
書記が数学やるだけ#464 数量化1類

質的データを数値化する方法として,数量化理論について見ていく。
以前の分析(分散分析)はこちら:
問題

説明
数量化理論は,統計数理研究所元所長の林知己夫によって1940年代後半から50年代にかけて開発された。

解答
データは以前の記事を参照。
# ライブラリの読み込み
import numpy as np
import pandas as pd
import scipy as sp
import statsmodels
import statsmodels.api as sm
import statsmodels.formula.api as smf
# データの読み込み
data = pd.read_csv('分散分析-1.csv')
data
今回説明変数とするFERTILは,質的変数で名義尺度であるため,ダミー変数(いわゆるOne-hot表現)に変換する。ここで,drop_first=Trueと指定することで最初のカテゴリーが除外されk-1個のダミー変数に変換される。
ここでは,1→(0,0),2→(1,0),3→(0,1)と変換している。
dummies=pd.get_dummies(data["FERTIL"], drop_first=True)
dummies
色々と整理する。
data=pd.concat([data, dummies], axis=1)
data=data.drop(["FERTIL"], axis=1)
data=data.rename(columns={2:"i", 3:"ii"})
data
あとはこのデータを重回帰分析にかければよい。計算内容などは全て同じである。
#重回帰分析と同様
model = smf.ols('YIELD ~ i+ii', data=data4).fit()
model.summary()
ところで,今回のデータをグラフで表したのは下図である。
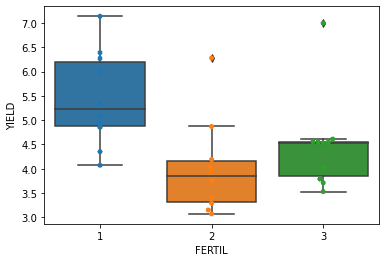
回帰係数から,YIELDの値は肥料ごとに異なり1>3>2の順であることが読み取れる。また,肥料ごとにどれくらいの差があるかの数値化もなされている。
本記事のもくじはこちら:
学習に必要な本を買います。一覧→ https://www.amazon.co.jp/hz/wishlist/ls/1XI8RCAQIKR94?ref_=wl_share