
データを伝える技術 第6回 データを見せる 後編

執筆:荻原 和樹
「シンプルなデザイン」の罠
データ可視化を作る際にはシンプルなデザインがよい、とする方は少なくありません。私自身も部屋のインテリアやファッションはシンプルが好みなので気持ちはよくわかりますが、データ可視化において「シンプルなデザイン」はかなり難易度が高いのが現実です。
シンプルなデザインを採用する最大のリスクは、シンプルを通り越して「手抜き」「殺風景」という印象を与えてしまうことです。そもそもデータは無味乾燥なイメージを持たれやすく、何も考えずシンプルに可視化を作るとその無機質さが際立ちます。大抵の人にとって、データを読む行為は退屈なものです。可視化すればわかりやすいといっても、派手な広告や華美な映像に慣れた私たちの目には、単純なグラフの集まりはシンプルを通り越して退屈に映ります。
グラフの装飾と記憶の関係について調査した興味深い研究があります。2010年、ニューブランズウィック大学の研究者らは図表における装飾が内容の理解や記憶に与える影響について調査しました。以下のように、まったく同じデータをシンプルな図表で表現した形(論文ではミニマリスト・アプローチと呼ばれています)と視覚的な装飾を施した形でそれぞれ提示し、理解の正確さや中期的な記憶(2〜3週間後)の関連について実験したものです。

実験の結果、シンプルなグラフと装飾を施したグラフの理解度は同程度であり、中期的には装飾を施した方が内容をよく記憶されていることが明らかになりました。もちろん、すべての図表をこのように装飾することはお勧めしません。ただ少なくとも、視覚的な装飾は決してユーザーを「楽しませる」だけでなく、内容を伝えるにあたってプラスの働きをする場合があることは注目すべき点です。
シンプルなデザインに関してもう一つ留意すべき点は、「単調さを感じさせないシンプル」はむしろ派手なデザインよりも手間がかかることです。
以前、あるグラフィックデザイナーの方と名刺を交換したのですが、その名刺は線も装飾も一切入れず、名前やメールアドレスなどの文字だけで構成されていました。とてもシンプルでわかりやすいデザインだと感じましたが、帰宅してよくよく眺めてみると、文字の配置や大きさのバランス、カーニング(文字と文字の間隔を調整する処理)などが至るところに施されており、手間をかけて「シンプルに見える」ようにデザインされていることがわかりました。これが本当に文字を入力しただけなら、きっとシンプルというより殺風景・手抜きの印象を与えたでしょう。
機械的に揃っている状態と、人が目で見て揃っていると感じる状態は異なります。たとえばプレゼンテーションなどで画面の中心に文字を表示したいとき、機械的に中心に配置すると、視覚的には「やや下」に見える場合があります。これは「上方距離過大錯視」と呼ばれ、視野の上にあるものが大きく見える錯視の一種です。

この場合は画像左側のように「やや上」に配置する方がバランスよく見えます。このような錯視も含め、人が見てバランスよいものにするためには、手作業で細かな部分をチューニングすることが不可欠です。
データ可視化にデザインは不要?
データ可視化のデザインを考えるときに必ず起こる議論が「そもそもデータ可視化にデザインは必要か」というものだと思います。「データ可視化においてはあらゆるデザインは不要で、データを可能な限りそのまま表現するのがよい」と主張する方もいます。私自身は、無駄な装飾を省くことについてはもちろん賛成ですが、最低限デザインに気を使わないとデータやメッセージが十全に伝わらない、と考えています。
私自身、このことを強く意識した経験があります。結論から書くと「デザインに力を入れたら技術力やアイデアを評価されるようになった」話です。
私は新卒で働き始めてから、主にデータベースの管理やメンテナンスなどの仕事をしており、デザインや記事執筆の経験はありませんでした。働き始めてから数年した後にデータ可視化やデータ報道と呼ばれる分野の存在を知り、興味を持って自分でも試作品をいくつか作ってみましたが、どう贔屓目に見てもよくできた代物ではなく、試しに見せてみた周囲の反応も芳しいものではありませんでした。
ある日、仕事でウェブサービスを作ることになり、私がデザイン原案を制作したのですが、それを見た上司と先輩の判断は「デザインは外注しよう」というものでした。つまり「顧客に出せるレベルではない」と判断されたのです。
これでは満足に「データを伝える」ことができないと感じ、デザインを学ぶためにイギリスのエディンバラ大学大学院に留学しました。デザイン&デジタルメディアという専攻で、日本でいうと美術大学における情報デザイン専攻のような位置付けです。周囲の学生は3Dアニメーション、ゲーム、VRなどを制作していました。学部からデザインを学んでいる学生、現役のグラフィックデザイナーとして仕事をしている学生などもおり、デザインの訓練を受けてこなかった私はかなり苦労した記憶があります。
さて、帰国してから作品を作る際にはデザインに気を配り、時間をかけて配色や要素の位置関係を吟味するようになりました。今までは既成のテンプレートやフレームワークをそのまま使っていたのが、自分で良し悪しを判断してチューニングできるようになりました。一方で、データ分析やデータサイエンスに関する授業は受講しなかったので、そちらは大きく進歩していないはずです。それにもかかわらず、帰国して以降は「デザインがすごい」と言われるよりも、データの分析力やアイデアを評価してもらうことが多くなりました。
これだけ書くと不思議な現象ですが、私は「デザインに力を入れることで、内容に注目してもらえるようになったから」だと考えています。拙い文章の内容を理解するのが難しいように、デザインの品質が低いとデータの意味やメッセージを理解してもらうことができません。データ可視化に「アイデアが斬新」「技術力がすごい」といった感想が集まったとしても、それに最も寄与しているのはデザインや細部の使いやすさである可能性があります。
私はこれをよく映画や小説の「どんでん返し」にたとえています。終盤で劇的な展開がある作品は通常「どんでん返しがすごい」「ラスト10分の衝撃」などと形容されますが、そこに至るまでの過程がしっかりと描かれていないと、最後の展開が読めてしまったり、退屈で読むのをやめてしまうかもしれません。データ可視化において細部のデザインに力を入れることは、この「過程」をきちんと描写することです。「神は細部に宿る」と言われるように、細部=過程がしっかり描かれることによって、本当に体験してほしい内容が引き立つことになります。
付言すると、「デザインに力を入れること」は必ずしも「装飾をたくさん入れること」を意味しません。たとえばアップルの商品紹介ウェブサイトは白を基調としたシンプルな作りに見えますが、ソースコードを見ると、文字間や行間の余白が0.1ミリ単位で設定されていたりと、非常に細かな調整が行われていることがわかります。
私がデザインするときも、もちろん一定の配色理論やテンプレートなども活用しますが、最終的には目で見て微調整を行います。最も見やすくわかりやすい配色や余白のバランスは、データの分布によっても変わります。データ量が少ないときと多いときでは配色バランスが変わるため、実際のデータを流し込まないと配色は決まりません。以前の連載で書いた「電車に乗った状態でデータ可視化を試す」も、その一環です。
業務用のダッシュボードなど、制作するグラフやページが大量にある場合は効率化を優先するべきでしょうが、報道など極めて多くの人の目に触れるものや、重要なプレゼンテーションでデータを見せる場合は、時間をかけてデザインを吟味するのがおすすめです。
予想のデータをいかに可視化するか
データ可視化では、必ずしも確定した数字だけを扱うわけではありません。時には予想や推計値、あるいは数値が定まらず幅があるデータを可視化するケースもあるでしょう。
よくあるケースは来期の業績予想や人口の未来予測などです。これらをグラフに表現する際は、まず視覚的に確定データと区別できるようにすることが必要です。棒グラフなら確定値よりも薄い色にする、折れ線グラフなら実線ではなく点線で表現する、などの方法があります。
では、予想に幅がある場合はどうするか。たとえば選挙速報では、予想される議席数に幅が生じることがあります。以下は2021年の東京都議選におけるNHKの情勢報道です。出口調査のデータをもとに、以下のように棒グラフの先端を斜めにすることで予想の幅を表現しています。これによって、すぐ隣に表示している選挙前の議席数と最大・最少予測をともに比較することが可能になります。

(2022年3月25日アクセス)
同じデータを朝日新聞は少し違う方法で可視化しています。こちらは棒グラフの先端をグラデーションでぼかすことによって表現しています。NHKのように最大・最少の予想値を正確に表現することにはこだわらず、あくまでも「未確定であること」を強調した形であるといえます。

(2022年3月25日アクセス)
続いて、地図はどうでしょうか。未確定の地図情報といえば、最も身近なのが台風の進路です。天気予報ではよく以下のような進路予想図を見かけます。

これは2021年の9月に発生した台風16号の予想進路(9月27日時点)です。10月1日ごろに日本列島に再接近することがここでは予想されています。このような台風の進路予想図の表現は天気予報でもよく目にするものですが、実は誤解の多い表現でもあります。
よくあるのが「予報円(図の破線で囲まれた部分)の範囲が台風の大きさを示す」という誤解です。予報円や赤い線で囲まれた予想暴風域だけ見ると、時間が経つにつれて台風がどんどん大きくなっていくように見えるかもしれませんが、実際には予報円は「この時点で台風の中心が円の範囲内に入る確率が70%」である範囲を示すもので、必然的に未来の予想になるほど円は大きくなります。
tenki.jpが2021年に実施したアンケートでも、35%の人が予報円の見方を誤解していることがわかっています。アルバート・カイロ『グラフのウソを見破る技術』(ダイヤモンド社、2020年)でも、この進路予想図は「ほとんどの人がこの地図を読み間違えている」として、誤解の多い可視化表現であると紹介しています。
これを踏まえ、イギリスの「エコノミスト」紙では、以下のように色の濃淡をつけることで予想のグラデーションを表現しています。

これは2019年に発生したハリケーン「ドリアン」の予想進路を示したグラフィックです。色のついている範囲は、今後5日間において熱帯低気圧による強風が時速63キロメートル以上(気象庁の目安によると、風に向かって歩けなくなり、転倒する人も出る)になる可能性をグラデーションで表現しています。先ほどの台風の予報円では70%を区切りとして一律に扱っていましたが、このようにグラデーションで表現することにより「非常に高い確率で強風が襲う地域」から「確率は低いがゼロではない地域」までをカバーすることが可能になります。
不完全なデータを可視化する意義
以上、予想データを表現する方法について解説しました。いずれも視覚表現による工夫を施すことで、「未確定であること」を明示しつつ、可能な限り詳細な情報を提供しようとするものです。
世の中には予想の他にも確度が高くないデータがあります。以前の連載でも触れた速報値や、データ収集の限界によって網羅的なデータにならないケースです。こうした未確定のデータは可視化の方法を検討するのも手間がかかりますし、一歩間違えるとユーザーの誤解や炎上を招きかねません。そのため「確定しない数値は見せない」と判断されるケースもあるのですが、基本的には「可能な限り工夫して未確定の数字でも掲載するべき」と私は考えています。
というのも、データが可視化されないと「そのデータが不完全であること」にユーザーが気付けないからです。特にデータ報道では、「データはあるけど信憑性が低い」と国民が気付けば、政治や行政もその声に対応して状況が改善される可能性があります。しかし「怪しいデータは載せない」判断にすると、そもそも「怪しいデータが存在する」こと自体に気づいてもらえません。
新型コロナ禍ではさまざまなデータが可視化されました。現在進行形の事象ということもあり、中には定義が曖昧なものや、集計が追いつかずブレが激しいデータもあります。それでも報道機関や個人開発者などがいろいろなデータを可視化することによって、「このデータは本当に実態を反映しているのか」について議論が起こり、改善されるものもあるでしょう。
もちろんユーザーに誤解を与えないようにすることは大前提です。「何も考えずすべて見せる」でも「怪しいデータは一切見せない」でもなく、「データは見せるがそれが怪しいものであることを伝える」という方法を模索すべきだと考えています。
シミュレーションを可視化する
データ可視化の対象は実際のデータばかりとは限りません。新型コロナ禍においては、数理モデルの手法を用いて新型コロナの感染力の強さや今後の動向を推測する「感染症数理モデル」が注目されました。報道の分野でも、新型コロナの感染がどのように人から人へ伝わるのかといったシミュレーションをビジュアルで表現した作品があります。
まず挙げられるのが、ワシントン・ポストによる新型コロナの感染シミュレーションです。このシミュレーションは2020年の3月中旬という極めて早い時期に公開されました。まだアメリカにおいて1日あたりの新規感染者数が数百人にとどまっていた時期です(ちなみに2022年1月10日にはこの数字が1日あたり143万人に達しています)。

このコンテンツは6ヶ月前に入社したグラフィック・レポーターが1人で制作したものです。まだほとんどの人が聞き慣れていなかった「感染者が幾何級数的に増える」とはどういうことか、感染者の隔離が全体への感染スピードにどう影響するか、そしてソーシャル・ディスタンスをとって各自が移動を控えることによって感染がどのように抑えられるかといった、今では基本的な概念を丁寧に解説しています。
この記事は著名人にシェアされるなど瞬く間に話題となり、急遽日本語を含む13ヶ国語に翻訳されました。その結果、ワシントン・ポストのウェブサイトにおいて史上最も読まれた記事になりました。
ワクチンについても、2020年8月にロイターが優れたシミュレーションを公開しています。ワクチンの効果は、打った人自身が病気にかかりにくくなるだけではありません。社会全体で免疫を持った人が増えることで病気が広がりにくくなる効果もあります。ある感染症に対して免疫を持つ人が十分に増え、急速に感染が広がることが防がれる状態を「集団免疫」といいますが、この概念をシミュレーションでわかりやすく解説したものです。
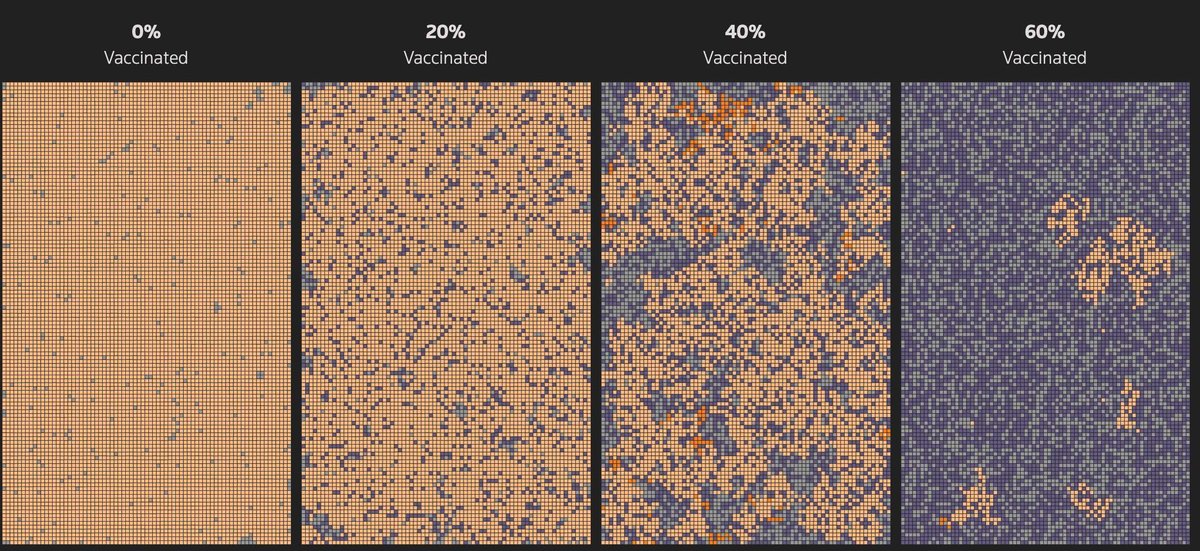
この記事では、ライフゲームのように人ひとりを1つのセルに見立て、隣に感染を広める様子をシミュレーションしています。ワクチンを打った人の割合や、「4人に1人が旅行をした場合」「マスクを着けた場合」など、さまざまな条件を加味して感染の広がりを見ることができます。特に劇的な違いがあるのはワクチンを打った人の割合です。ワクチンを打った人が0%の世界では瞬く間に感染が広がっていきますが、60%の人がワクチンを打っていれば感染の広がりは局所的なクラスターに収まり、全体には広がらないことがわかります。
興味深いのが、どちらの記事もあえて固定したアニメーションにはせず、プログラムでシミュレーションさせていることです。ユーザーが記事を「読む」ことだけを考えれば同じことに見えますが、ページの更新や時間の経過によってシミュレーションが再度実行されると、当然ながら先ほどとは異なる感染の広がり方をします。ついつい何度もシミュレーションを実行したくなります。以前の連載ではインタラクションが重要である旨の解説をしましたが、これもインタラクティブ性を持たせる工夫のひとつだと思われます。
データで人を説得する
データを可視化する大きな目的のひとつが、人を説得することです。ビジネスの現場では上司やクライアントを説得することが多いでしょうが、データを使った報道もある意味では読者=一般社会を対象とした説得であるといえます。
データを使った説得において何よりも気をつけるべきことは「データ以外のものに敬意を払うこと」です。自戒を込めて言いますが、データを使った分析や議論をしていると、自分の頭が良くなったような気になって「上から目線」の態度になりがちです。
たしかにデータからわかる知見は多岐にわたりますが、データだけですべてが理解できるほど現実は甘くありません。業務知識(IT業界ではドメイン知識とも呼ばれます)に長けた現場担当者の直感や経験則が表面的なデータ分析よりも有益な知見をもたらすこともあります。
それは報道でも同じです。私自身はデータによる報道を仕事にしていますが、一般的な記者が行う個別の当事者への取材がデータより劣っているとはまったく思いません。個別の事例を見る「虫の目」と全体を俯瞰する「鳥の目」は、いわば車の両輪のようなもので、どちらの視点が欠けても社会に有益な情報を提供できません。
漫画やドラマでも、データ分析を駆使して主人公の前に立ちはだかる、いわゆる「データキャラ」は嫌われがちです。データを振りかざした挙句、主人公にあっさり倒されるのがよくある展開です。
「データですべてがわかる」「何でもいいから数が揃えば信頼できる結果が得られる」という傲慢な考え方は、必ず可視化にも現れます。データは、決して相手を「論破」するための道具ではありません。データを使って議論や分析をする際は、「ここから先はデータでは判断できない」というデータの限界を自覚する必要があります。
さて、データをもとに人を説得する際、最も難しいのが「人の直感とデータが異なる場合」でしょう。ビジネスにおける現場の感覚や、社会における一般的な感覚とデータが一致している場合は問題ありませんが、「きっと何かが間違っているのだろう」とデータを捨ててしまうのも、「データがすべて正しい」と盲目的に信じ込むのも危険です。このような場合、データが間違っている可能性をあらゆる面から検討しつつ、その結果によっては従来の認識を覆す必要があります。この工程は「間違っている可能性」をひとつずつ潰していく過程であり、多大な手間がかかる割りに「これで絶対に間違いない」とは言い切れないのが辛いところです。
高野陽太郎『「集団主義」という錯覚』(新曜社、2017年)という書籍があります。これは「日本人は集団主義的である」「アメリカ人は個人主義的である」という通説が本当に正しいかどうか検証した書籍です。このステレオタイプは数十年以上前からまことしやかに言われてきた日本人論ですが、数々の先行研究を精査したところ、「日本人よりもアメリカ人が個人主義的」と明確に結論づけられる研究はほとんどなく、むしろ逆(日本人よりもアメリカ人が集団主義的)の結果の方が多いことが判明しました。
本書では、事実の検証に始まり、この通説がなぜ成立したのか、さらに俯瞰して文化ステレオタイプの影響まで論じています。特に検証のフェーズでは、質問し調査や実験などいろいろな種類の先行研究を検討しています。見方を変えると、数十年以上にわたって根付いてきたステレオタイプをデータで批判的に検討する際には、ここまでの労力をかけて自説を補強しないとならない証左でもあります。
きっと本書が1つや2つの調査・実験結果だけをもって「通説は間違いだ」と強く主張していたら、ここまでの説得力は持たなかったことでしょう。本書における通説の丁寧な検討は、データによる説得を行う上での参考になります。
つづく