
今から追いつくStable Diffusion!Colabでの始め方と使い方【Mac OK / コード不要】

この記事は、「初めて画像生成AIを使う人」が「1番簡単な方法でStable Diffusionを始める」という内容です。
加えて、
・基本機能
・プロンプト
についても、網羅的に解説しました。Stable Diffusionの基本を身につけられます。
動画版はこちら。より詳しく、分かりやすく解説したサポートと特典付きの動画講義です。
■ Stable Diffusionとは何か ■
Stable Diffusionは、2022年8月に公開された、オープンソースの画像生成AIサービスです。主に、文字からイラストを生成することができます。素人であっても、プロ並みのイラストが短時間で作成可能です。
例えば、以下のような画像が、数分〜数時間で、作ることができます。

Stable Diffusionで生成される画像は、プロが描いたような高品質なイラストや絵画、写真のようなリアルな画像まで幅広いです。どんな絵柄も再現できると言っても、過言ではありません。
そんなハイクオリティな画像を、短時間で出力することができます。
さらに、Stable Diffusionは、頻繁に新機能の開発が行われていて、便利な機能が次々と生まれている状態です。まさに、革命だと思っています。
■ Stable Diffusionのメリット・デメリット
□ メリット
画像生成AIサービスは、MidjourneyやAdobeなど、色々あります。その中で、最も
・多機能
・コントロール可能
・絵柄が豊富
なのがStable Diffusionであり、Stable Diffusionを使うメリットです。


ちなみに私は、クラウドソーシングなどで、副業(複業)として、たまにお仕事を受けています。
まだまだ簡単な業務しか受けていませんが、クライアントの細かい修正指示に対応できる画像生成AIサービスは、現状Stable Diffusionしかありません。もちろんStable Diffusionであっても、できないことは山ほどあるので、基本的に
・対応できる仕事を選ぶようにする
・イラストレーターやデザイナーと協力する
感じでやっています。
あと、アダルト画像を生成できるのは、オープンソースであるStable Diffusionの強みです。他のAIサービスは、営利企業が運営しているため、コンプライアンス的にアダルト内容はできません。
これから解説する「Googleドライブと連携するColab版」でStable Diffusionを行う場合でも、いちおうアダルトな画像は生成可能です。ただし、Googleドライブと連携する関係で、児童ポルノに間違われるような画像を生成すると、GoogleアカウントがBANされる可能性があります。
とはいえアダルト画像を生成したい方もいると思うので、Googleドライブと連携しないColab版のやり方も解説します。こちらなら、基本的にどんな画像を生成しても大丈夫です。何か規制を受けた事例は、今のところ聞いたことがありません。ただし自己責任でお願いします。
また、高性能なPCでStable Diffusionを使う、ローカル環境版のやり方も、今後解説する予定です。Stable Diffusionが快適に動作するには、20万円くらいのWindows PCが必要です。これについての解説動画は、今後、別の動画講義で行います。少々お待ちください。
□ デメリット
Stable Diffusionのデメリットは、始め方や使い方が、少し難しいところです。多くの機能やパラメータがあり、習得するのに時間がかかります。
今では、画像生成AIを使えば、誰でも高品質なイラストが作れてしまいます。そのため、ただ絵のクオリティが高いだけでは、あまりスゴイとは思われません。
何ができたらスゴイかと言うと、「自分の目的にあった画像を、コントロールして生成する」ことだと私は思っています。お仕事に使う場合も、このスキルが必要です。そのためには、やはり、多くの機能があるStable Diffusionを使える必要があります。
Stable Diffusionは少し難しいかもしれませんが、網羅的かつ高品質な解説動画は、私が作っていきます。少々お待ちください。
■ Stable Diffusionで、できること・できないこと
□ できること
テキストから高品質な画像を作れる以外にも、多くのことができます。
特にControlNetを使うことで、以下のことができます。
・同じキャラクターを維持したまま、別の構図で画像生成
・逆に、顔や髪型、服装などの一部だけを差し替える
・同じイラストのまま、色だけを変える
・好きなポーズを取らせられる
・落書きから高品質な画像を生成
・同じキャラクターを維持したまま、画像の拡大
・写真からイラスト作成。イラストから写真を作成。
・特殊な絵柄の再現
・アダルト画像の生成
ここまでコントロール可能なのは、現状ではStable Diffusionだけです。他の画像生成AIではできません。
□ できないこと
以下は、Stable Diffusionだけではなく、全ての画像生成AIサービスで困難なことです。
・複雑だったり、有名ではない、手指の表現
・複雑だったり、有名ではない、ポーズの表現
・細かい表情の調整
例えば漫画制作は、AIだけでは、まだできません。
とはいえ、AI業界の発展はとても速いです。そのため、上記の「できないこと」も、数ヶ月〜数年以内にできるようになる可能性が高いです。
■ 開発元はどこ?


Stable Diffusionを開発したのは、ドイツにあるミュンヘン大学のAI研究チームです。他にも、Runway(アメリカ)やStability AI(イギリス)が開発に関わっています。(参考:Wikipedia)
また、Stable Diffusionはオープンソースなので、ソースコードが公開されています。
■ Stable Diffusionの種類、SDXLやSD1.5の違い
Stable Diffusionはオープンソースなので、派生の画像生成AIサービスが色々あります。
その中でも、有名であり、多機能かつ高性能なのが「Stable Diffusion WebUI」というものです。名前のとおり、Stable Diffusionを、Web画面上でプログラミング不要で使えるようにしたものです。
「Stable Diffusion」と呼ばれるものは、ほとんどが「Stable Diffusion WebUI」のことを言っています。そのため私の記事でも、上記の2つは区別せずに、まとめて「Stable Diffusion」と呼ぶことにします。
□ SDXLってなに? SD1.5との違いは?
XLや1.5というのは、Stable Diffusionのバージョンのことです。Stable Diffusionはよく「SD」と略されます。
紛らわしいですが、「Stable Diffusion WebUI」のバージョンではなく、WebUIの中身のStable Diffusionのバージョンの事を言っています。
SDXLというのが、最新のStable Diffusionです。
既にStable Diffusionを使ったことがある方は、自分がどっちのStable Diffusionを使っているか、分からない方もいると思いますが、ほとんどの方はSD1.5を使っていると思って大丈夫です。
「Stable Diffusion WebUI」は、SDXLにもSD1.5にも対応しているので、実際は同じStable Diffusion画面で、どちらのバージョンも使えます。つまり、これから始めるStable Diffusionを使えば、何もしなくても
・有名な方のSD1.5
・最新の方のSDXL
を使うことができます。
最新のSDXLだけ使えば良いと思うかもしれませんが、SDXLは
・そこまで品質が上がっていない
・データ容量が大きい
・情報がまだ少ない
・まだ最新のSDXLに対応していないSD1.5の機能がある
など、SDXLだけを使うには、まだ微妙な状況です。
後で解説するモデルやControlNetもSDXL用のものを使う必要があり、PCのデータ容量を圧迫してしまいます。
情報が少ないのもあり、初心者の方は、SD1.5を使うことをおすすめします。この動画講義でも、SD1.5を使う前提で説明していきます。
■ Stable Diffusionの始め方 ■
■ Google Colabとは

Google Colabとは、正式名称はGoogle Colaboratoryで、Googleのリソースを使いWeb画面上でPythonを動かすことができるサービスです。GPUなどのリソースが提供されるので、自分のPCが低スペックでも作業できます。
Colabは主に機械学習などで使われていますが、Stable DiffusionはPythonというプログラミング言語で作られているので、Stable DiffusionもColabを使って動かすことができます。
□ Colabの料金比較
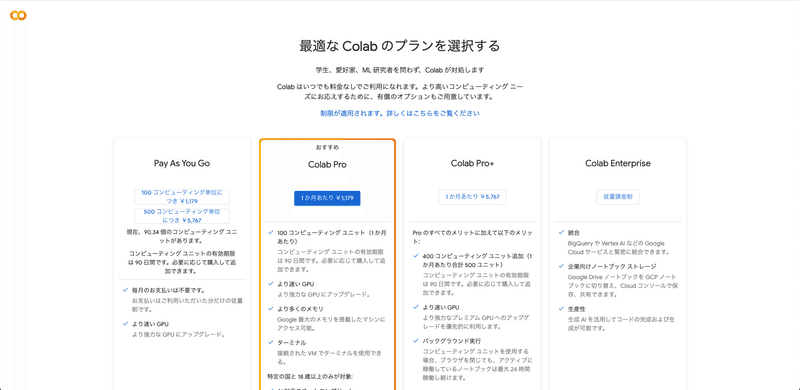
Stable Diffusionを使うときに、Colabの有料プランに入っていないと、エラーが出てしまいます。そのため、支払いは最初に済ませておいてください。
Colabのプランは主に3つあります。
・Pay As You Go:1179円 または 5767円(買い切り)
・Colab Pro:1179円 / 月 (定額で使い放題ではない)
・Colab Pro+:5767円 / 月 (定額で使い放題ではない)
Colab Proは使い放題ではなく、100コンピューティングユニット分を毎月もらえる感じです。次月が来る前に使い切った場合、足りない分はPay As You Goで追加購入する必要があります。
使っている時間分だけ、コンピューティングユニットが消費される仕組みです。
初心者の方は、Pay As You Goがおすすめです。Pay As You Goは買い切りなので、解約する必要はありません。お試しにちょうどいいです。
Proプラン以上とPay As You Goプランでは
・より多くのメモリ(RAM)
・ターミナル
などの違いもありますが、Pay As You Goでも十分なメモリが割り当てられるので問題ありません。また、ターミナルも不要です。

後でまた説明しますが、Stable Diffusionで画像生成するときに使うGPUは、3種類から選べます。

1番性能が低いものだと、1時間あたり約2ユニットを消費します。1日3時間Stable Diffusionを使うなら、1ヶ月で180ユニットの消費となり、およそ2000円かかる計算です。1日5時間使用なら、月3500円くらいです。
1番性能が低いGPUであっても、生成スピードなどは問題なく、快適に使えています。
ちなみに、性能が高いPCが必要なローカル環境の場合、PC代金で20万円くらいかかります。4年間PCを使うとしたら、1年あたり5万円、1ヶ月あたり4000円くらいかかる計算です。3年間なら、1年あたり6.5万、1ヶ月あたり5500円くらいかかります。
Stable Diffusionでは、イラストも写真風の画像も生成できます。ソフト代金だけで、イラスト系なら月に数千円、写真風の人物画像を3DCGで作るなら、月に数万円がかかります。画像素材サイトでも、有名なサイトは月に5000円以上はかかります。これらを踏まえると、画像生成AIにかかる費用は、高すぎることはないと思います。
無料の画像生成AIサービスもいくつかあります。ただし、運営してる企業もボランティアでやっている訳ではない上に、コンピュータの代金も相当かかっているはずです。そのため、Midjourneyのように有料になったり、途中から画像枚数などの制限が厳しくなると思っておいた方が良いです。
ちなみにStable Diffusionは、投資家から何百億円という大規模な投資を受けているので、現状オープンソースで運営できています。
■ Googleドライブと連携したColabで始める方法

ColabでStable Diffusionを使うなら、初心者ほど、Googleドライブと連携する方法がおすすめです。

特に、TheLastBenさんが開発したテンプレートを使うと、プログラミング不要でStable Diffusionを使うことができます。また、生成した画像は、自動でGoogleドライブに保存されるので、わざわざ自分で保存する手間もありません。さらに、このテンプレートを使う場合、ローカル環境と設定方法がほとんど同じなこともメリットです。拡張機能を追加したいときに色々調べると、ローカル環境の情報がよく出てきますが、それと同じ手順で解決できることが多いです。
他のColabでStable Diffusionを使うとなると、プログラミングコードを自分で編集しなければならず、Webエンジニアの方じゃないと、けっこう大変です。生成した画像も、自分で1つ1つ保存する必要もあり、面倒です。いちおう後で紹介しますが、私がサポートできる範囲は限られるので、ご了承ください。
これから始めていきますが、最初にColabの購入を済ませてください。無料版で利用すると規約違反なので、エラーが出てしまいます。
Googleアカウントは、Googleドライブの容量に空きがあるアカウントを使うことのがオススメです。Googleドライブとは、ネット上にデータを保存できるサービスのことで、DropboxやiCloudと同じようなものです。
Stable Diffusionを本格的に使うとなると、けっこう容量が必要になります。後で説明しますが、特にモデルとControlNetの容量が大きく、50GBくらいは必要です。そのため、Googleドライブの無料容量15GBでは足りなくなります。対処するには、定期的にデータを削除したり移動するのもいいですが、容量の追加購入がオススメです。Googleドライブの容量については、後から追加購入できるので、足りなくなったときに買ってください。月に数百円です。

購入が済んだら、Colabのこの画面を開きます。

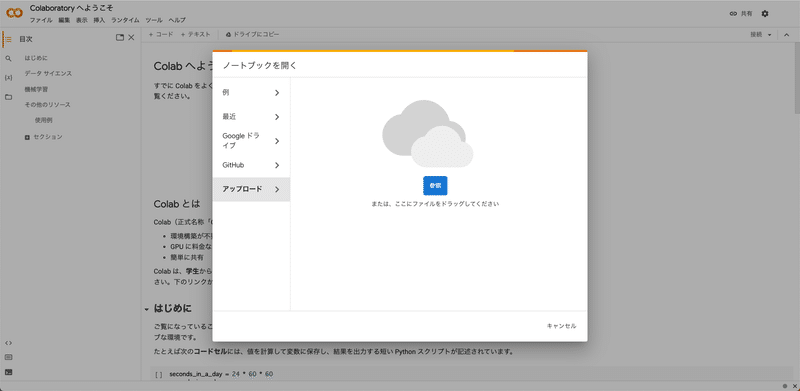
四角い画面が表示されますが、閉じてしまった場合は、画面左上のファイル →「ノートブックをアップロード」をクリックしてください。

次に、ここにGitHubのURLを入力するために、GitHubのサイトを開きます。
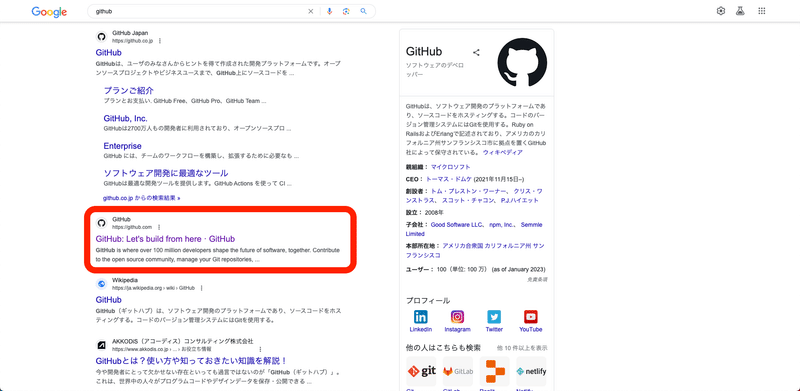
「GitHub」で検索すると公式サイトが2つ現れますが、2つ目のGitHub.comを開きます。

画面右上の検索欄に「Stable Diffusion」と入力し、検索してください。

少し下の方にある「TheLastBen/fast-stable-diffusion」をクリックして開いてください。

この画面になります。緑色の「コード」ボタンをクリックして開き、URLをコピーしてください。

コピーしたURLを、先ほどのこの欄に貼り付けて、エンターキーを押してください。
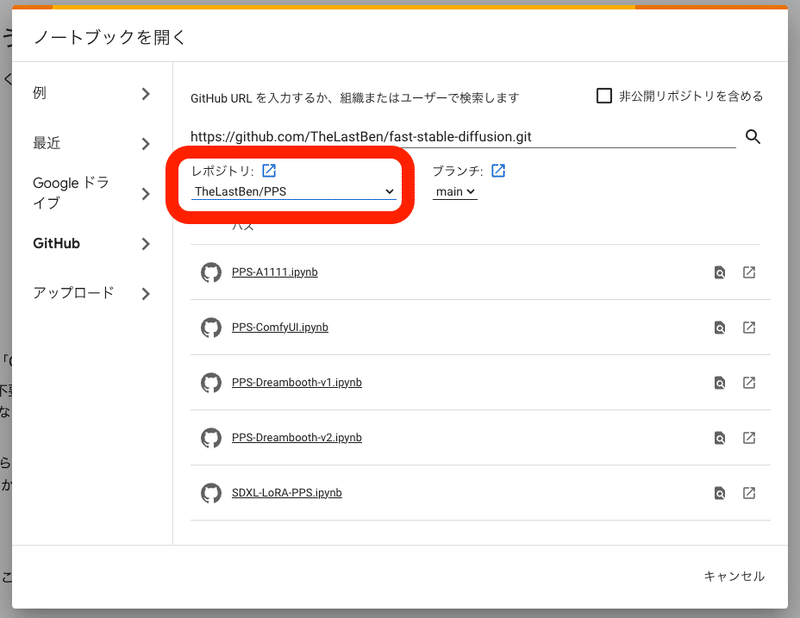

次に、レポジトリを「TheLastBen/fast-stable-diffusion」に変更してください。
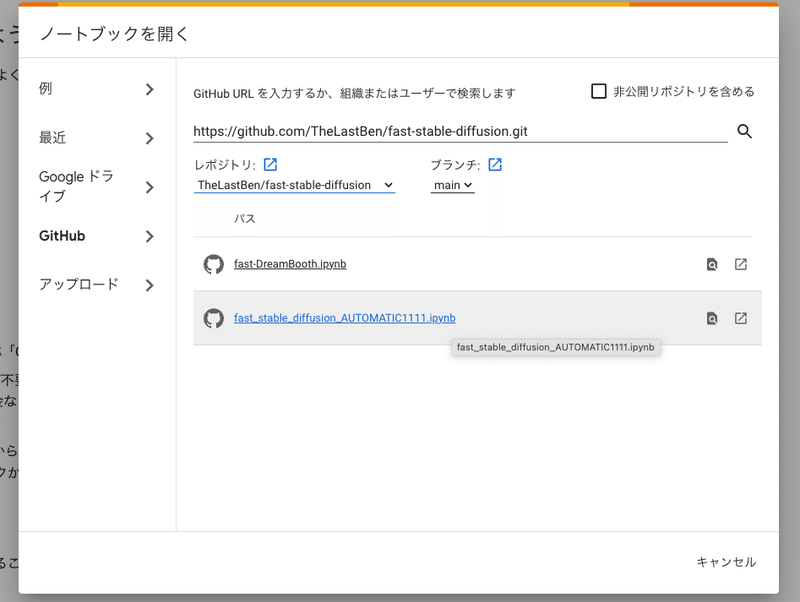
次に、2番目のこれをクリックしてください。
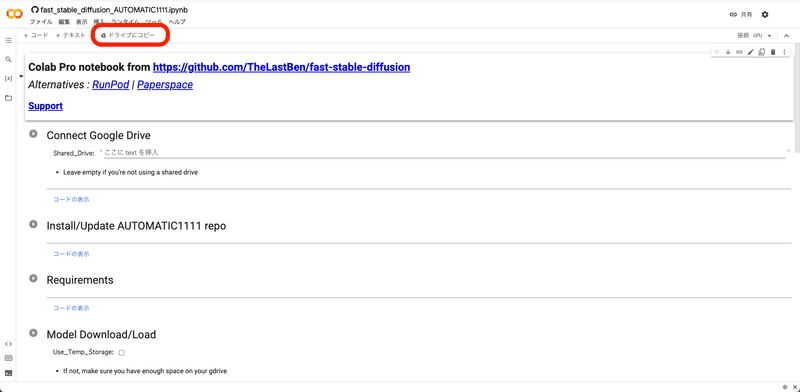
このような画面になります。
次に画面左上の「ドライブにコピーを保存」をクリックしてください。これで、このページのコピーが、Googleドライブに保存されます。
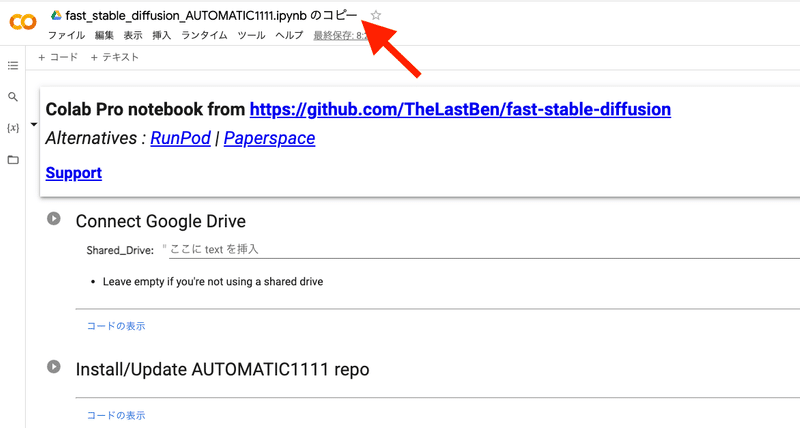
これ以降は全て「コピー」の方で操作するので、注意してください。先ほどの「コピーじゃない方」のページ↓は閉じてください。

「ランタイム」→「ランタイムのタイプを変更」から、「ハードウェア アクセラレータ」がGPUになっていることを確認してください。
・A100 GPU
・V100 GPU
・T4 GPU
のいずれかです。
GPUのタイプは3つあり、どれを選んでも大丈夫です。A100が1番性能が高く、T4の性能が1番低いです。性能が高いほど、画像生成の時間が速くなりますが、コンピューティングユニットの消費も多くなります。
T4でも生成スピードは十分に速いです。大量かつ大きめの画像を生成する場合でなければ、T4をおすすめします。

これからStable Diffusionを起動します。ランタイム → すべてのセルを実行 をクリックしてください。

すぐに、これが表示されるので、「Googleドライブに接続」をクリックしてください。Googleアカウントへのアクセスリクエスト画面が表示されるので、「許可」をクリックしてください。

起動は、毎回5〜10分くらい待つ必要があります。「Model loaded in …」が表示されたら完了です。URLをクリックしてStable Diffusionを開いてください。
「Model loaded in …」が表示される前にURLは表示されますが、すぐにクリックしても読み込みに時間がかかったり、エラーが出ます。「Model loaded in …」が表示されるまで待ってください。
また、エラーなどが出ると、そのコードはこの欄に表示されます。
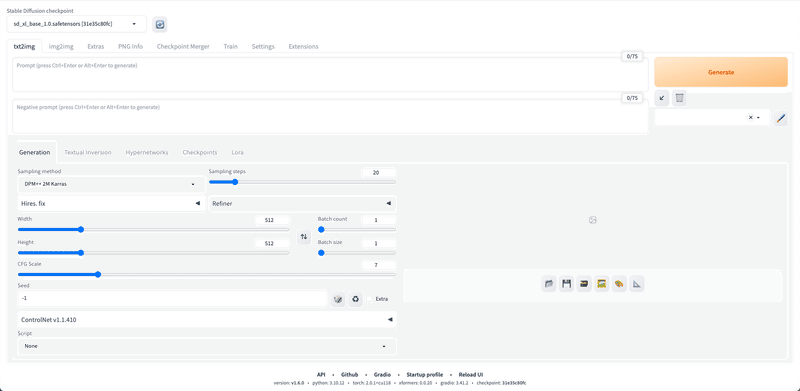
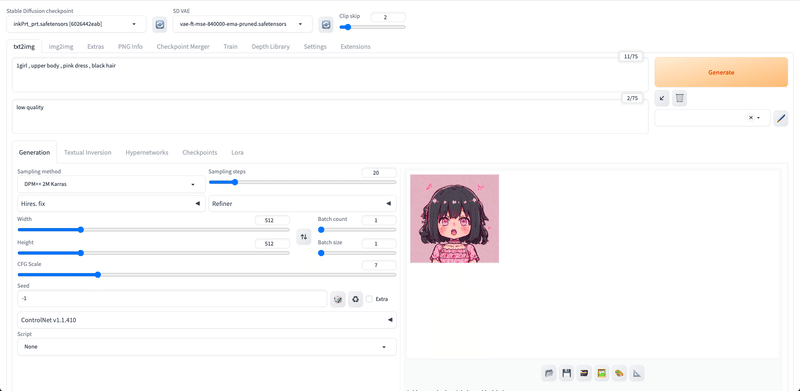
お疲れさまでした!これがStable Diffusion WebUIの画面です。
※ DeepL翻訳が起動すると、なぜか不具合が生じることがあります。そのときは「元の言語を表示する」をクリックし、翻訳されないようにしてください。もし不具合が生じた場合は、この画面を一旦閉じて、先ほどのURLをクリックしてもう1度開いてください。
エラーが出てしまったり、うまく行かなかった場合の対処法については、後の方で話しています。そちらを確認してください。
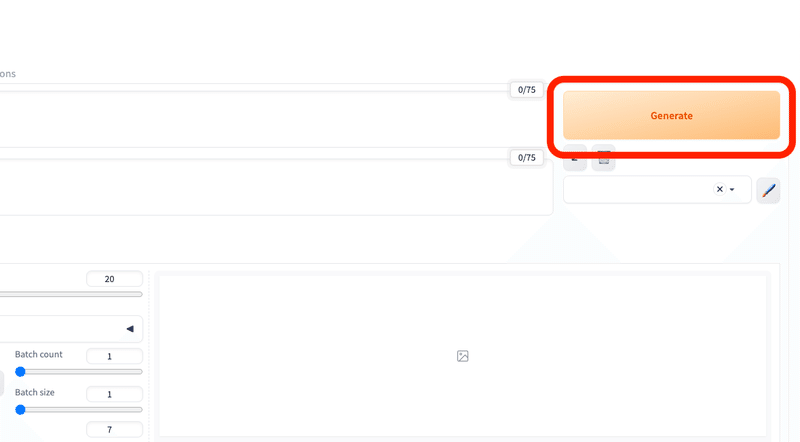

画面右上の「Generate」ボタンをクリックすると、画像の生成ができます。何も設定をしていないので、変な画像が生成されますが、問題ありません。
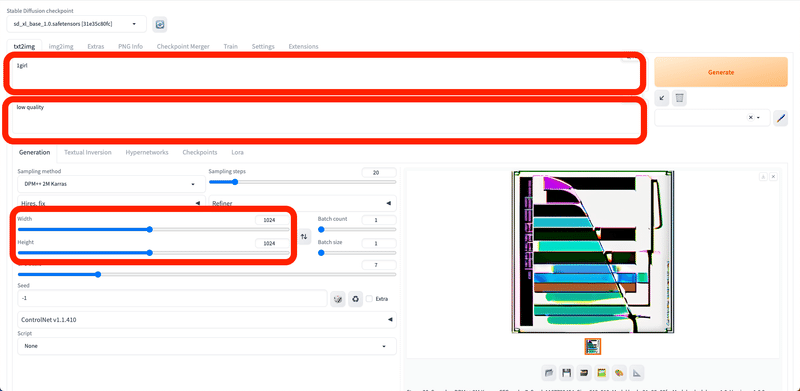
上の文字入力欄に、生成したい画像の特徴を入力します。入力する文字や文章は「プロンプト」と呼ばれています。プロンプトは、英語で、半角カンマで区切って入力してください。
その下の文字入力欄には、生成したくない画像の特徴を入力します。例えば「low quality」や「bad hands」などです。こちらは「ネガティブプロンプト」と呼ばれています。
Width / Heightでは、出力される画像のサイズを決められます。

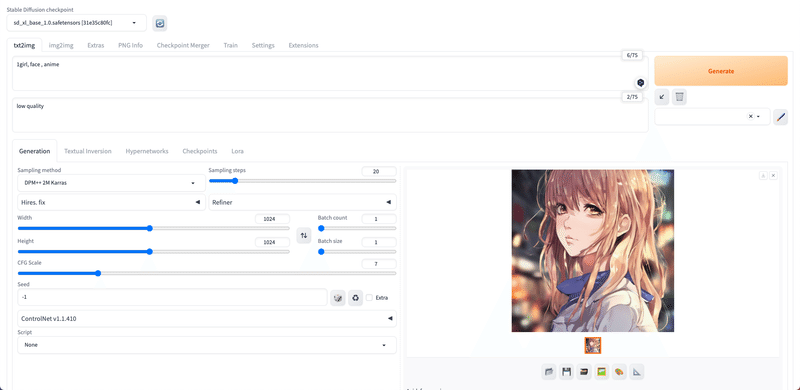
初期設定である最新のSDXLのベースモデルは、1024*1024の画像サイズでAI学習されています。そのため、このSDXL系のモデルを使う場合は、画像サイズを1024*1024に設定すると、破綻が少ない画像が生成されやすいです。
ちなみに、よく使われているSD1.5のベースモデルは、512*512の画像サイズでAI学習されています。そのため、SD1.5系のモデルを使う場合は、画像サイズを512*512に設定すると、破綻が少ない画像が生成されやすいです。
この初期設定のSDXLモデルのクオリティは、あまり高くないので、自分で好みのモデルをインストールして使うことになります。その方法は、後ほど話します。
クオリティーの上げ方は、別で解説するので、そちらを見てください。
□ Colabの使用状況の確認

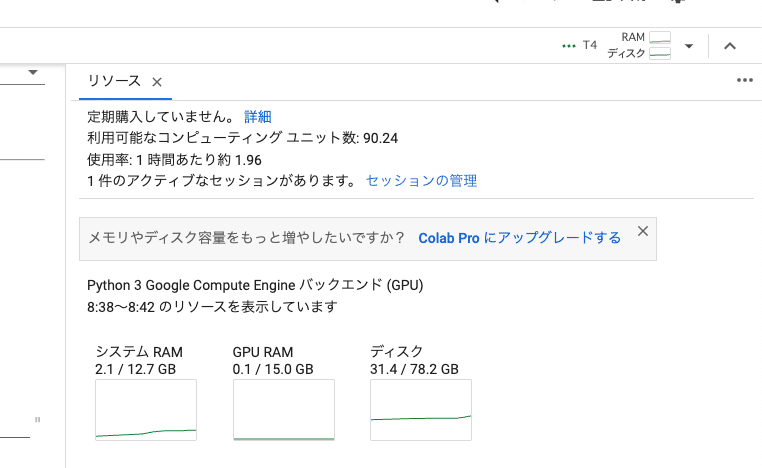
この画面に戻り、画面右上の「RAM ディスク」をクリックすると、Colabの使用状況が表示されます。もう1回おすと閉じます。
利用可能なコンピューティングユニット数:残りのコンピューティングユニットです。0になったら、追加で購入する必要があります。
使用率:1時間あたり、どれくらいコンピューティングユニットを消費するかの目安です。画像を生成していなくても、Stable Diffusionを起動しているとユニットが消費されるので、注意してください。
1件のアクティブなセッションがあります:コンピューティングユニットを使っているときは「1件」と表示されます。Stable Diffusionの起動を終了すると、「0件」と表示されます。
□ ColabでのStable Diffusionの終了方法
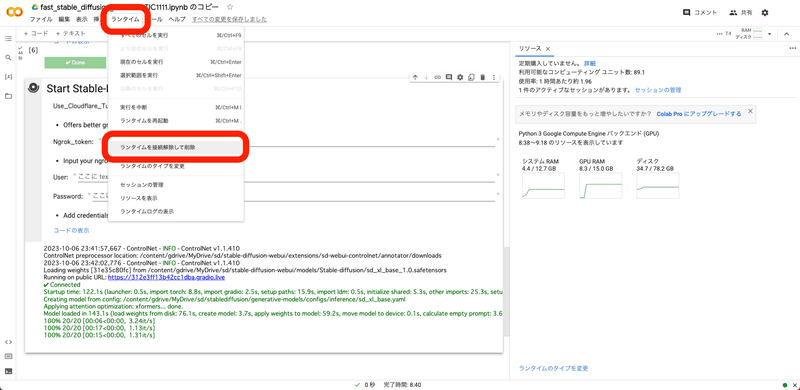
ランタイム → ランタイムを接続解除して削除 をクリックすると、終了できます。
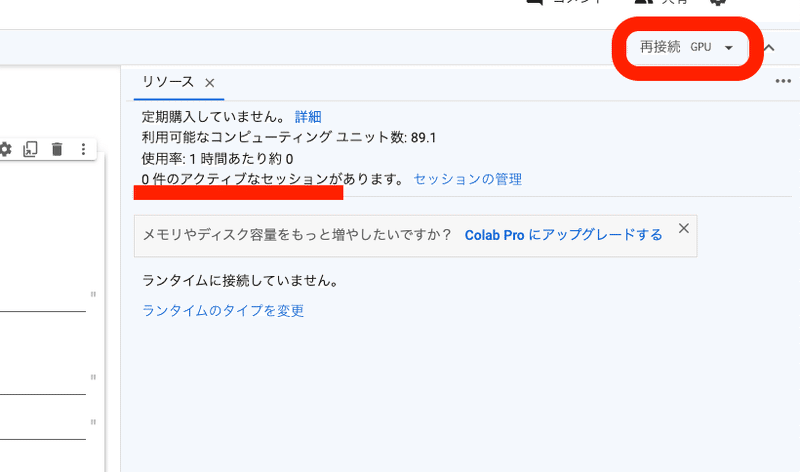
・接続 or 再接続
・0件のアクティブなセッションがあります
となっていれば、終了できています。
また、最長で12時間たつと、勝手に終了になります。(Pro+プランは最長で24時間)あと、起動中でも操作せずに放置していると、ランタイム接続解除されて終了されます。
□ Colab解約方法(参考:Colab公式サイト)
Colab Pro/Pro+プランを定期購入した方は、 Colab から解約可能です。解約した場合でも、Colab Pro/Pro+は最後の支払いから1ヶ月間利用できます。
Pay As You Goプランは買い切りであり、定期購入ではないので、解約する必要はありません。
□ 2回目以降の起動方法


Googleドライブを開き、「fast_stable_diffusion_AUTOMATIC1111.ipynb のコピー」をクリックしてColabを開きます。
後は、初めて起動したときと同じです。「ランタイム」→「すべてのセルを実行」をクリックしてください。
□ Stable Diffusionで生成した画像の保存場所

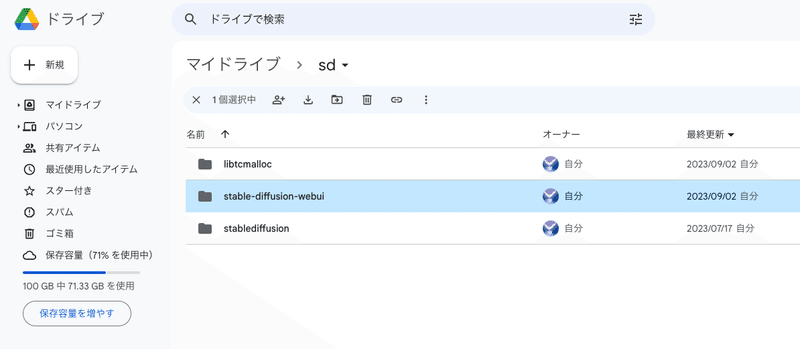
ColabでStable Diffusionを使えるようにすると、Google Driveに「Colab Notebooks」と「sd」というフォルダが追加されます。いま使うのは「sd」の方です。

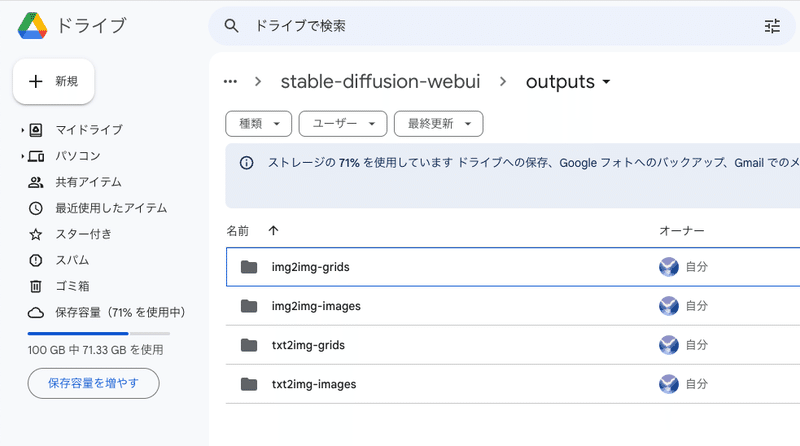
「sd」→「stable-diffusion-webui」→「outputs」の中に、生成した画像が自動で保存されていきます。
画像は容量がやや大きいので、容量を節約したい場合は、定期的に削除してください。
■ モデルの説明と、インストール方法
モデルとは「学習済みのデータ」のことです。「チェックポイント」とも呼ばれています。
・写真のようなリアルな画像を生成したいときは、リアル用のモデル
・イラストを生成したいときは、イラスト用のモデル
を使う方が、目的に近い画像を生成しやすいです。そのため、モデルは自分の目的に合ったものを選んでインストールしてください。
Stable Diffusionをインストールした際に、初期モデルも一緒に1つインストールされます。ただし、そのモデルのクオリティはあまり高くないので、モデルは自分でインストールする必要があります。

モデルを入手できるサイトは、「Civitai」と「hugging face」が有名です。Civitaiは画像生成AIに特化していますが、hugging faceは画像生成AI以外にも自然言語処理や音声処理など、様々な学習済みのデータが共有されています。
hugging faceは、Civitaiのサイトと違い画像が少なく文字がメインで、上級者向けのサイトです。今回は主に、Civitaiを使う方法を紹介します。
□ Civitaiとは?
Civitaiは、Stable Diffusionのような画像生成AIサービスで使うモデルが共有されているサイトです。モデルはチェックポイントとも言います。
様々なモデルを閲覧したりダウンロードすることができます。


サイトを見てもらえれば、どんな画像が生成できるか、だいたい分かると思います。モザイクがかかっているのは主にアダルト系のモデルです。ログインすると、すべて見れるようになります。

モザイクを解除するには、「18+」などの部分をクリックしたり、画面右上の目のマークから、モザイクの設定を変更してください。
□ Civitaiの使い方
試しに1つモデルをダウンロードしてみましょう。好みのモデルを選んでください。

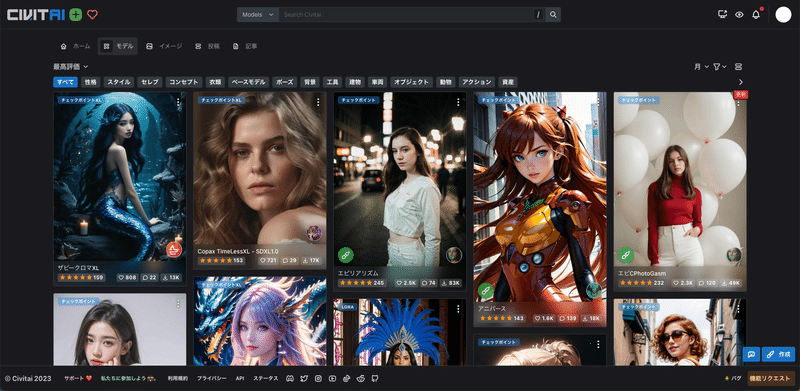
左上の「Models」をクリックしてモデルだけを表示させます。チェックポイントと書かれているのが、モデルです。後でもう1度説明しますが、初心者の方は、「XL」が付いていない方のチェックポイントを選んでください。
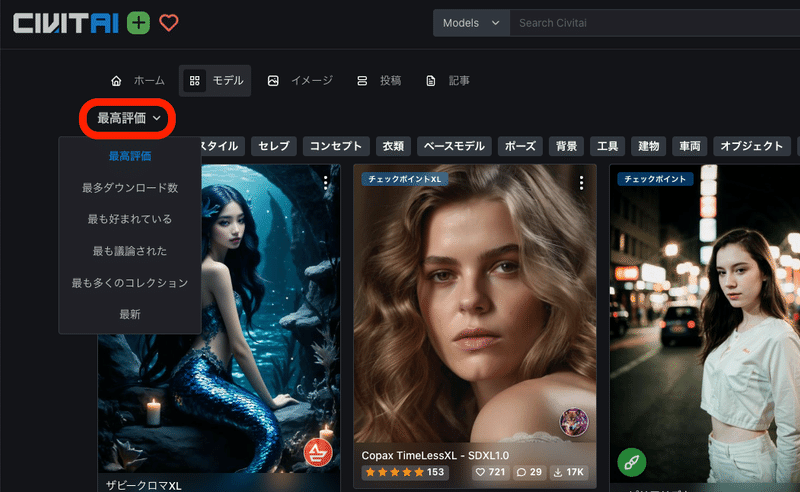

初期設定では、評価順に並んでいるので、上に位置するモデルが高評価されているモデルです。並びの設定は、上の画像のように変えることができます。
画面右上にある設定から、期間も指定可能です。
□ モデルのインストール方法
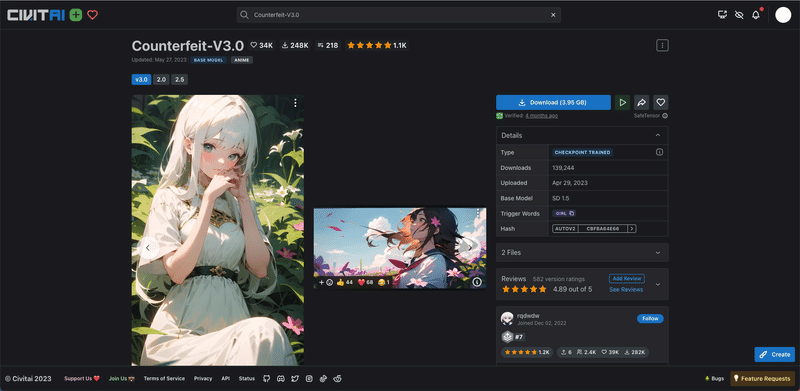
Counterfeitを例に、インストール方法の説明をします。
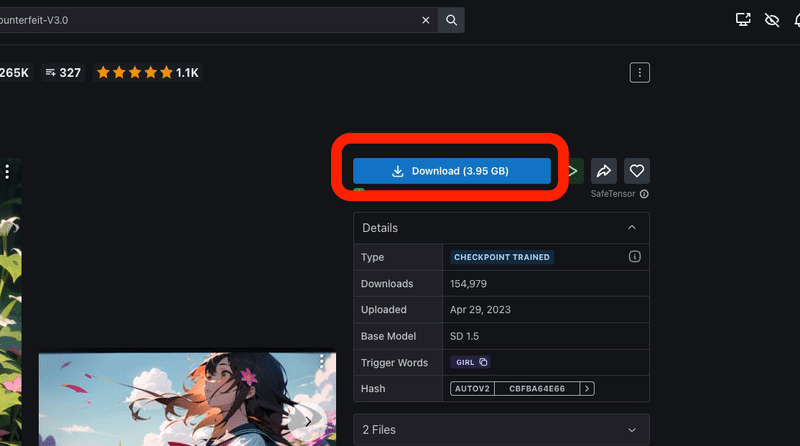
まずダウンロードしますが、モデルつまりチェックポイントは、初心者の方は「XL」が付いていないチェックポイントを選んでください。
XLはSDXL用のモデルです。SDXLは
・まだ情報が少ない
・WebUIの機能に対応していないものがある
・データ容量が大きい
・そこまでクオリティが上がっていない
などの理由で、今はおすすめしません。

とりあえず、どこでもいいので保存してください。

先ほど保存したモデルファイルを、「sd」→「stable-diffusion-webui」→「models」→「Stable-diffusion」の中に入れてください。
このフォルダには、モデルファイルのみを入れてください。別のファイルを入れたりフォルダを作ったりすると、エラーになるので気をつけてください。
モデルの容量はとても大きいです。不要なものは削除や移動して整理するか、Google Driveの容量を追加購入してください。
他のモデルも同じやり方でダウンロードできます。
Stable Diffusionを起動すると、モデルは自動でインストールされます。

Stable Diffusion起動中にモデルをインストールする場合は、チェックポイント欄の右にある、再読み込みアイコンをクリックしてください。
以上の操作は、新しいモデルを追加するときだけで大丈夫です。2回目からは、以上の操作なしでもStable Diffusionにモデルは読み込まれた状態で起動できます。
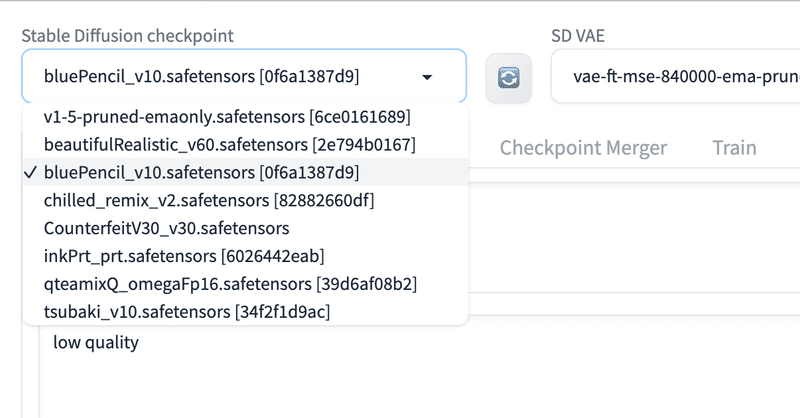
画面左上の「Checkpoint」の部分から、ダウンロードしたモデルを切り替えることができます。
■ VAEをインストールしよう


初期状態だと、生成した画像の色が薄かったり、もやもやしてることがあります。この低画質になる問題を改善できる機能があり、それが「VAE」です。
VAEは「Variable Auto Encoder(変分オートエンコーダ)」の略です。技術的な部分は難しいので、気になる方だけ「VAE(Stability AI)」を読んでください。
VAEを使うことで、生成した画像がより高画質で鮮やかになることがあります。また、VAEを入れないとエラーが出てしまうモデルもあります。

VAEを使うことで、画質が必ず良くなるわけではありません。また、VAEが元からモデルに内蔵されていて、VAEが不要なモデルもあります。そのため、モデルをダウンロードするときは、説明欄もよく読んで、VAEが推奨されているかどうか確認してください。
例えば、「Dark Sushi Mix」モデルでは、上の画像のように、説明欄に「VAE推奨」と書かれています。VAEについて言及がないモデルは、自分で試してみて、画像のクオリティが変わるかどうか確かめてみてください。
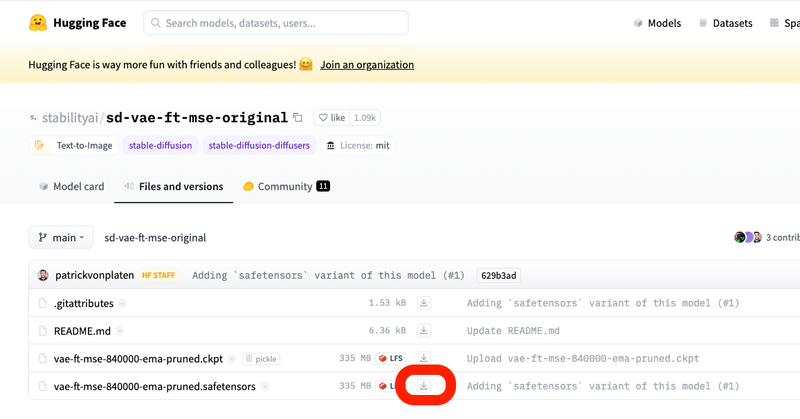
VAEは、「vae-ft-mse-840000-ema-pruned」が有名です。Stable Diffusionの開発元でもあるStability AIが作成したものです。このVAEは、リアル系のモデルにも、イラスト系のモデルにも効果があります。
この2種類のVAEファイルのどちらでも問題ありませんが、最近は「safetensors」のファイルがよく使われています。こちらの方がセキュリティ的に安全らしいので、safetensorsをダウンロードしてください。

ダウンロードしたVAEファイルは、「sd」→「stable-diffusion-webui」→「models」→「VAE」の中に入れてください。
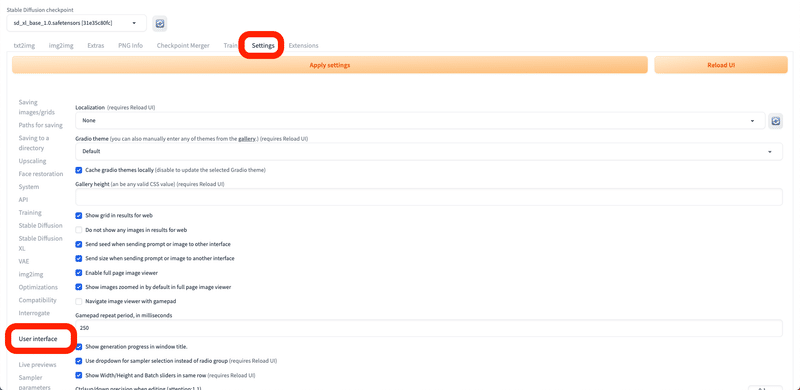

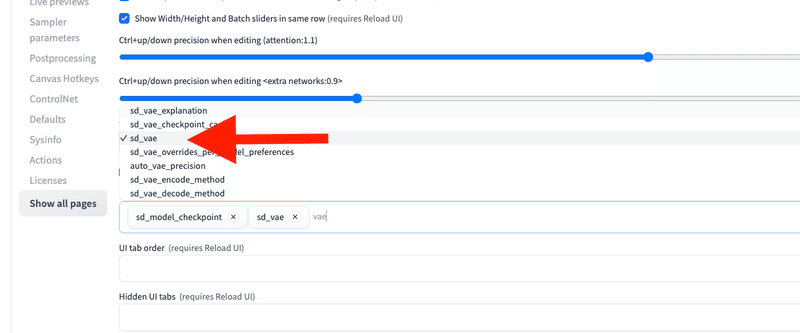
次に、「Settings」→「User Interface」を開いてください。「[info] Quicksettings list」で「sd_vae」と入力するか選択してください。

設定を変更したら、最後に「Apply settings」をクリックし、「Reload UI」をクリックしてください。
これで「VAEタブ」が表示されたはずです。
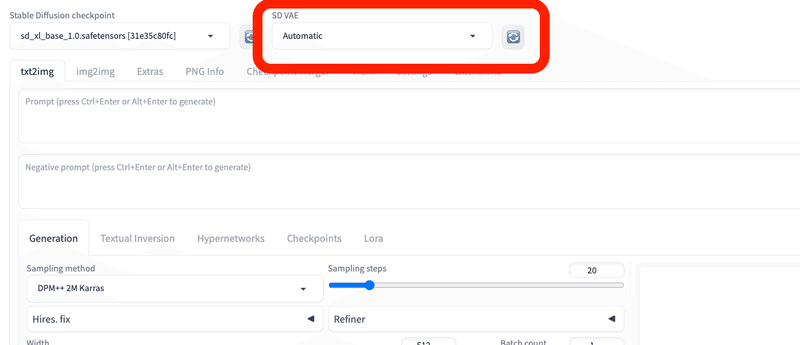
モデルと同じように、「SD VAE」の欄で、VAEを切り替えることができます。VAE840000がない場合は、読み込みマークをクリックするか、Stable Diffusionを再起動させてください。
■ Googleドライブと連携しないColabで、Stable Diffusionを始める方法 ■

□ メリット
Googleドライブと連携すると、アダルト画像が生成できないわけではありません。ただし、画像が児童ポルノだと判定されると、GoogleにアカウントBANされる可能性があります。
そのため、Googleドライブと連携しない方法では、アダルト画像を生成したいときなどに有効な方法です。この方法でGoogleアカウントがBANされた事例は、聞いたことはないですが、いちおう自己責任でお願いします。
□ デメリット
Googleドライブと連携しない方法では、生成した画像を、手動でダウンロードする必要があります。
また、使いたいモデルや拡張機能が、後で紹介するテンプレートに入っていない場合、自分でプログラミングコードを書く必要が出てきます。非エンジニアの方にとっては、やや難易度が高いです。
□ 始め方

非エンジニア向けに、自分でコードを書かなくてもStable Diffusionを実行できるテンプレートが、色々公開されています。
その中でも、safa-dayoさんが開発した「Colabコマンドのテンプレート」が分かりやすいので、これを使ってStable Diffusionを始めます。


「Raw」をクリックし、開いたページで、「command + Aキー」(またはcontrol + Aキー)で全選択をし、コピーしてください。

Colabのサイトを開き、「ノートブックを新規作成」をクリックしてください。
先ほどコピーしたものを、ここに貼り付けてください。
すると、このようになります。

後は、使いたいモデルにチェックを入れて、再生マークをクリックするだけです。少し待つと、URLが表示されるので、それをクリックするとStable Diffusionを始められます。
■ エラーが出たり、うまく行かなかった場合 ■
Googleドライブと連携するStable Diffusionで、エラーや不具合が生じたときの対処法を話しておきます。
■ ほとんどの場合は、これで解決

エラーが出たり、上手く動作しないことがよくあります。そのときは
・ランタイム → ランタイムを接続解除して削除
・ページを再読み込み
・ランタイム → すべてのセルを実行
をしてください。
ほとんどの場合、これで解決します。その他の対処法は、次に話していきます。
□ 調べる / 開発者のページを見る
エラーが出るときは、この欄に表示されます。まずは、このログをコピーしてGoogle検索したり、チャットAIに聞いてください。

また、開発者のGitHubのページに、解決策が書かれていることもあります。質問も可能です。調べた上で、分からなかったときに聞いてみてください。
□ No interface is running right now

ランタイムが接続されていません。先ほどの「ほとんどの場合は、これで解決」をやってください。
□ URLをクリックするのが早い
起動は、毎回10分くらい待つ必要があります。「Model loaded in …」が表示されたら完了です。URLをクリックしてStable Diffusionを開いてください。
「Model loaded in …」が表示される前にURLは表示されますが、すぐにクリックしても読み込みに時間がかかったり、エラーが出ます。「Model loaded in …」が表示されるまで待ってください。
□ 待ち時間

読み込み中だと、このようなアイコンが表示されます。
特に、モデルの読み込みは時間がかかります。モデルの切り替えは、2回目からは数十秒で済みますが、初回は数分かかるので、気長に待ってください。
読み込み中は、Stable Diffusionの他の操作はしないでください。
□ DeepL翻訳を解除
DeepL翻訳が起動すると、なぜか不具合が生じたので、「元の言語を表示する」をクリックして翻訳されないようにしてください。もし不具合が生じた場合は、Stable Diffusion画面を一旦閉じて、URLをクリックしてもう1度開いてください。
□ TimeoutError: timed out
起動中に、長い間放置していると、このエラーが出てしまうことがあります。「ランタイム → ランタイムの接続解除 → すべてのセルを実行」をしてください。

よく「まだ操作中ですか?」と確認画面が表示されるので、その時は放置せずに「私はロボットではありません」にチェックしてください。
□ Google Driveと連携したColabで特定のモデルが読み込まれない / エラーが出る
modules.devices.NansException: A tensor with all NaNs was produced in VAE. Use –disable-nan-check commandline argument to disable this check.
このようなエラーが出ることがありますが、VAEを入れると解決できる場合があります。
vae-ft-mse-840000-ema-pruned.safetensors このVAEをGoogle Driveの、「sd」→「stable-diffusion-webui」→「models」→「VAE」の中に保存してください。
□ The future belongs to a different loop than the one specified as the loop argument
これも原因は分かりませんが、以下の方法で解決できます。
ランタイム → ランタイムを接続解除して削除
ページを再読み込み
ランタイム → すべてのセルを実行
□ 画像生成の画面が、途中で消える
画像生成の過程が、Stable Diffusion画面から消えることがあります。完了したら、再度Stable Diffusion画面に表示されますが、動作していることを確認するには、ログの欄を確認してください。
「Weights loaded in …」となると、画像生成は完了しています。
□ 自動保存できませんでした。このファイルがリモートまたは別のタブで更新されました。 差分を表示
これも原因は分かりませんが、以下の方法で解決できます。
ランタイム → ランタイムを接続解除して削除
ページを再読み込み
ランタイム → すべてのセルを実行
□ ERROR: Exception in ASGI application
これも原因は分かりませんが、以下の方法で解決できます。
ランタイム → ランタイムを接続解除して削除
ページを再読み込み
ランタイム → すべてのセルを実行
□ ERROR: ld.so: object ‘libtcmalloc.so’ from LD_PRELOAD cannot be preloaded (cannot open shared object file): ignored.
このエラーは、Colabを最初から入れ直したら消えました。おそらく、開発者が新しいバージョンを出したことで、エラーが直ったと思われます。最初からやり直す方法は、次で説明します。
□ 最初からやり直す
ランタイム → ランタイムを接続解除して削除
ページを再読み込み
ランタイム → すべてのセルを実行
ほとんどの場合、上記の方法で直りますが、それでも直らないときは、最初からやり直すのが手っ取り早いです。
Colabを利用したStable Diffusionを使う場合、設定を簡単にリセットできるのがメリットです。

やり直す際は、Googleドライブに追加された
・Colab Notebooks
・sd
というフォルダを削除します。ゴミ箱からも削除してください。
モデルや画像などを取っておきたい場合は、自分のPCに保存してください。
あとは、1番初めに始めたときと同じやり方で、始めてください。
■ Stable Diffusion画面の見方・使い方 ■
ここからは、主要な機能を、まとめて解説していきます。(参考:公式サイト)
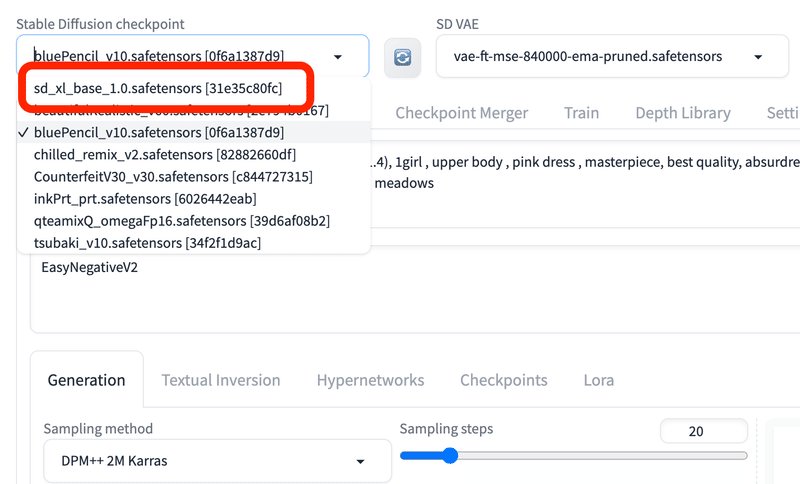
■ Stable Diffusion checkpoint(モデル)
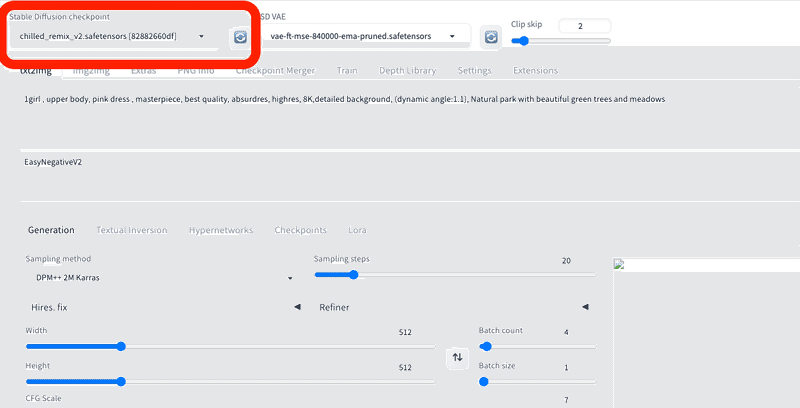
ここは、ダウンロードしたチェックポイントを切り替えるところです。チェックポイントは、モデルとも呼ばれています。
新しいモデルを追加したときは、チェックポイント欄の右にある、読み込みアイコンをクリックすると、モデルが読み込まれます。
それでも追加したモデルが表示されない場合は、Colabを再起動させてください。
■ VAE
モデルと同じように、「SD VAE」の欄で、VAEを切り替えることができます。
VAE欄が表示されていない場合、以下の手順で設定してください。
「Settings」→「User Interface」の「[info] Quicksettings list」で「sd_vae」と入力するか選択してください。
設定を変更したら、最後に「Apply settings」をクリックし、「Reload UI」をクリックしてください。
これで「VAEタブ」が表示されたはずです。
■ txt2img
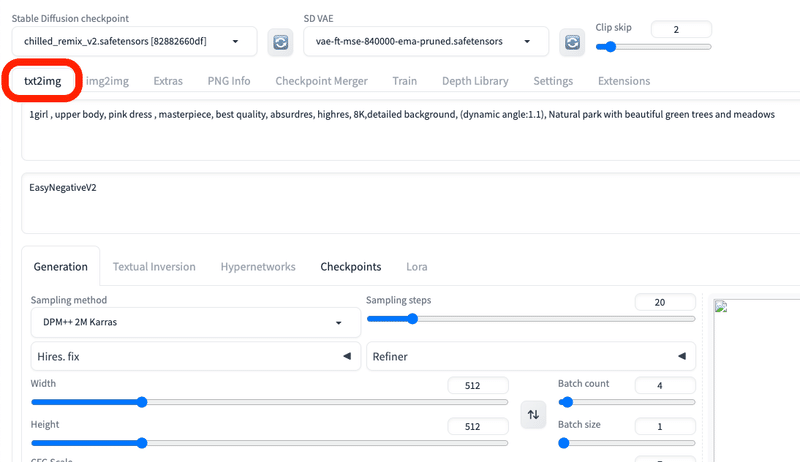
txt2imgは、テキストから画像を生成するために使う場所です。
■ プロンプト

ここに、生成したい画像の特徴を入力します。入力する文字は「プロンプト」や「呪文」と呼ばれています。プロンプトは、英語で入力し、単語や文章は、半角カンマで区切って入力します。

次に、右側にある「Generate」ボタンをクリックすると、画像が生成されます。このとき、GPUの性能が良いほど、待ち時間が短くなります。
プロンプトは少し工夫をしないと、高品質な画像は生成されません。クオリティの上げ方については、今後、紹介していきます。
再度「Generate」ボタンをクリックすると、プロンプトは同じままでも、別の画像が生成されます。
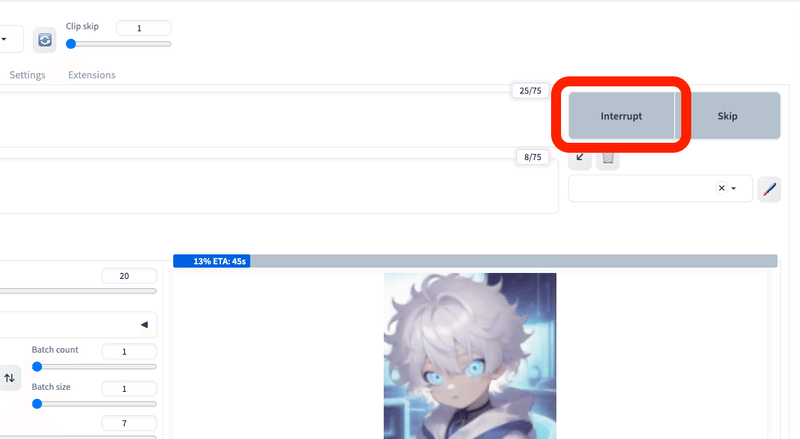
生成中に「Interrupt」をクリックすると、処理を中断できて、途中結果のまま出力されます。
□ ネガティブ プロンプト
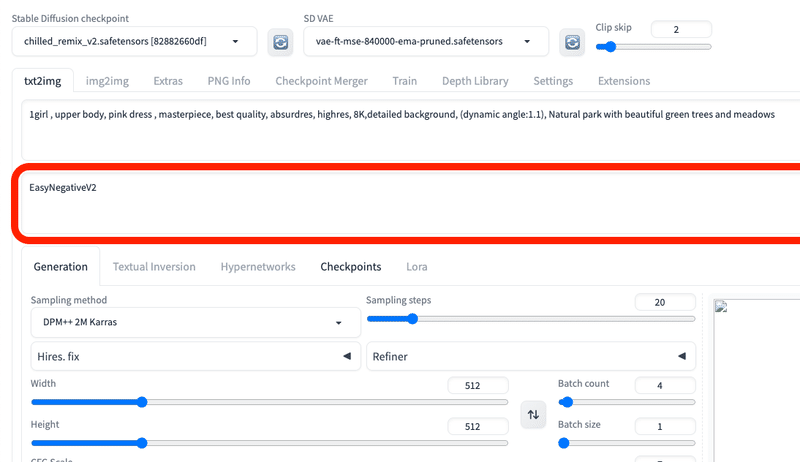
ネガティブプロンプトは、普通のプロンプトとは逆に、生成されたくない特徴を入力します。例えば「low quality」や「bad hands」などです。

クオリティを上げたいときは、普通のプロンプトを工夫するよりも、ネガティブプロンプトを入れた方が簡単に上がることがあります。
■ 画像の保存方法

「sd」→「stable-diffusion-webui」→「outputs」の中に、生成した画像が自動で保存されていきます。
生成した画像を右クリックして、1枚ずつ手動で保存することもできます。
画像は容量がやや大きいので、定期的に削除したり移動して整理するか、容量を追加で購入してください。
■ Sampling method(Sampler)

ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
Sampling methodとは、画像生成のときに、ノイズを除去するアルゴリズムのことです。Sampler(サンプラー)とも呼ばれています。
画像生成AIは、ノイズが多い画像からノイズを徐々に取り除いていくことで、綺麗な絵が作られるという仕組みなので、そのときに使われる計算方法がSampling method(Sampler)です。
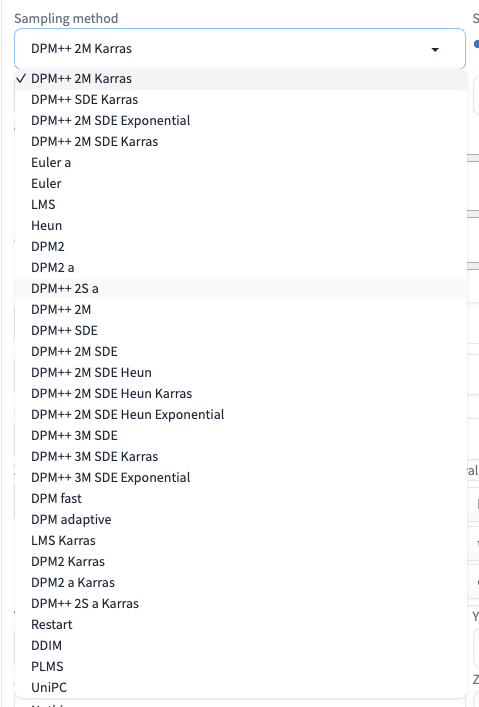
サンプリング方法には、ノイズ除去のアルゴリズムの一覧が表示されています。同じプロンプトであっても、サンプリング方法を変えることで、絵柄や生成時間に違いが現れます。
たくさんあって迷うと思います。基本的に、初期設定のままで大丈夫です。細かい調整を行うとき以外は、私は初期設定のままで使っています。
また、選び方の1つとして、モデルごとの推奨されているサンプリング方法を使うのがおすすめです。
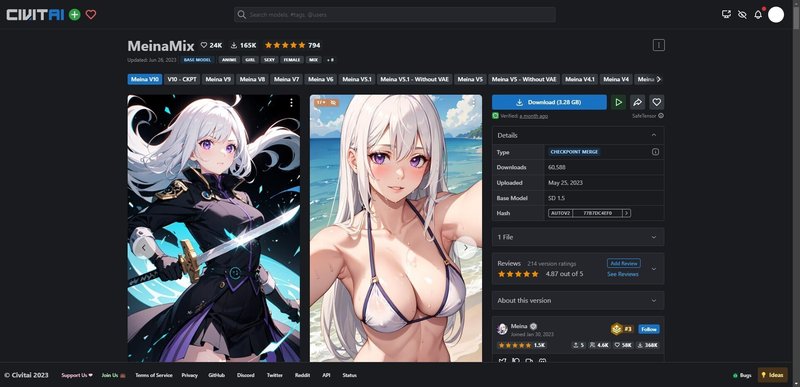

これはCivitaiにある「MeinaMix」というモデルです。
説明欄に
・Euler a
・DPM++ SDE Karras
・DPM++ 2M Karras
推奨と書かれています。

説明欄に推奨が書かれていなくても、プロンプトが記載されている画像があるので、それを参考にしてください。この画像のモデルは「Beautiful Realistic Asians」です。
基本的に、
・初期設定のまま
・モデルが推奨しているもの
を使っておけば大丈夫です。あとは、自分で試してみてください。
■ Sampling steps(ステップ数)
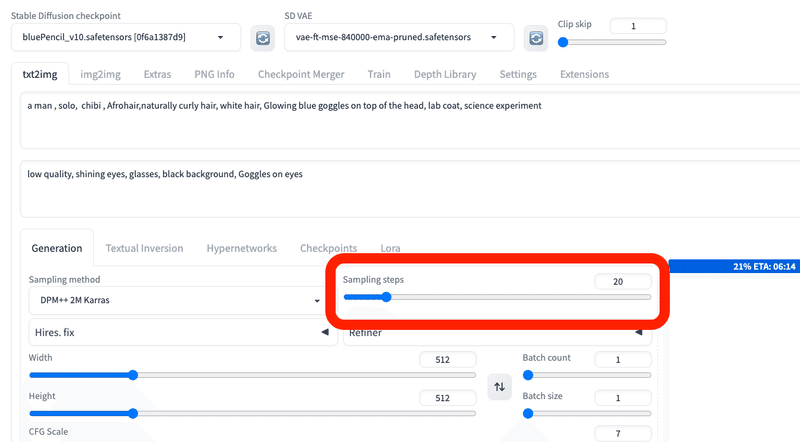
Sampling stepsは、生成する画像を何回くりかえし改善するか設定するところです。ステップ数とよく呼ばれています。

ステップ数が多いほど、クオリティがアップしますが、すぐに横ばいになります。また、ステップ数が多いほど、生成に時間がかかります。
逆に、ステップ数が少ないと、画像のクオリティが悪くなります。
基本的に、初期設定のままで大丈夫です。
モデルのサイトの説明欄に、ステップ数に関して記載されていることがあるので、それも参考にしてください。
ステップ数は、ほとんどの場合「20前後 ~ 60」くらいで大丈夫です。
これはCivitaiにある「MeinaMix」というモデルです。
・Euler a:ステップ数 40 ~ 60
・DPM++ SDE Karras:ステップ数 30 ~ 60
・DPM++ 2M Karras:ステップ数 20 ~ 60
推奨と書かれています。

説明欄に推奨が書かれていなくても、プロンプトが記載されている画像があるので、それを参考にしてください。この画像のモデルは「Beautiful Realistic Asians」です。
■ パラメータを初期設定に戻す方法
色々と設定を変えた後で、初期設定(デフォルト)に戻したい場合は、Webページを再読み込みしてください。
■ Hires.fix(ハイレゾ フィックス)



Hires.fixは、高品質かつ大きめの画像を生成するための機能です。はじめは小さいサイズで画像を作成し、それを拡大しつつ、構図を変えないまま細部まで綺麗するという仕組みです。High resolutionの略で、ハイレゾフィックスと呼ばれています。
Width / Heightで、はじめから大きな画像サイズに設定することもできます。ただし、バージョンがSD1.5のStable Diffusionでは、512*512の画像サイズでAI学習されたものが多いので、512*512サイズから離れるほど、絵の破綻が多くなります。そのため、Hires.fixで画像を拡大するのがおすすめです。
Hires.fixのデメリットとしては、画像を拡大するときに、絵の構図が変わってしまうことがあります。絵をほとんど変えずに拡大するには、ControlNetを使う必要があります。ControlNetの動画講義は、こちらを見てください。
Hires.fixは、右上の▼マークをクリックし、開くだけで有効になります。オフにしたいときは▼マークをクリックして閉じてください。
□ Upscaler(アップスケーラー)
Upscalerは、画像の拡大のときに使われるアルゴリズムの種類です。Sampling method(Sampler)と似たようなものだと思ってください。
これについても種類がたくさんありますが、基本的に初期設定のままで大丈夫です。あるいは、使っているモデルの説明欄を確認してください。
□ Hires steps(ハイレゾ ステップ数)
Hires steps(ハイレゾ ステップ数)は、Hires.fixで画像を拡大する際に機能するステップ数です。
先ほど説明した「Sampling steps(ステップ数)」と似たようなものだと考えてください。拡大された画像を何回くりかえし改善するか設定するところです。
値を大きくするほど生成に時間がかかるので、必要最低限で設定するのが良いです。普通のステップ数(Sampling steps)と同様に、ステップ数を多くすればクオリティはアップしますが、ある程度からは横ばいになります。
Hires stepsを0に設定すると、ステップ数で設定している値(初期設定だと20)が使われます。20は少し多いので、Hires.fixを使うときは、Hires stepsを自分で10~15くらいに設定すると、高品質のまま生成時間を短縮できます。
□ Denoising strength

Denoising strengthとは、Hires.fixにおいての画像拡大時に、ノイズの量を調整する機能です。後で解説するimg2imgやInPaintを使うときにも使用します。
Denoising strengthの値が小さいと、元画像に近い画像が生成されますが、ぼやけることがあります。反対に値が大きいと、高品質になりますが、元画像とは違った画像が生成されます。
Denoising strengthは、特にimg2imgのときに重要です。これも初期設定のままで大丈夫ですが、色々試してみてください。
□ Upscale by
「Upscale by」は、Hires.fixにおいての拡大率です。2なら 512*512 サイズが2倍になり、1024*1024 サイズになります。
画像サイズが1500*1500以上になると、GPUの関係でエラーが出やすいです。上げすぎないように注意してください。1500サイズよりも大きくする方法は、img2imgや、別の動画講義で解説します。
Upscale byの右にある「Resize width to」と「Resize height to」で、画像の幅と高さを細かく調整することができます。画像の縦横比を1:1以外にしたい場合は、ここを調整してください。基本的にUpscale byの方がオススメです。
画像の比率を変えたい場合は、後ほどimg2imgの方が便利なので、そちらで設定するのをオススメします。
■ WidthとHeight


WidthとHeightは、生成する画像の横幅と高さを設定するところです。右の矢印マークで、画像サイズを入れ替えることができます。
値を大きくするほど、GPUの消費と生成にかかる時間が増えます。こちらも、1500*1500サイズ以上になるとエラーが出やすいので、上げすぎないようにしてください。


また、値を大きくするほど、破綻した画像が出やすくなるので、Hires.fix(ハイレゾフィックス)の方で画像を拡大するのがおすすめです。
画像の拡大方法は、他にもやり方があります。別の動画講義でまとめて解説します。
■ Batch countとBatch size(バッチ回数とバッチサイズ)

Batch count:画像生成を繰り返す回数
Batch size:同時に画像生成をする枚数
例えば、Batch countを2にする場合、1枚目の画像生成をして、終わったら2枚目の画像生成をします。一方で、Batch sizeを2にする場合、2枚の画像生成を1回で同時に行います。
Batch sizeの方がVRAMの使用量が多くなるので、基本的にBatch countを使ってください。
■ CFG Scale


CFG Scaleは、「生成する画像が、プロンプトにどれくらい忠実か」設定するところです。値が大きいほど、プロンプトに忠実になります。値が小さいほど、より創造的になりプロンプトから離れます。
AIの自由度を上げたいときはCFG Scaleを低めに、プロンプトに忠実にしてほしいときはCFG Scaleを高めに設定してください。ただし、上げすぎても下げすぎても破綻するので、7前後が目安です。

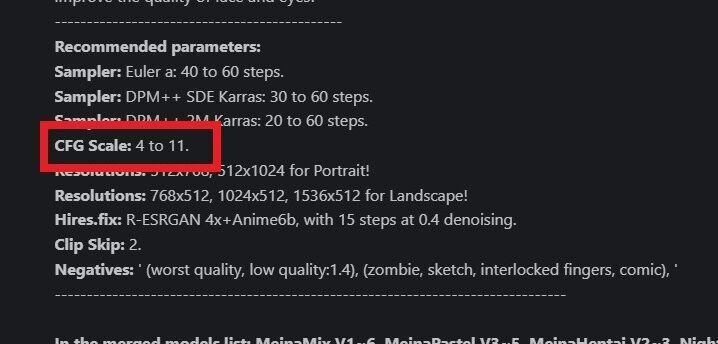
これはCivitaiのイラスト調のモデル「MeinaMix」です。CFG Scaleは、「4~11」が推奨されています。このように、モデルの説明欄に書かれていることもあります。
CFG Scaleは、絵の内容を変えたいときに、調整してください。
■ Seed
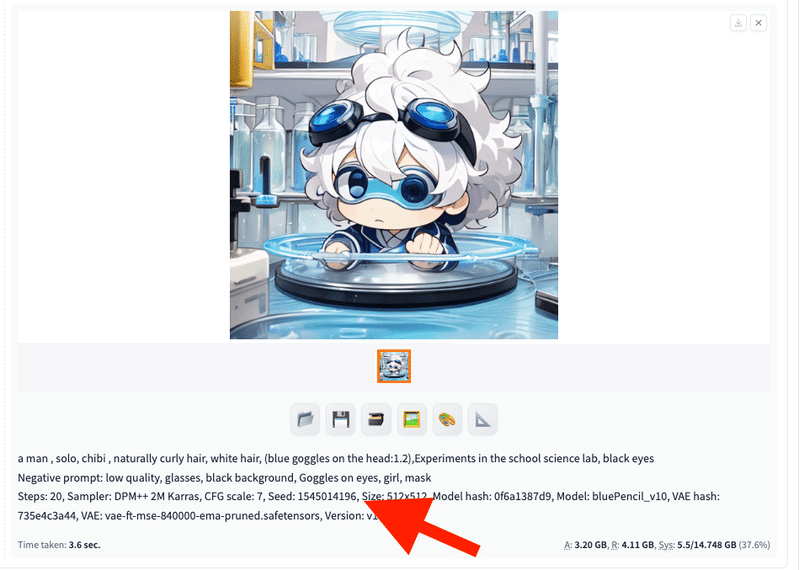
Seedとは、画像生成の計算に使われるランダムな値のことです。画像生成のときに使われたSeedは、ここに表示されます。



同じプロンプトやパラメータ、Seedで画像を生成すると、同じ画像を作ることができます。似たような画像を生成したいときに使う機能です。
これはSeedを最初に1に設定して、画像を生成した例です。

基本的には、生成されたSeedを、右側のリサイクルアイコンをクリックすることで、再利用できます。気に入った画像が生成できて、次も同じような画像を出したときに、出力されたSeedを使ってください。
初期設定ではSeedは「-1」になっています。「-1」はランダムという意味で、「-1」だけは同じ数字でも別の画像が生成されます。サイコロをクリックすると、簡単に「-1」に設定可能です。

これは、元のプロンプトに、「smile , open mouth」と加えたものです。元の画像の特徴を保ちつつ、少し変化を加えることができます。
元の画像を保ち、少し変化を加える方法は、img2imgやControlNetなど色々あります。ControlNetの動画講義でまとめて解説します。
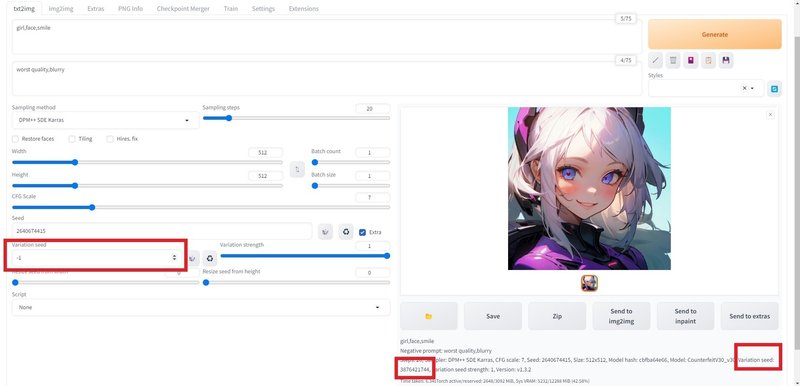
□ Extra(Variation seed / Variation strength)
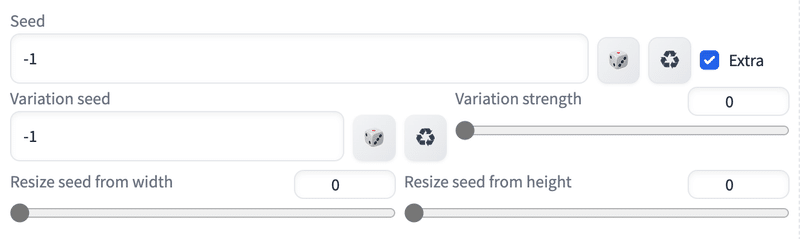


Seedを固定した上で、さらに微調整したい場合は、「Extra」にチェックを入れて編集することができます。この機能を使うことはほとんどありません。
Variation strengthの値を変えて生成した画像をもとに、さらに微調整したい場合は、「Variation seed」にVariation seedを入力して生成を続けてください。
■ Script
□ X/Y/Z plot
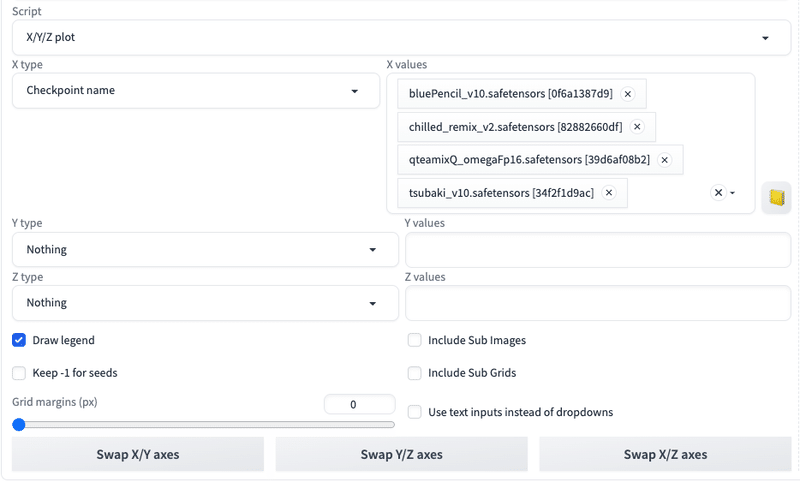

Scriptに関しては、よく使う「X/Y/Z plot」を解説します。
X/Y/Z plotは、パラメータを変えて複数の画像を同時に生成できる機能です。Stable Diffusionで、比較したい機能がある場合に便利で、頻繁に使います。


Y type:CFG Scale
Xは横方向に、Yは縦方向に表示されます。「type」には比較できる項目が表示されるので、比較したい項目を1つ選択します。「values」にはtypeのパラメータをカンマで区切って入力します。
typeがチェックポイント(モデル)のような場合は、valuesには数値ではなく、名前を入力します。右のアイコンをクリックすると、インストール済みのモデルを一覧で入力してくれるので便利です。
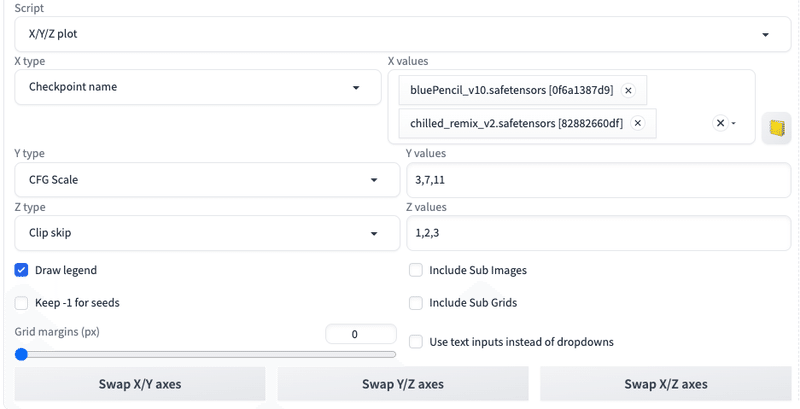

Y type:CFG Scale
Z type:Clip skip

次に、下の方にある設定の説明をしていきます。
Draw legendは、表の凡例です。画像の上や横に書かれている項目のことです。
「Keep -1 for seeds」はSeedをランダムにして、画像の表を作るという意味です。X/Y/Z plotは、比較したい条件以外は固定して画像の表を作る機能です。もちろんSeedも固定されていますが、「Keep -1 for seeds」をONにすると、ランダムなSeedで画像の表が作られます。基本的に、オフで使ってください。
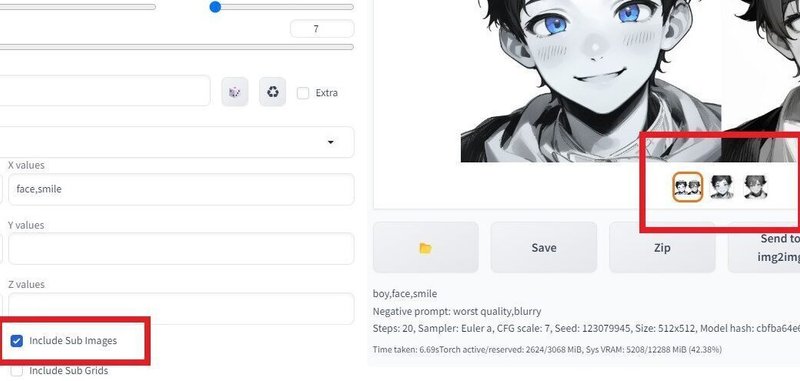
「Include Sub Images」をオンにすると、表になっていない個別の画像も生成されます。編集画面に持っていきやすいです。ちなみに、オフにしていても、画像の保存自体は自動で行われています。グリッド画像、個別の画像ともに、自動で保存されます。
「Include Sub Grids」は、XYZ軸の3軸で生成したときに、X軸とY軸だけの表も生成してくれる機能です。こちらも、オフにオンしていても、画像の保存自体は自動で行われています。

「Grid margins (px)」は、画像と画像の間の余白のことです。
「Swap X/Y axes」などは、軸の入れ替えです。

次に、typeの中にある「Prompt S/R」を解説します。S/Rは「Seach/Replace」の略です。プロンプトの特定のキーワードを、別のキーワードに置き換える機能です。
例えば、プロンプト「girl, face, smile, pastel」において、ガールとボーイの2種類の比較画像を生成したいとします。そのためには、typeにPrompt S/Rを選択し、valuesに「girl,boy」と入力します。これは元のプロンプトで1枚目の画像を生成し、さらにプロンプトの中のgirlをboyに置き換えて2枚目の画像を生成するという意味です。
これを普通のプロンプトで行う場合は、次のように2回に分けて生成する必要があります。
・girl, face, smile, pastel
・boy, face, smile, pastel

3枚以上を生成したい場合も同じやり方です。valuesに入れる単語を増やします。
2単語以上をセットで置換したいときは、valuesに「girl,"kawaii,girl",boy」のように引用符を使って書きます。このとき、エラー防止のため、単語の間にスペースを空けないようにしてください。
これを普通のプロンプトで行う場合は、次のように3回に分けて生成する必要があります。
・girl, face, smile, pastel
・kawaii, girl, face, smile,pastel
・boy, face, smile, pastel
次に移ります。

Prompt orderは、プロンプトの順番を並べ替えて表示する機能です。
例えば、プロンプト「girl, face, smile」の順番を変えて比較したい場合、valuesに「girl, face, smile」を入力すると、6パターン生成されます。

プロンプト「girl, face, smile」の中の「face, smile」の順番だけを変えて比較したい場合は、valuesに「face, smile」と入力します。
これは
・girl, face, smile
・girl, smile, face
というプロンプトを意味しています。
お疲れ様でした。X/Y/Z plotについては、一旦おわりです。少し難しかったかもしれませんが、これを使えば作業の効率化ができます。ぜひ、使ってみてください。
X/Y/Z plotについては、特にtypeの種類がとても多く、私自身すべては把握していません。良さそうな機能があれば追記します。
■ Generateボタン周辺の説明

この矢印ボタンは、最後に使ったパラメータを読み込むことができる機能です。「昨日の夜に設定した内容を、今日もそのまま使いたい」という時に便利です。クリックするだけで、自動で最後に設定したプロンプトやパラメータが割り振られます。
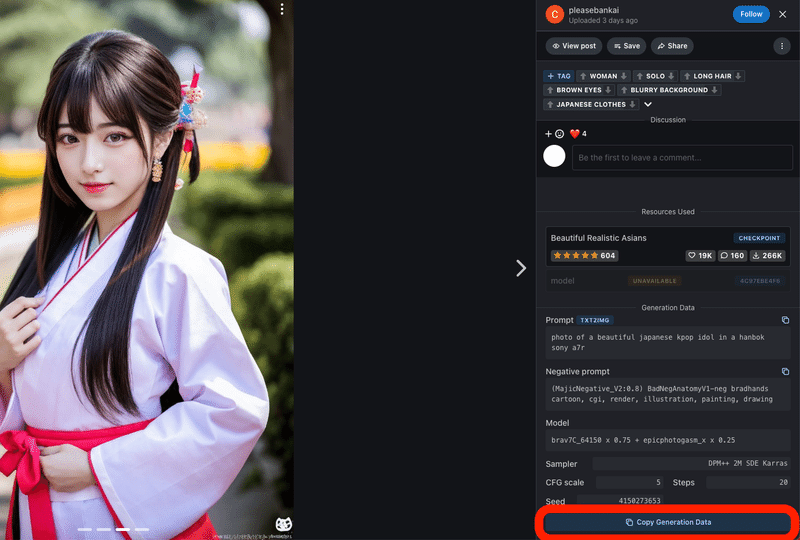
また、プロンプトやパラメータなどの生成データをコピーできるサイトがある場合にも使えます。そこで生成データをコピーした後に、
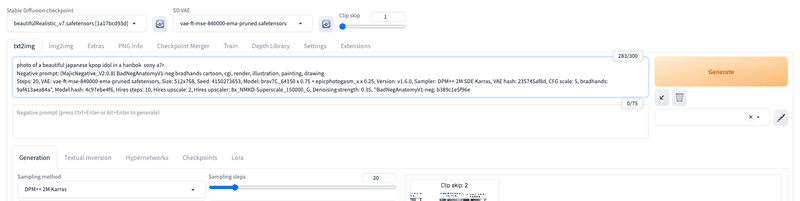
プロンプト欄に貼り付けて、矢印をクリックします。

すると、プロンプトやパラメータを自動で割り振ってくれます。
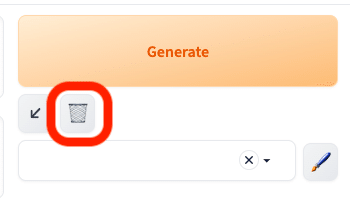
ゴミ箱マークのアイコンは、プロンプトを消去できる機能です。パラメータは消去されません。
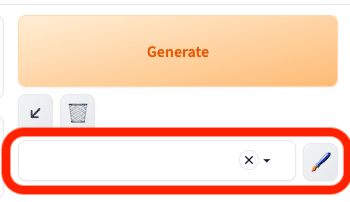
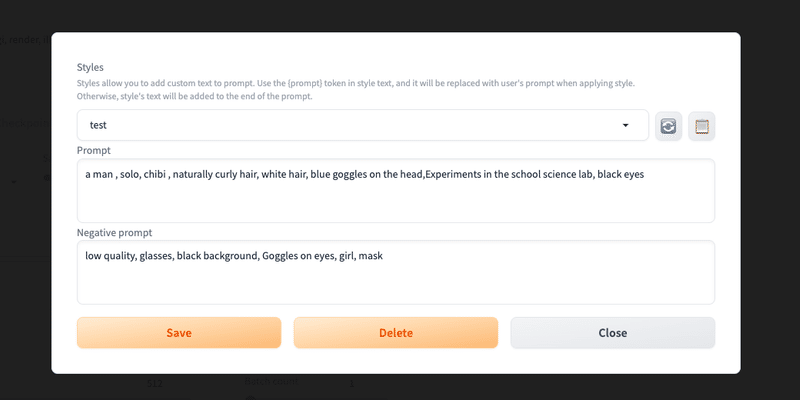
ペンのアイコンは、プロンプトを保存できる機能です。ペンのアイコンをクリックすると、このような画面になります。ここでプロンプトを入力し、保存できます。

保存した後、画像のように設定し、ペンのアイコンをクリックしこの画面を開き、右上のメモ帳アイコンをクリックすると、プロンプトがStable Diffusionの画面に割り振られます。
保存したテンプレートが表示されないときは、右上の再利用アイコンをクリックすると表示されます。
■ Clip skip (参考サイト1・参考サイト2)


ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
プロンプト:男性, ソロ, チビ, 自然な巻き毛, 白髪, 頭に青いゴーグル, 学校の理科室での実験, 黒い目
Clip skipは、「プロンプトをどれくらい正確に反映させるか」設定するところです。絵のバリエーションを増やしたいときに、よく使います。
Clip skipは、1〜12で設定できます。この設定欄の表示方法は、後ほど説明します。
Clip skipの値が小さいほど、プロンプトに近い画像が生成されます。
Clip skipの値が大きいほど、プロンプトから離れた画像が生成されます。
1にしておけば良いと思うかもしれませんが、2の方がプロンプトに正確になるモデルも多いです。おそらく、AIが余計な描き込みを追加するので、最終結果よりも少し手前で止めておくと、良い結果が得られるんだと思います。そのため、「推奨設定:2」というモデルは多いです。ほとんどの場合、1か2で上手くいきます。多くても3までかなと感じます。
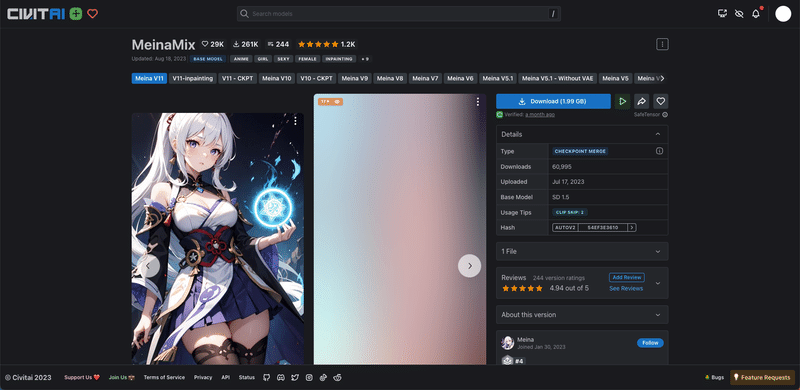

これは、MeinaMixというモデルです。このように、モデルの説明欄に、推奨設定が記載されていることがあります。
似た機能にCFGスケールがあります。「生成する画像が、プロンプトにどれくらい忠実か」設定するところです。値が大きいほど、プロンプトに忠実です。値が小さいほど、プロンプトから離れて、より創造的になります。
違いとしては、次のような感じです。
・Clip skip:画像生成を途中で完了させることで、目的に近い画像を生成
・CFG scale:プロンプトにより強く従わせて、目的に近い画像を生成

Clip skipの設定欄が表示されていない場合は、Settings → User interface を開いてください。

「[info] Quicksettings list」で、clipと少し入力すると、「CLIP_stop_at_last_layers」が出てくるのでクリックしてください。これがClip skipです。

設定を変更したら、最後に忘れずに「Apply settings」→「Reload UI」をクリックしてください。これをしないと、設定が反映されません。
■ PNG Info

PNG Infoは、画像をアップロードするだけで、その画像の生成に使われたプロンプトやパラメータなどの生成データを表示してくれる機能です。
生成した画像には、プロンプトやパラメータなどの生成データも一緒に保存されているので、それを表示しています。
ただし、他のソフトで画像を加工したり、生成データを削除した画像の場合は、PNG Infoに読み込ませてもデータは表示されません。例えば、画像をPNGからJPGに変更すると、生成データは消えてしまいます。
「Send to txt2img」などのボタンをクリックすると、プロンプトやパラメータなどの情報を一括で送ってくれます。
■ img2img
img2imgは、画像から画像を生成する機能です。

ここに、画像をドロップして使います。



プロンプトは書かなくても画像を生成することができますが、プロンプトなしだとクオリティがとても低いです。そのため、元画像に関係あるプロンプトを入れて生成してください。
元画像と同じプロンプトとSeedを使うと、似た画像を生成することができますが、元画像とは違う絵になります。元画像とほぼ同じ画像を生成にするには、ControlNetを使う必要があります。ControlNetについては、別の動画講義で解説します。


Denoising strengthの値を上げるほど、元画像から離れます。
■ Resize mode



Denoising strength:0
Seed固定

Denoising strength:0
Seed固定

Denoising strength:0
Seed固定

Denoising strength:0
Seed固定
「Resize mode」は、元画像を別の画像サイズに変更するときに選択するモードで、3つあります。
Just resize – 元画像の縦横比を無視して、そのまま画像サイズを変更するので、歪むことがあります。
Crop and resize – 元画像の縦横比を保ったまま、画像サイズを変更します。このとき、はみ出した部分はカットされます。
Resize and fill – 元画像の縦横比を保ったまま、画像サイズを変更します。このとき、足りない部分はAIが補完してくれます。
Just resize (latent upscale)- Just resizeと同じですが、Upscalerだけ違います。(Upscalerは、画像生成のときに使われる計算の種類のことです。)
上の画像では、Denoising strengthの値は0です。Denoising strengthはノイズの量を調整する機能です。値が小さいと元画像に近い画像が生成されますが、ぼやけることがあります。値が大きいと高品質になりますが、元画像とは違った画像が生成されることがあります。
基本的に、Resize modeは初期設定のままで大丈夫です。画像サイズを変えるときは、同じ画像比率で変えるようにしてください。そうすれば、Resize modeを気にする必要はありません。
もし比率を変えてResize modeを使うときは、以下の生成結果を参考にしてください。

Denoising strength:0.75
Seed固定

Denoising strength:0.75
Seed固定

Denoising strength:0.75
Seed固定

Denoising strength:0.75
Seed固定
Denoising strengthを上げれば、画像サイズを変更してできた隙間に、プロンプトに応じて描き込みをしてくれます。
ただし、Denoising strengthが低いと、先ほどのように、おかしな絵になったりします。そのため、Resize modeを使うときは、基本的に同じ画像比率を設定するようにしてください。
■ Inpaint

「Inpaint」は、画像の一部をマスクして、その部分を編集する機能です。マスクとは「おおい隠す」という意味です。
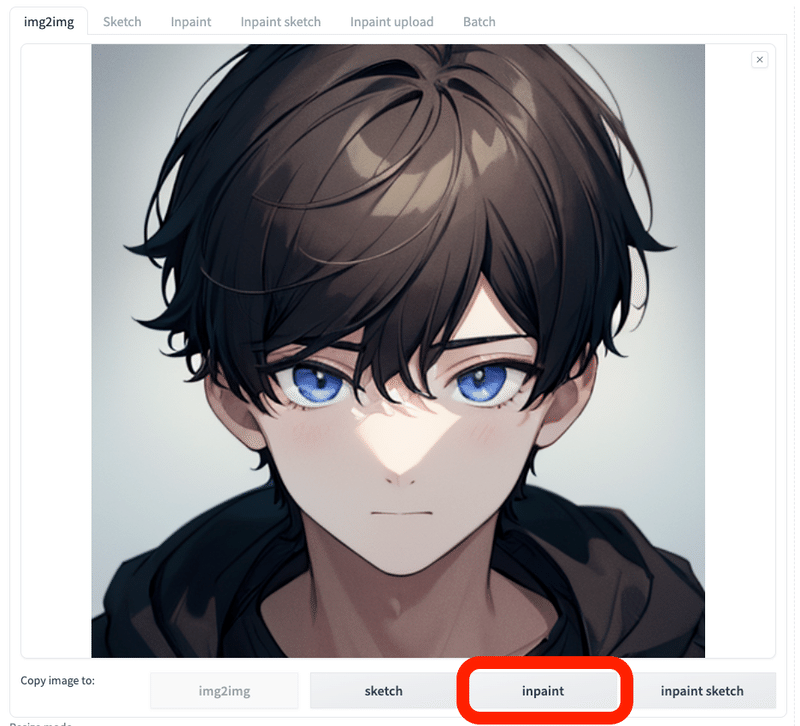
下にあるInpaintをクリックすると、img2imgの画像をそのままInpaintに送ることができて便利です。


ネガティブ「monochrome」を追加
Seed固定
このように、表情を変えるなど、一部だけを変えたいときに、Inpaintは便利です。Inpaintは、ControlNetと組み合わせることで、さらに効果を発揮します。

1番左の「戻るアイコン」は、マスクした部分を1回ずつ戻すことができます。
左から2番目の「消しゴムアイコン」は、マスクした部分をまとめて消去できます。
左から3番めの「✕アイコン」は、画像を閉じることができます。
その下の「筆アイコン」は、マスクのサイズを変更できます。
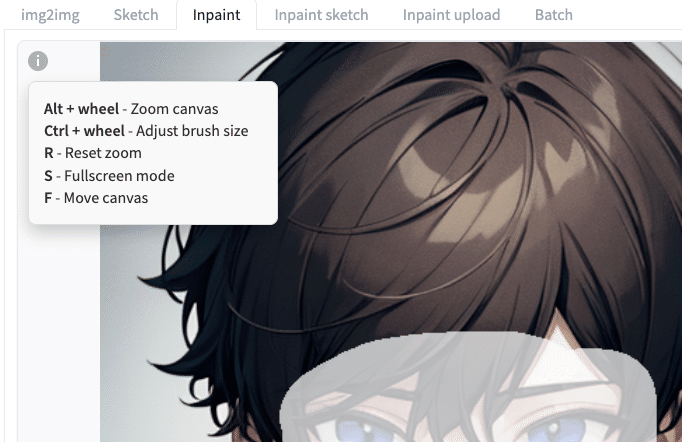
キャンバスにカーソルがある状態で、左上の操作をすると、キャンバスを拡大したりすることができます。
■ おわり
一旦おわりにします。お疲れ様でした。これで、Stable Diffusionの基本習得は完了です。
他にも細かい機能はありますが、使用頻度が少なかったり、上級者向けだったりするので、別の動画講義で解説することにします。
■ つづき ■
↓ 上の記事のつづきです
■ 拡張機能Taggerを使い、プロンプトを考えてもらう
□ インストール方法

Taggerとは、画像からプロンプトを推測してくれる拡張機能です。詳しい使い方は分からないので、簡潔に説明します。

似た機能に、img2imgの
・Interrogate CLIP
・Interrogate DeepBooru
があります。しかし、どちらもクオリティが微妙なことがあるので、よくTaggerが使われています。
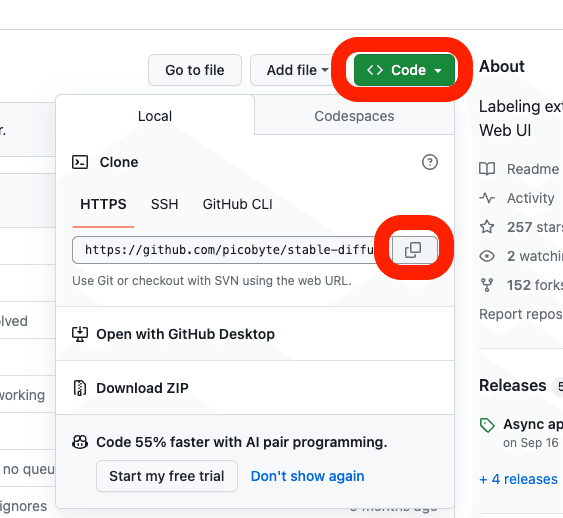
URLをコピーし、

貼り付け、
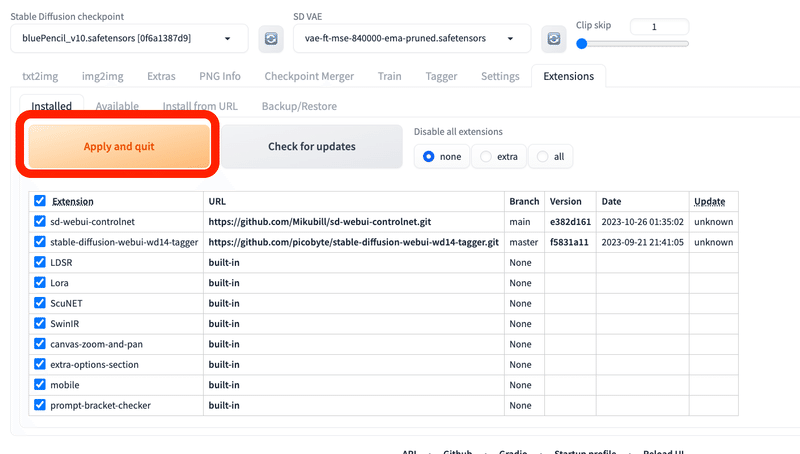
Apply and quitをクリックし、 Stable Diffusionを再起動してください。
□ 使い方
使い方は、
1.画像をドロップ
2.Interrogate imageをクリック
だけです。画像の右上に、プロンプトが表示されます。
あとは、推測されたプロンプトを自分で調整し、
・不要なものは削除
・足りない分は追加
するだけです。
・品質系のプロンプト:best qualityなど
・ネガティブプロンプト
は表示してくれないので、自分で追加する必要があります。





クオリティは、こんな感じです。だいたいの雰囲気は、元画像に合っています。完璧に再現はできませんが、ある程度似てる絵を高品質で作ることができます。プロンプトを考える手間も省けるのも、良い点です。
この記事が気に入ったらサポートをしてみませんか?