
最新のリファレンスをAIに教えもらう(メモ)

やりたいこと
・AIに最新のフレームワークのリファレンスについて質問して回答をもらいたい
・今回はNext.jsについて公式のホームページから情報を取得してきます。
# 質問
next.jsのルーターの特徴を教えて
# 回答
'Next.jsのルーターの特徴は、ページを基盤としたファイルベースのルーティングシステムを提供していることです。これにより、ページごとにルーティングを定義し、簡単にページを追加できます。また、動的ルートやルートグループなどの高度なルーティング機能もサポートしています。方法
・OpenAI APIを使用して質問をします
・公式リファレンスを格納するデータベースを作成します
・質問と一緒に関連性の高いデータを一緒に質問に混ぜてリクエストします
・使用言語python,Jupyter Notebook形式で実行していきます
レッツスタート!
まずはOpenAI APIを使用する準備をします。

APIキーを作成します
クリエイトした時のキーはコピーしてどこかに保存しておきましょう
また後で使います。
作成時に表示されるキーは二度と見ることができないのでコピーし忘れたらもう一度作り直す必要がありますのでご注意を

次にデータベースを作成します。
APIにリクエストする際に一緒に参照してほしい資料を送るようにするのですが当然量が多くてすべてを送ることができません。
そこで質問に関連性が高い資料のみを選んで送信するようにします。
エンベディングというものを使うことでどうやらできるようです。
エンベディングとは何でしょうか?
すべての種類のデータを、空間内の点として表現する手法
例えば「犬」と「猫」は動物で似ている意味で座標的には近くなります
今回で言えばテキストがどの位置にあるかをOpenAI APIに聞いて
テキストと座標(ベクトル)をセットにしたデータベースを作成します
エンベディングを行うことができるAPIがあるのでリクエストを出して
座標(ベクトル)を取得します。
↓公式リファレンス
OpenAI API Embeddings

大変参考にした記事になります!
ChatGPT: Embeddingで独自データに基づくQ&Aを実装する (Langchain不使用) - Qiita
まずはデータを用意します
最初に必要なものをインストールします
今回はノートブック上でインストールしていますが
ターミナルでも大丈夫です(先頭の%は外します)
%pip install requests
%pip install beautifulsoup4
%pip install urllib3
%pip install nltk
%pip install pandas
%pip install tiktoken
%pip install openai使うものも一括でimportしておきます
import漏れで後のコードでもしていますかご愛敬ということで、、、
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from nltk.tokenize import sent_tokenize
import time
import nltk
nltk.download('punkt')
import pandas as pd今回取得するのはnextjsの公式ドキュメントです
https://nextjs.org/docs

https://nextjs.org/docs/
と付くURLをすべて取得したいのでまずはすべてのリンクを取得して関係ないものを省いていきます。
base_url = "https://nextjs.org/docs/"
# すべてのリンクを抽出する関数
def extract_links(url):
response = requests.get(url) # 指定されたURLのHTMLを取得
soup = BeautifulSoup(response.text, "html.parser") # HTMLをパース
# BeautifulSoupのfind_allメソッドを使って、すべての<a>タグ(ハイパーリンク)を抽出
# その後、urljoinを使って相対URLを絶対URLに変換
return [urljoin(url, link.get("href")) for link in soup.find_all("a")]
all_links = extract_links(base_url) # base_urlからリンクを抽出
display(len(all_links))
全部で324もリンクがあるようです
結構ありますね
# URLが目的のドメインに一致するか確認する関数
def is_valid(url):
parsed = urlparse(url) # URLをパース
# urlparseの結果からネットロケーション(ドメイン名など)とスキーム(httpやhttpsなど)が存在するかをチェック
# そしてURLがbase_urlで始まるものかどうかをチェック
return bool(parsed.netloc) and bool(parsed.scheme) and url.startswith(base_url)
valid_links = [url for url in all_links if is_valid(url)] # 有効なリンクのみをフィルタリング
display(len(valid_links))285個に絞れました。
次は文単位に分割していきます。
def get_text_from_url(url):
# URLからHTMLを取得します
response = requests.get(url)
# BeautifulSoupを使用してHTMLを解析します
soup = BeautifulSoup(response.text, 'html.parser')
# テキストのみを取得します
text = soup.get_text()
return text
def split_text_into_sentences(text):
# テキストを文単位に分割します(英語の例)
sentences = sent_tokenize(text)
return sentences
data = []
# 最初の3つのURLからテキストを取得
for i, url in enumerate(valid_links):
time.sleep(1) # 各リクエストの間に1秒の待ち時間を設けて負荷を軽減
text = get_text_from_url(url) # 上記のget_text_from_url関数を使用
sentences = split_text_into_sentences(text) # 上記のsplit_text_into_sentences関数を使用
for sentence in sentences:
data.append({'content': sentence})
df = pd.DataFrame(data)
print(f"The DataFrame has {len(df)} rows.")
df.head() # DataFrameの最初の5行を表示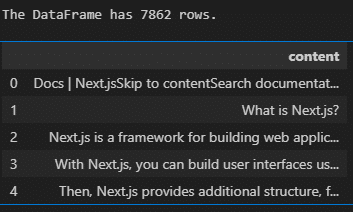
7862個の文章に分けることができました。
エンベディングに変換します
現在リストとして格納されているテキストをAPIリクエストを行って
エンベディングに変換しテキストと座標をセットでリストにします。
変換の際にも先ほどコピーしたAPIキーが必要になるので自分のキーを
入力してください
# 必要なライブラリをインポートします
import os
import openai
# OpenAIのAPIキーを設定します
os.environ["OPENAI_API_KEY"] = "ここにコピーしておいたAPIキーを入力"
# 環境変数からAPIキーを取得し、OpenAIライブラリに設定します
openai.api_key = os.getenv("OPENAI_API_KEY")
# 使用する埋め込みモデルを指定します(この場合は"text-embedding-ada-002")
EMBEDDING_MODEL = "text-embedding-ada-002"
# バッチサイズを定義します(この場合は1000);一度に2048までの埋め込み入力を送信できます
#1度に何個のデータをよりするかの設定
BATCH_SIZE = 1000
# テキストから埋め込みを生成する関数を定義します
def create_embeddings(items):
# 結果を保存するためのリストを作成します
embeddings = []
# バッチ処理を行います;ここではバッチの開始点を指定します
#range(開始位置、終了位置、増減幅)
for batch_start in range(0, len(items), BATCH_SIZE):
# バッチの終了点を計算します
batch_end = batch_start + BATCH_SIZE
# itemsから現在のバッチを取得します
#スライシングをします。1回目のループは0:1000までの要素を取り出します。
#スライシングの処理は1000こ要素がなくてもエラーにはならない
batch = items[batch_start:batch_end]
# バッチの開始と終了を表示します
print(f"Batch {batch_start} to {batch_end-1}")
# OpenAIのAPIを使ってテキストの埋め込みを生成します
response = openai.Embedding.create(model=EMBEDDING_MODEL, input=batch)
# 入力と出力の順序が同じであることを確認します
for i, be in enumerate(response["data"]):
assert i == be["index"] # double check embeddings are in same order as input
# 各バッチの埋め込みを取得します
# 内包表記のループ処理をしますjson形式のresponseのdataをeに入れてeのembedding"キーに対応する値を取り出す
batch_embeddings = [e["embedding"] for e in response["data"]]
# 全体の埋め込みリストにバッチの埋め込みを追加します
embeddings.extend(batch_embeddings)
# テキストとそれに対応する埋め込みを含むデータフレームを作成します
df = pd.DataFrame({"text": items, "embedding": embeddings})
return df
# ウィキペディアのセクションの内容をリストとして取得します
items = df["content"].to_list()
# 各セクションの内容から埋め込みを生成します
df_embedding = create_embeddings(items)
# 埋め込みが含まれたデータフレームから重複行を削除します
df_embedding.drop_duplicates(subset=['text'], keep='first', inplace=True)
# 埋め込みが含まれたデータフレームを表示します
display(df_embedding)

テキストが重複しているものを排除するようにしたので行数を減らすことができました。2000ちょっと減りましたね。なんでそんなに重複してるんだろ?
リストをデータベースに保存します
テキストと座標がセットになったものをリストで作成することができました。
これを使うためにchromabdを使っていきます
エンベディングデータベースを保存して検索することができます。
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
from chromadb.config import Settings
def create_chroma_client():
# ChromaDBの永続化ディレクトリを指定します
persist_directory = 'chroma_persistence'
# ChromaDBのクライアントを作成します
chroma_client = chromadb.Client(
Settings(
# 永続化ディレクトリとデータベースの実装を設定します
persist_directory=persist_directory,
chroma_db_impl="duckdb+parquet",
)
)
# ChromaDBクライアントを返します
return chroma_client
def create_chroma_collection(chroma_client):
# OpenAIを利用するエンベディング関数を定義します
embedding_function = OpenAIEmbeddingFunction(api_key=os.environ.get('OPENAI_API_KEY'), model_name=EMBEDDING_MODEL)
# 'stevie_collection3'という名前のコレクションを作成します
# ↓同じ名前の物は作れないのでエラーが出ます。
collection = chroma_client.create_collection(name='stevie_collection5', embedding_function=embedding_function)
# 作成したコレクションを返します
return collection
# ChromaDBクライアントを作成します
chroma_client = create_chroma_client()
# ChromaDBコレクションを作成します
stevie_collection = create_chroma_collection(chroma_client)
# 既存のデータフレームからデータを追加します
stevie_collection.add(
# データフレームのインデックスをIDとして使用します
ids = df_embedding.index.astype(str).tolist(),
# テキスト列をドキュメントとして追加します
documents = df_embedding['text'].tolist(),
# エンベディング列をエンベディングとして追加します
embeddings = df_embedding['embedding'].tolist(),
)
# 変更をディスクに永続化します
chroma_client.persist()
これでデータを保存することができました。
コードではstevie_collection5という名前でコレクション(データベースを管理するやつ)を作成していますが、同じ名前のコレクションを作成することができないので二回目実行する際には名前を変更してください。
ここで言うクライアントはデータベースの操作に使うツールの役割を果たしているようです。
では使ってみる
まずはchromabdが動作するかを試してみる
import chromadb
from chromadb.config import Settings
import os
import openai
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
from chromadb.config import Settings
GPT_MODEL = "gpt-3.5-turbo"
# OpenAIのAPIキーを設定します
os.environ["OPENAI_API_KEY"] = "ここにコピーしておいたAPIキーを入力"
# 環境変数からAPIキーを取得し、OpenAIライブラリに設定します
openai.api_key = os.getenv("OPENAI_API_KEY")
# 使用する埋め込みモデルを指定します(この場合は"text-embedding-ada-002")
EMBEDDING_MODEL = "text-embedding-ada-002"
def create_chroma_client():
persist_directory = 'chroma_persistence'
chroma_client = chromadb.Client(
Settings(
persist_directory=persist_directory,
chroma_db_impl="duckdb+parquet",
)
)
return chroma_client
def get_chroma_collection(chroma_client, collection_name):
# embedding function を作成
#コレクションを呼び出すときにクエリを変換する関数を一緒に渡さないといけないので、ここで呼び出す
embedding_function = OpenAIEmbeddingFunction(api_key=os.environ.get('OPENAI_API_KEY'), model_name=EMBEDDING_MODEL)
# 既存のChromaDBコレクションを取得します
collection = chroma_client.get_collection(collection_name, embedding_function=embedding_function)
return collection
# ChromaDBクライアントを作成します
chroma_client = create_chroma_client()
# 既存のChromaDBコレクションを取得します
stevie_collection = get_chroma_collection(chroma_client, 'stevie_collection5')
# 関数定義
def query_collection(
query: str, # クエリ文字列
collection: chromadb.api.models.Collection.Collection, # ChromaDBのコレクション
max_results: int = 100 # 返す結果の最大数
#↓は型ヒント 何を返すかを示しますタプル型の二つの要素で文字列のリストと浮動小数点数のリストを返します。
)-> tuple[list[str], list[float]]:
# コレクションをクエリして結果を取得します
# 'documents'と'distances'を含む結果を要求します
results = collection.query(query_texts=query, n_results=max_results, include=['documents', 'distances'])
# 文書とその距離(関連性スコア)を取得します
strings = results['documents'][0]
relatednesses = [1 - x for x in results['distances'][0]]
return strings, relatednesses # 文書とそれぞれの関連性スコアを返します
# クエリを投げて結果を取得します
strings, relatednesses = query_collection(
collection=stevie_collection, # クエリを実行するコレクション
query="next.jsのroutarの使い方をコードで教えて?", # クエリ文字列
max_results=5, # 最大結果数
)
# 各文書とそれぞれの関連性スコアを表示します
for string, relatedness in zip(strings, relatednesses):
print(f"{relatedness=:.3f}") # 関連性スコアを表示
display(string) # 文書を表示

今回は日本語で「next.jsのroutarの使い方をコードで教えて?」
と日本語で書いたので英語の資料と関連性をしっかり見つけることができているのかは不明です。
ですが動作は確認できました。
質問してみる
def query_message(
query: str, # クエリ文字列
collection: chromadb.api.models.Collection.Collection, # ChromaDBのコレクション
model: str, # 使用するモデル(OpenAI GPT)
token_budget: int # トークンの上限数
) -> str:
# コレクションからクエリに関連するドキュメントを取得します
strings, relatednesses = query_collection(query, collection, max_results=6)
# メッセージの導入部分を定義します
introduction = '以下の記事を使って質問に答えてください。もし答えが見つからない場合、「データベースには答えがありませんでした。」 と返答してください。回答は日本語でしてください\n\n# 記事'
# メッセージに質問部分を追加します
question = f"\n\n# 質問\n {query}"
message = introduction
# 各ドキュメントについて、トークンの上限を超えないように追加します
for string in strings:
next_article = f'\n{string}\n"""'
# 既存のメッセージに次の記事を追加した場合のトークン数が上限を超えるかをチェックします
if (
num_tokens(message + next_article + question, model=model)
> token_budget
):
break
else:
message += next_article
# 質問部分を含む完成したメッセージを返します
return message + question
def ask(
query: str, # クエリ文字列
collection = stevie_collection, # デフォルトのコレクション
model: str = GPT_MODEL, # 使用するモデル(OpenAI GPT)
token_budget: int = 4096 - 500, # トークンの上限数
print_message: bool = False, # メッセージをプリントするかどうか
) -> str:
"""GPTと関連テキストとエンベディングのデータフレームを使ってクエリに答えます。"""
# 適切なメッセージを作成します
message = query_message(query, collection, model=model, token_budget=token_budget)
if print_message:
# メッセージをプリントします
print(message)
# GPTへのクエリメッセージを作成します
messages = [
{"role": "system", "content": "next.jsについて答えます。回答は日本語でしてください"},
{"role": "user", "content": message},
]
# GPTにクエリを投げて結果を取得します
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0
)
# GPTからの返答を取得します
response_message = response["choices"][0]["message"]["content"]
return response_messageask("next.jsのルーターの特徴を教えて", print_message=True)質問
ask("next.jsのルーターの特徴を教えて", print_message=True)
答え
Next.jsのルーターの特徴は、ページを基盤としたファイルベースのルーティングシステムを提供していることです。これにより、ページごとにルーティングを定義し、簡単にページを追加できます。また、動的ルートやルートグループなどの高度なルーティング機能もサポートしています
資料も一緒に送ることができましたがうーん
活用されたのかようわからん結果となりました。
最新の情報なのか、既存の学習から回答しているのかはっきりしなかったので、もっとわかりやすい情報にすればよかったですね。
次回挑戦してみようと思います。

感想
使えそうな技術ではあるなと思いました。
Q&Aのデータベースを作成すればそれに特化したチャットボットが作成できるのではないかと思います。
エンベディングのコストとしては2回変換して0.1ドルくらいだったので無料枠の範囲内で全然使えそうです。
ほかにもfine tuningで回答を学習することができるようなのでそちらも試してみようと思います。
この記事が気に入ったらサポートをしてみませんか?