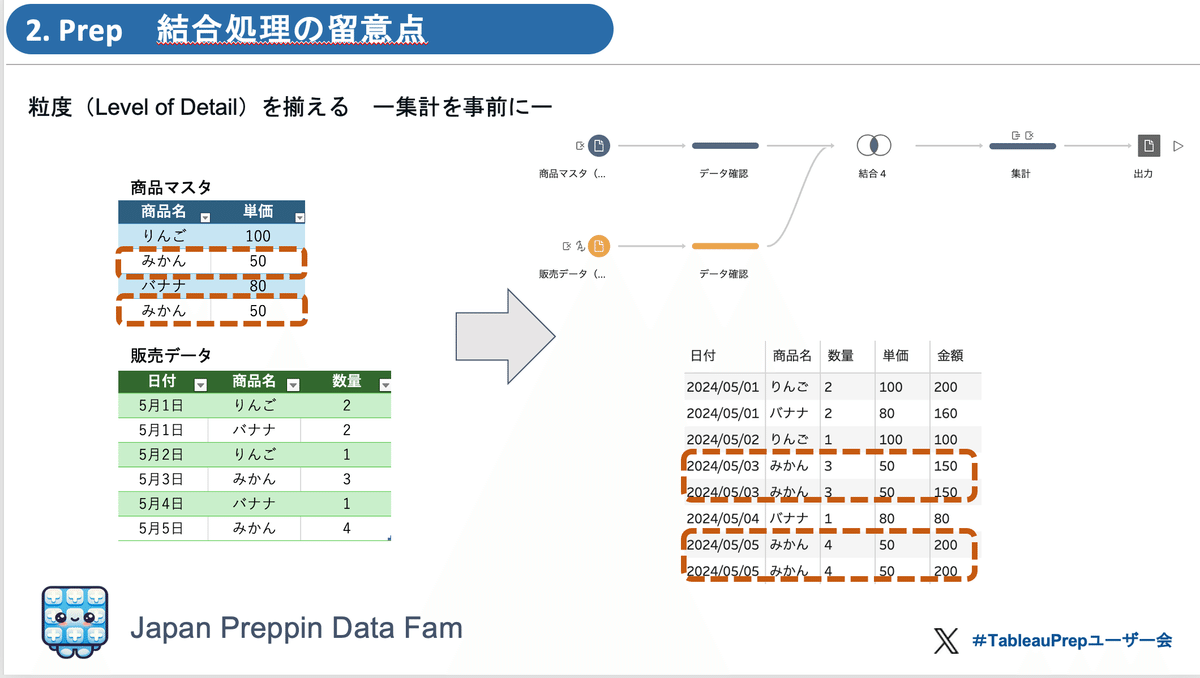
重複行の特定(削除)、集計の処理
この解決方法として、重複行の削除が活躍します。
イベントの説明では、集計を用いて、 [商品マスタ] の「みかん」データをひとつにまとめてから結合を行うことで、1対1 対応 での処理となり、求めたい合計値が得られるとのお話しをしています。
集計のステップを入れて処理を進める形です。

本稿では、先日行ったPreppin' Data勉強会で たっくん さんが指摘されたPrep最新バージョン(2024.1)で実装された 重複行の削除 を用いて処理してみます。
上記と同じ処理を 重複行の削除 を用いて行ったフローが下図になります。

ステップの数は集計を用いたフローと同じになっていますが、クリーニングステップで 重複行の削除 を行っているため、実用上はひとつのクリーニングステップ内に処理を入れることが出来ます。
具体的な処理方法は、次の通りです。UIで簡単に操作が出来るので、特別な関数などを記載する必要はありません。


重複の無いデータは 「一意」 、重複のあるデータ(「みかん」)は 「重複」 で表示される
重複が確認出来たデータをフィルタで抽出することで、重複データ(行)の削除が完了します。
結合処理後の最終データは下の通りになり、「みかん」の重複を除いた求めていた処理が出来ています。

重複行の削除 で集計処置が必要になるケース
上記の事例では、「みかん」の重複が存在するデータ(2行)とも全く同じ値で重複していたケースになります。Excelでも同様な重複行を削除する関数がありますが、同一データをひとつに抽出する処理の場合は、この処理で問題は生じません。
注意しなければいけいないケースは、重複するデータで値が異なるケース。
例えば、 [商品マスタ] の「みかん」で、価格がある期日で改定されデータの値が更新されているようなケースです。下記のような場合に相当します。

この場合、単純に重複行の削除を行ってしまうと、価格改定の値段がフローに反映されない可能性が生じます。
このようなケースでは、集計処理(またはそれに準じる処理)を施し、価格改定が行われた最新データを利用するように設定する必要があります。本稿では、集計処理で [データ更新日] の最新日を抽出するフローを作成してみます。
なお、[販売データ] は、全て価格改定後の5月の売上データになっています。

この例では、 [商品マスタ] の [みかん] を最新の価格データで扱う必要があります。下のように、集計処理において「集計フィールド」の設定を [データ更新日] フィールドのデータで最大値を取るようにして集計しています。
これにより、結合処理後のデータで、 [みかん] を最新の価格データを用いた計算となるデータが得られます。


なお、今回は価格改定で値上げとなり [価格] の最大値を取ることでデータ処理が行えていますが、同じ製品で複数回に渡り価格改定がされており、価格が上下しているような場合は最大値で集計すると誤ったデータ抽出になるケースもあり得ます。
その際は、 [データ更新日] の最新データ(このフィールドの最大値)をFIXED関数で固定して利用するデータを特定し、フィルタを利用して最終改訂のデータとして利用するなどの処理が必要になります。
状況に応じて、適宜 工夫は必要です。
Prep Tips (32) : 実務あるある!重複への対処
イベント登壇者の たっくん さんが発表した実務に即した「重複」で困る案件への対応事例を発表して頂いています。
実務でPrep利用歴が3年ほどの たっくん さん。データの重複には日頃から悩まされているとのことで、データ重複の解消には思い入れもひとしお。さまざまな方法での解決策(Tips)をご紹介して頂きました。
そもそも「重複」で困るのはどんな時?
実務でそもそもデータ重複で困るケースはどのような時でしょうか?
次の2ケースに大別されるとのこと。
① 注目値の総計は問題なし。付帯情報が重複

この後の説明は、こちらのケースを取り上げます
② そもそも注目値の総計がおかしい

付帯情報の「重複」を統一する方法
付帯情報が重複しているケースで、この後の説明が続きます。
事例として、付帯情報となる顧客氏名のデータを「顧客マスタ」として更新作業が出来れば統一出来るものの、基幹システムとの連携が必要になりマスタの更新が難しいケースになります。
基幹システムを利用せず、元のデータから「顧客マスタ」に関わるデータを取り出して処理を試みる解決法を3種ご説明頂きました。[氏名] のデータを最新に統一する点がポイントになります。
解法1 : 集計stepを使い倒して自己結合
元データから
(1)[客番] ごとの [日付] の最大値を抽出
(2)[客番]/[日付]/[氏名]でグループ化
(3)(1)と(2)を内部結合で合致する行に絞り「顧客マスタ」を作成
(4)(3)を元データと自己結合する
の処理で、最新の [氏名] データを得るものです。

解法2 : LOD関数でスマートに作って自己結合
解放1の処理において、(1)の処理をFIXED関数を利用して分岐フローを省略する形にしたものです。

ここでは、次のFIXED関数を利用して、集計後のデータから「顧客マスタ」を作成する処理を実現しています。
{ FIXED [客番] : max ( [日付] ) }
解法3 : Partition関数で1 Step 化
更に処理を精査し、Partition関数で [客番]/[日付]/[氏名] を並び替えし、FIXED関数で最新の [氏名] データを得ることが出来ます。



こちらの内容は、イベントで たっくん さんが発表された処理以後の重複データをフィルタした処理まで含めています。
1 Step のフローとすることで、解法1で分岐と内部結合を駆使して処理を行っていたフローが、とてもシンプルな処理で、かつ処理手数も少なくフローが完結するようになっています。
フローの実行に関し、1 Step 化が
・フローの認識性向上
・フロー処理速度の向上
に効果を出していると考えらえ、実務面でのメリットを生み出していると思われます。
応用力として理解していると、とても有益で、Prep筋がちょっと鍛えらえたかなと思える良いTipsだと思います。
この記事が気に入ったらサポートをしてみませんか?