
データの準備

シーケンスデータから得たリードがゲノムのどの領域に由来するかを推定するために、リファレンスシークエンス(対象生物のゲノムの塩基配列が記述されている)データとアノテーション(遺伝子などのゲノム上の位置を記述されている)データを準備する。(ENSEMBLからダウンロード)
コマンド lftp ftp.ensembl.org/pub/
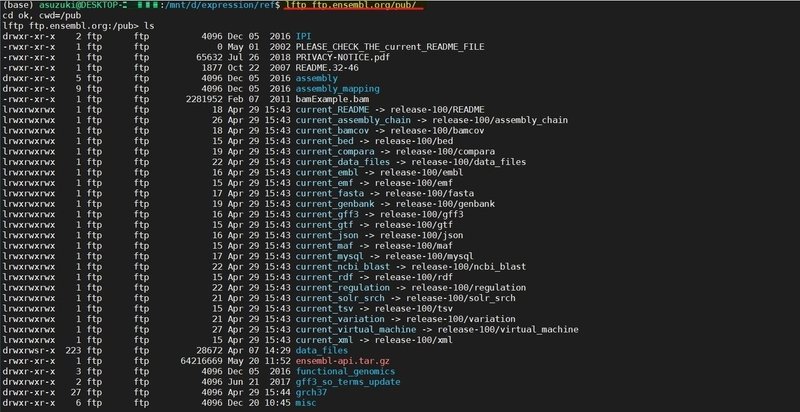
enssembl.orgのpubフォルダの下にあるdnaフォルダからダウンロードします。
lsコマンドでファイル一覧を確認しながら進めるとわかりやすいです。
dnaフォルダのファイル一覧
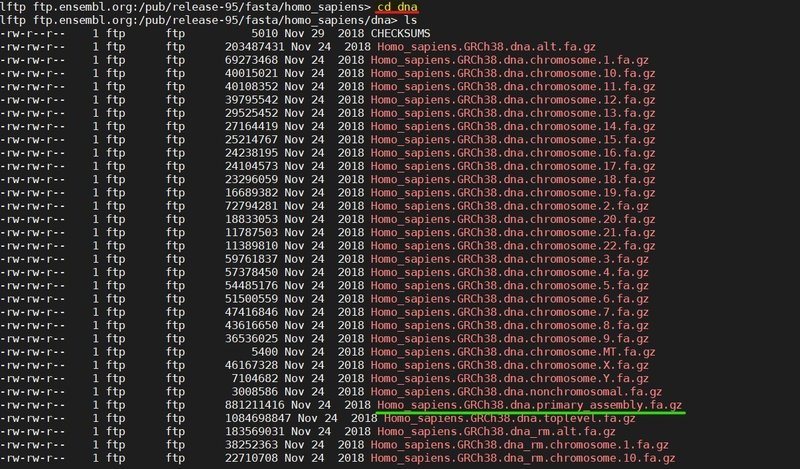
この中の、Homo_sapiens.GRCh38.dna.primary_assembly.fa.gzファイルをダウンロードします。
コマンド get Homo_sapiens.GRCh38.dna.primary_assembly.fa.gz
![]()
ダウンロードが終わったら、一度 exit で lftpを終わらせてもう一つアノテーションファイルをダウンロードします。
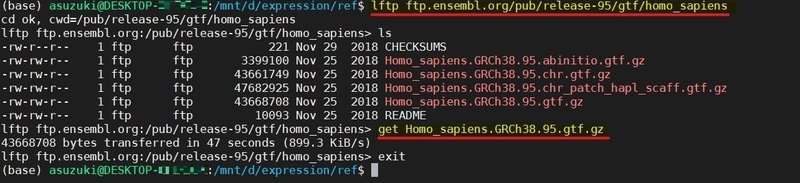
コマンド lftp ftp.ensembl.org/pub/release-95/gtf/Homo_sapiens
Homo_sapiensフォルダのHomo_sapiens.GRCh38.95.gtf.gz をダウンロードします。
それと、kallisto(転写産物の量を定量化するためのプログラム)で使用するため転写産物(cDNA)のリファレンス配列もダウンロード。
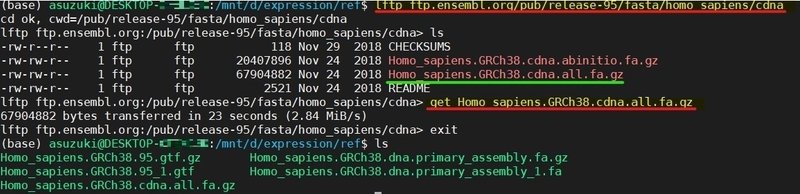
Homo_sapiens.GRCh38.95.gtf.gzとHomo_sapiens.GRCh38.dna.primary_assembly.fa.gzを解凍。

ひとまず、これでデータの準備ができました。
この記事が気に入ったらサポートをしてみませんか?