
データを伝える技術 第2回 データを編集する 前編

執筆:荻原 和樹
データをグラフや地図といった視覚表現に変換するためには、まずデータの項目を絞り込んだり、集計したり、他のデータと組み合わせたり、といった作業が必要です。インタビュー記事やその他の文章を編集する作業と似ているため、私はこれを「データの編集」と呼んでいます。言い換えると、データ編集とは「データの意味や社会的なニーズを踏まえて、具体的な仕様やデザインに落とし込むこと」だといえます。
データの編集を行うためには、データをどのような表現に変換するかを念頭に置く必要があります。また、データの構造や意味内容に関しても意識しなければいけません。データ可視化においてはコンテンツ、デザイン、コード(プログラム)それぞれのスキルや知識が必要だと言われますが、編集の過程においては3種類の視点を総合して考える必要があります。
データの内容や状況(ビジネス、報道、研究など)によって具体的なアプローチの方法は様々あると思います。ここでは私がふだん「データ編集」の際に意識していることを書きます。

データを絞る
まず最初に行うのはデータを絞ることです。一口に「人口データ」「所得データ」といっても、政府統計などでは非常に細かく定義や項目、推計値・確定値が分かれている場合が少なくありません。何も考えずにすべてのデータを網羅しようとすると、素人目には判別がつかないデータが数十項目並ぶことになるかもしれません。
一方で、ユーザーがすべてのデータを見たがっているとは限りません。おそらくほとんどのケースにおいて、ユーザーは「人口」といったら特定の1つのデータを必要としているはずです。その場合、「とりあえず全部のデータを見せます」よりも、「あなたが最も必要としているデータを1つ見せます」の方が親切でしょう。
もちろんユーザーが必要としているデータは状況によって変わりますし、データの数字だけを見ていてもその判断はできません。やや抽象的な表現で恐縮ですが、データを提示する文脈や、ユーザーの知識やニーズなどを考えてデータを絞り込むことが必要です。
たとえば新型コロナウイルス感染症に関して、厚生労働省は報道発表資料において以下のようなデータを毎日発表しています。

PCR検査実施人数、陽性者数など、発表日時点における各種のデータが並んでいます。
2020年の感染初期にはここの情報が公式に発表されるもののほとんど全部でした。執筆時点(2022年1月時点)では厚生労働省が感染状況に関するオープンデータを公開したり、内閣府が独自にダッシュボードを公開していますが、当時はこの画像でしかデータが更新されないため、手作業で毎日データを更新していました。
さて、この中で実際にふだんの報道で見ているものをピックアップするとこうなります。
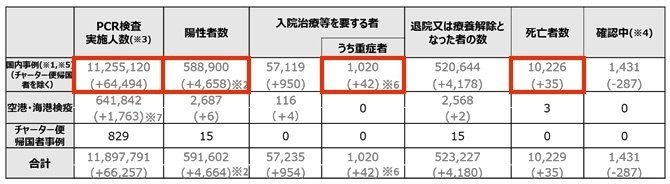
この表は厚生労働省が毎日の発表の冒頭に掲載しているだけあって重要なものですが、それでも日々の報道などには一部の項目しか使われていないことがわかります。大手メディアの公開するデータダッシュボードも、これらの項目とあとは数項目だけ網羅しているケースが大半です。表に掲載されている項目をすべてそのまま載せているケースはないと断言してよいでしょう。
ここで特に注目すべきは「合計」ではなく「国内事例」という名前のついた行を使っている点です。ここには2020年1月の感染初期に武漢から政府チャーター便で帰国した人々や、空港・海港での検疫での検査などは含まれていません。また、2020年2月に横浜に停泊したダイヤモンド・プリンセス号での感染事例も、法的には日本国内での事例には含めないため、ここにはカウントされていません。
データ可視化において、「どれだけ多くのデータをユーザーに見せるか」は重要なポイントではありません。あくまでも最終的にはユーザーがデータを理解したり、データについて新たな発見をしてほしいはずです。そうであれば、どれだけ多くのデータを見せるかは手段でしかありません。見せるデータが少なくても、そこから得られる示唆や考察を考えてデータを絞ることが重要です。
数字のメタファーを考える
ではなぜ「合計」ではなく「国内事例」が使われているか。もちろんデータを可視化しているメディアそれぞれに理由はあるでしょうが、おそらく大きな理由は「感染状況のデータが自分自身の感染危険度のメタファーになっているから」でしょう。ここでは数字から逆算できる意味や暗示をメタファーと呼びます。
感染状況のデータを通じてユーザーが知りたいのは、自分や家族、友人が実際に感染する危険度があるかどうかです。したがって、市中感染の危険度にあまり関係しない空港検疫などの数字は省いても問題ないくらいに重要度が低いといえます。
このように、数字の意味について考えるときは、「そのデータが何を暗示しているか」「その数字から何がわかるか」を想像するのがお勧めです。よく「目標を数字で測れるようにしよう」といった「数字への変換」がよく言われますが、その逆だと考えてください。ビジネスでいうと、KPI(Key Performance Indicator)からゴールを逆算するようなイメージです。
もちろん、思いついたメタファーを何でも採用してよいわけではありません。先の事例では観光客数のデータを持ってきて「これらは休暇の取りやすい国です」などと分析しても説得力が薄いでしょう。データからある命題が導けるかどうか、言い換えるとメタファーの確からしさは「ほぼ確実に言える」から「もしかしたら言えるかもしれない」まで幅があります。
たとえば前回の連載で登場した観光客数のデータについて考えます。「各国・地域から日本を訪れた観光客数」は何を暗示しているでしょうか。まず思いつくのはその国の所得水準が高く、飛行機に乗って遠く離れた日本まで旅行するくらいの経済的余裕があるか、などでしょうか。あるいは、単に人口が多くて日本を訪れた人数もその分多いだけかもしれません(この場合は人口あたりの数字を計算して均してみるとよいでしょう)。他には、俗に親日度などと表現される、日本に対する好感度や興味が強い国を示している可能性もあります。欧米から日本まで来るにはお金だけでなく時間もかかりますから、観光客数の上位に来る欧米の国では「休暇の取りやすさ」なども関係しているかもしれません。
感染状況のデータも、複数の意味を逆算できます。先に書いた「その地域の感染危険度」だけではなく、報道では「国や地域の感染対策がどのくらい成功しているか」を示す指標として使われます。たとえば各国の水際対策やロックダウン政策に関する解説と一緒に、国際比較の感染データが示される場合があるかもしれません。
もちろん、あるデータが完璧に何かのメタファーを表象していることは滅多にありません。感染状況のデータが「その地域の感染危険度」を十全に表しているかといえば疑問が残ります。特に感染者数の水準が低い地域では、大規模なクラスターが1件発生しただけでその地域全体の数字が跳ね上がる場合があります。また、その地域での検査体制(症状のある場合しか検査を行わない、あるいは逆に濃厚接触者などに積極的な検査を促すかなど)といった「感染危険度」以外にも感染者数の数字を上下させる原因はたくさんあるでしょう。
あくまでも現在公開されている感染者数データは「その地域の医療機関でPCR検査や抗原検査を受け、陽性だった人の数」でしかありません。おそらく現在日本で公開されているデータの中では最も感染危険度を測るのに適したデータであることは確かですが、そのまま「感染危険度」として扱うにはあまりにノイズが多いことには留意しておくべきでしょう。
ちなみに「ノイズが多い」原因のひとつは、地域の粒度が広すぎることにあります。たとえば「神奈川県の感染状況」がわかったとしても、それが横浜市なのか、川崎市なのか、あるいは江ノ島なのかはわかりません。そして、日本では私の知る限り新型コロナの接種状況を市区町村のレベルでまとめている公的機関や研究機関はありません。
翻ってアメリカでは、公的機関であるCDC(疾病予防管理センター)が郡(County=全米に3,000ほど存在する「州」よりも細かい行政単位)ごとにデータを公開しています。

報道機関でも、New York Timesなどが同程度に詳しいデータサイトをメンテナンスし続けています。

「日本のデータ活用やオープンデータは遅れている」と言われて久しいですが、まさに今回のような場面で社会のデータ活用に関する「地力」の差が出ていると感じています。
データに「補助線」を引く
データは必ずしも単体で意味を読み取れるとは限りません。そのデータだけ眺めているだけでは単なる数字にしか過ぎず、別のデータを組み合わせたり、あるいは何らかの「補助線」を引くことでデータに意味が与えられる場合もあります。
身近な例で言うと、出土した恐竜の化石などの大きさを表現するために身長170cm程度のヒトをそばに置いたり、あるいは小さいモノの写真を撮るために(今となっては古い表現ですが)タバコと比べることがあります。身近なもの、ユーザーが想像できるものと比較することがこの場合の補助線です。
データにおいても同じことが言えます。従来、日本の高校野球において、投手が短期間にあまりにも多くの投球を行い、その結果として肘や肩を故障する「投球過多」の問題が指摘されてきました。プロ野球と異なり、部員数が限られる高校野球では投手の代わりがおらず、1人の選手がすべての試合でマウンドに立つこともあるためです。
投球過多の問題は昔から言われてきたことであるため、高校野球のファンなら聞いたことがあるかもしれません。近年だと2018年夏の甲子園で「金農旋風」と呼ばれた秋田県代表・金足農業高校において、エース投手を努めた吉田輝星選手を含めてレギュラー9名を交代せずに起用し続けました。吉田投手は甲子園決勝の5回で交代したものの、それまでの地方大会・本大会をすべて1人で投げ抜くことになりました。これだけが理由ではないでしょうが、翌年2019年の4月には日本高野連により「投手の障害予防に関する有識者会議」が発足しました。
このような状況を受けて、私が高校野球の投球過多に関するインフォグラフィックを作ろうと考えたのが2019年夏のことです。先に書いた通り、高校野球における投球過多は徐々に社会問題として認識されつつあったものの、強く意識しているのはこれまでの経緯を把握している高校野球ファンが中心でした。そしてその高校野球ファンの中にも、「限界を超えて頑張った」ことを美談として捉える向きがあり、社会的なコンセンサスが取れているとは言い難い状況でした。そこで、データとグラフィックを使って高校野球にふだん馴染みがない読者にも広く伝えることができれば、社会的な意義が出るだろうと考えました。
以下がそのグラフィックです。

さて、問題となるのが「どう伝えるか」です。先ほど「金足農業高校の吉田投手は1人で地方大会と本大会を決勝の途中まで投げ抜いた」と書きました。具体的に数字に表すと、本大会では881球、地方大会を合わせると1517球です。この数字だけで野球に馴染みのない読者に伝わるか、といえば答えは否でしょう。
「2018年の金足農業高校・吉田輝星選手は881球、2006年の早稲田実業・斎藤佑樹選手は948球」といった投球数の単純なまとめは他のメディアもすでに行なっていた。関連語句で画像を検索すると、ランキングを表した画像がすぐにヒットします。しかし、そうした画像がSNSで広くシェアされていないことからも、数字を羅列するだけでは広く社会に響かないことが想像されました。
数字を羅列するだけでは伝わらない、では何が必要か? 次に考えたのは、比較軸を設定することで重大さを知ってもらうことでした。まず最初に考えたのは、日本のプロ野球と比較することです。高校野球と異なり、プロ野球では1つのチームに複数の投手がおり、ローテーションも機能しているため、そこと比較できないかと考えました。
しかし投球数や登板間隔などの数字を見ていくうちに、それは難しいことがわかってきました。そもそも春夏で2つのトーナメント制大会をベースとする高校野球と、リーグ戦をベースとするプロ野球では試合の間隔や期間がまったく違います。これらを無視して投球数といった数字だけ比較することは、むしろ読者の混乱や誤解を招くと感じました。
さらに調べていくうちに、アメリカには「ピッチ・スマート(Pitch Smart)」と呼ばれる青少年向けの投球ガイドラインが存在することを知りました。まさに日本で問題になっている投球過多による故障などを防ぐためのガイドラインであり、年齢別に1日あたりの投球数や休養日数などが細かく整理されていました。

この中から、明確に違反とわかる投球数に関する定量的なルールを2つ抜き出し、甲子園投手たちの投球数にあてはめることにしました。具体的には1日あたりの投球数制限と、投球数ごとの休養日です(余談ですが、これらのデータを出すためには投手の試合日程と試合ごとの投球数を知る必要があり、データの収集になかなか時間がかかりました)。
すると、予想通り多くの投球がピッチ・スマートの制限に違反することがわかりました。選手によっては本大会における投球のうち3分の2以上がガイドライン違反となりました。特に大きかったのが休養日制限です。今回のインフォグラフィックでは1日あたりの投球数制限、休養日制限と、どちらに抵触したかを色で分けていますが、全体のうち多くが休養日制限によるものだとわかります(両方に引っかかるものは休養日制限の色で統一していることに注意)。
ここには甲子園の大会日程が関係しています。甲子園はトーナメント制であり、大会の序盤は参加チーム数も多いため、試合から次の試合までが数日から1週間空くこともあり、投手は十分な休養を確保することができます。しかし後半はチーム数が少なくなり、試合のスケジュールも過密になります。たとえば先に挙げた金足農業の吉田輝星投手の場合、2018年8月17日から21日までのわずか5日間で、3回戦から決勝まで4試合に登板しています。この間の投球数は570球です。
その後、有識者会議の議論も経て、2020年には初めて高校野球における投球制限が設けられることになりました。
なお今回の結果は本大会に限り、またPitch Smartの中でも2つのルールだけをもとにしたものです。たとえば地方大会までを計算対象としたり、「12ヶ月以内に100イニングを超える投球を行わない(Do not exceed 100 combined innings pitched in any 12 month period)」といった他のルールもあわせて考えると、本来なら投げてはいけない投球がもっと増えるかもしれません。
伝えようとしている題材について、ユーザーが必ずしも数字の「相場感」を持っているとは限りません。単独の数字だけを提示した場合では文脈や重要さがわからないものであっても、比較対象や基準といった補助線を引くことで意味を持たせることができます。
データの「意味」を考える
データは単なる数字の羅列ではなく、それぞれに「意味」があります。たとえばまったく同じ数字の並びでも、それが「学校で拾ったどんぐりの数」なのか、あるいは「内戦における死者の数」かによってユーザーの受け取り方は異なるでしょうし、伝え方も変わります。もちろん過剰に演出する必要はありませんが、データの意味を考えずに可視化することは、口調をまったく変えずに褒めたりけなしたりするのと同じくらいユーザーに違和感を与える場合があります。
この問題に関して考えるべき事例があります。2013年、イギリスを拠点とするグラフィック・デザイナーのマシュー・ルーカス(Mathew Lucas)は、1945年に広島に落とされた原爆にまつわる一連のインフォグラフィックを発表しました。「ヒロシマ・マッシュルーム(Hiroshima Mushroom)」「ヒロシマ・レティクル(Hiroshima Reticle)」「ヒロシマ・アトム(Hiroshima Atom)」とそれぞれ名付けられたグラフィック・アート作品では、ヴィルヘルム・レントゲンによる1895年のX線発見から広島への原爆投下に至るまで、放射線やウランに関する歴史的出来事が、それぞれ原爆のキノコ雲、上空から見た爆心地の光景、ウラン原子をモチーフとした抽象的なグラフィックで表現されています。

ルーカスは科学系メディア「ポピュラー・サイエンス(Popular Science)」のインタビューに対して「原爆投下だけではなく、それに至るまでの過程を描いた作品にしたかった」と答えています。
これに対し、アメリカのビジネスメディア『ファスト・カンパニー』の記者マーク・ウィルソン(Mark Wilson)は「恐ろしい出来事に関してむやみに美しいビジュアライゼーションを作らない理由(Why You Don’t Make A Mindlessly Beautiful Visualization Of A Horrific Event)」と題して、同作品を批判しています。

記事ではルーカスの作品に対して「知的に描かれた魅力的な作品であるが、違和感がある」と前置きした上で、作品に関してTwitter上で起こったデータ可視化のクリエイターや研究者たちの議論を取り上げます。そして「ルーカスによる広島のグラフィック作品が私たちを悩ませるのは、恐ろしい出来事を美しく描いているからだけではない。これらの作品は究極的には無神経なものであり、実際に悲劇に何らかの新しい洞察をもたらすよりも、自らの巧妙で美的な機構に耽溺している」と結論づけています。
言うまでもなく、広島や長崎への原爆投下は人類史上で唯一の核攻撃であり、夥しい数の民間人が亡くなった大量殺戮です。広島市では、放射線による急性障害も含めて1945年12月末までに約13万人が亡くなったと推計しています。本稿執筆時点(2022年1月)で76年以上が経っているとはいえ、未だに後遺症に苦しむ人や、親族が苦しんでいる人もいるでしょう。そのような状況において無邪気に美しいデータ可視化を行うことが「無神経なもの」と批判されることは想像にかたくありません。
絵画や写真、テキスト記事やテレビ番組などと同様に、データ可視化は決して価値中立的な表現手段ではありません。何らかのトピックを美しく表現することは、ユーザーに暗黙的な価値判断を提供することがありえます。しばしばフィクション作品では、味方は整った顔立ちで、敵は醜く描かれます。美しい形で何かを表現することは、その行為そのものが暗黙的な肯定であると判断されても不自然ではないでしょう。
それは決して「悲劇的な出来事を美しく可視化してはいけない」ということではありません。データを広く伝えるにあたって、視覚的な要素を整理し、ユーザーの注意を換気したり、惹きつけることは非常に重要なステップのひとつです。そうではなく、悲劇的な出来事の悲劇性を忘れて美しく可視化してしまい、結果として美しさだけが印象に残ることが問題だと私は考えています。
このように倫理的な面でデータ可視化を批判された制作者が「自分はデータをそのまま可視化しただけであり、自分に責任はない」と居直ることがあります。しかし前述のようにデータ可視化を一種のコミュニケーションであると考えれば、そのような言い訳は少なくとも現代では通用しないことがわかります。
同じ轍を踏まないためにも、一部の人にとって著しく精神的な負荷のかかるトピック、たとえば自殺、いじめ、性犯罪といったセンシティブな話題に関しては、一般的なデータよりもずっと慎重な扱いが必要です。
つづく