
VRoidコピー機学習

なにこれ?
私が勝手に脳内でそう呼んでるだけですが、Loraファイルの作成にVRoidコピー機学習という手法をよく使っています。
元ネタは、エマノン氏の下記記事で、原理としては同じものです。
上記記事では、今は亡きIllusionの3Dゲームからキャプチャした画像を使用しています。
私もいくつかIllusionのゲームは持っているのですが、キャプチャや画像の加工が面倒だったので、なにか他の方法はないかな、と考えていました。
そして、昔Vtuberになれないかなーとか妄想していた(無謀)ときにVRoidStudioというツールを使ったことがあり、これだ、と思っったわけです。
最初はこのツールの撮影機能で画像化しようと思ったのですが、いくつもの構図で画像を作るのはやはり面倒で、ボタン一つで特定の構図で撮影できるものは無いか、と考えました。
いろいろ試したのですが、最終的にBlenderにたどり着きました。
まあ、Blenderなら絶対できるよな、とは思っていたのですが…
(両方ともSteamにもあります。私はSteam版を使っています。)
ということで、VRoidStudioとBlenderを使って、コピー機学習に必要な素材ファイルを作成しようとなったわけです。
VRoidコピー機学習の手順
試行錯誤はありましたが、現在は以下のような手順でLora学習を行っています。
なお、VRoidStudioもBlenderも完全に初心者で、必要な分だけ使い方を検索しながらやっていますので、いろいろ変なところがあるかもしれません。
また、私自身説明が上手いわけでも無いので、色々説明に抜けがあるかもしれません。
学習に使用する3Dデータの準備
コピー機学習の踏み台となるVRMと、実際に学習させるVRMを作成します。
踏み台は、学習させたくない要素を持っったデータにします。
今回はキャラLoraを作る前提で、すべてデフォルトで、髪と衣装を外したものにしました。
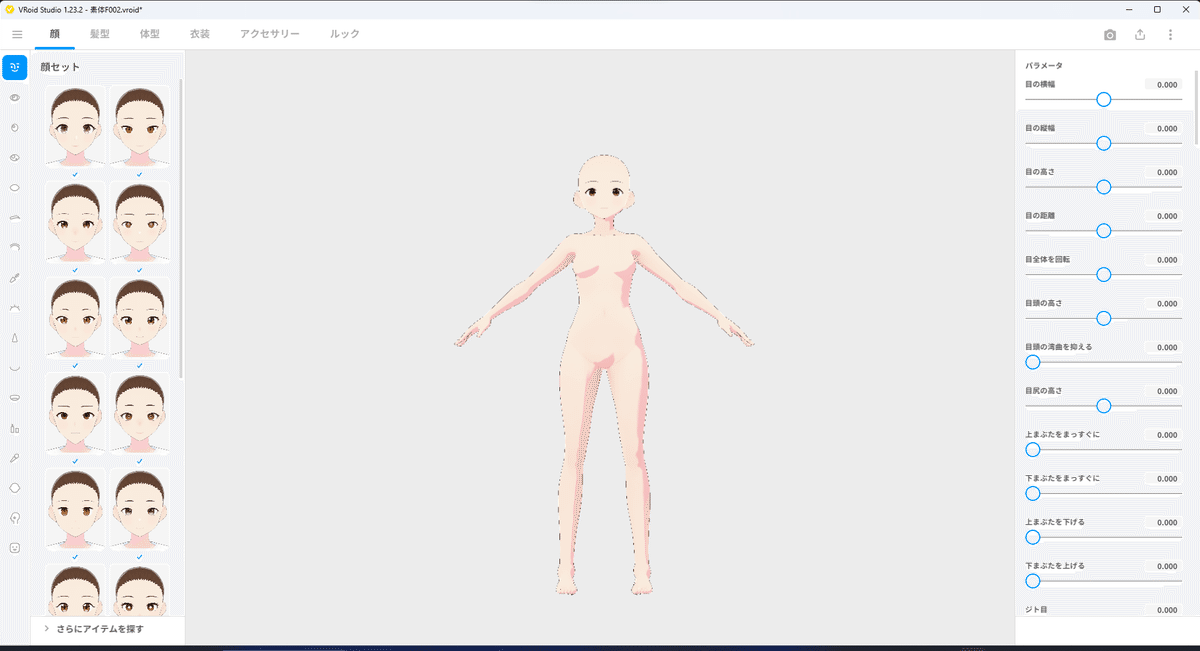
そして、実際に学習させるデータは、先程の踏み台から学習させたい要素を変化させます。
※今のところ、3Dモデルの身長が変わるとややこしいので、身長は変えないようにしています。

ここでの変化がどの程度Loraに反映されるかはまだ試行が足りていません。
現状わかっているのは髪型と髪色はほぼ学習され、目はちょっと怪しいです。
特に服装はかなり強く学習される傾向があるため、プロンプト側で服装を指定したい場合は注意してください。
※それを利用して服装Loraとかも考えていますが、それは今後試します。
撮影環境データの作成
Blenderで撮影用のファイルを作ります。
このデータは後々使いまわします。
・ライトの配置
ネットでざっくり調べた結果、3点ライティングという方法がポピュラーっぽい。
よくわからないけど、記事を読んでそれっぽく配置。


・カメラの配置
各構図に必要なカメラを設置。
キャラクターの向きは、キャラクター自体を動かすので、高さがfrom avobeとfrom below、あとは水平(便宜上from levelと表記)の3つと、ズームがfull body、cowboy shot、upper body、protrait、close-upの5つ、3×5の15個所にカメラを設置します。

なお、カメラの名前は後のマルチビューで重要になります。
命名規則はこの通りでなくてもいいですが、個々のカメラの末尾がカメラごとに一意(ユニーク)になるようにしてください。
※私はcamera.(ズームタグ)-(高さタグ)としています。

・マルチビューの設定
配置したカメラすべての画像を出力するため、プロパティの出力の立体視にチェックを入れ、マルチビューを選択します。

ここに、作成した15個のカメラを設定していきます。
カメラ接尾辞にカメラの名前の一意な末尾を入力します。
※私の場合、.(ズームタグ)-(高さタグ)を入力しています。
・キャラクターの配置とアニメーション
VRoidStudioで作成したモデルのVRMファイルをインポートします。
最初はコピー機学習の踏み台となるモデルを読み込みます。
読み込んだモデルのアーマチュアが45°ずつ回転するようにアニメーションを設定し、8フレーム(1回転分)だけ出力するように設定します。



・ファイルの出力先の設定
プロパティの出力の出力に出力先のパスを設定します。
また、ビューのフォーマットを個別にします。

これでアニメーションレンダリングを行うと、指定されたフォルダに画像が生成されます。
このデータを保存しておき、実際に学習させるデータを撮影する際にVRMに差し替えて流用します。
あとは、sd-scriptsのDB方式のキャプションあり、で学習させます。
キャプションはこんな感じの内容としています。

girl, close-up, from above

girl, close-up, from below, from side
必要かわからないというか、指定しない方法が分からなかったので、トリガーワードはgrilにしています。
あとは、構図に関する情報を記載していきます。
向きについては、0°を正面として、絶対値45°~90°をfrom side それ以外をfrom behindとしています。
これについては、最適なのかはまだわかっていませんが、今のところキャラLoraならこれで問題なさそうです。
同様の作業で、実際学習させるVRMデータも画像化しておきます。
キャプションは踏み台のものと同様ですが、今回は学習させたくない、白背景、ヌード状態、髪の色、目の色をキャプションに追加しておきます。
この辺は、目的に応じて変わると思います。

girl, close-up, white background, nude, brown hair, brown eyes
ただ、現状では髪の色と目の色は除外できているか微妙です。
特に、踏み台に髪がないので差分として強く学習されているような気がします。
※キャプションで指定したタグも学習はされるため。
キャラLoraとしてはさほど問題ないので、一旦ここは無視しています。
準備した画像を元に、まずは踏み台モデルを作成します。
踏み台モデルとは、どんなプロンプトを指定しても、特定の画像が出る過学習状態のモデルです。
今回の場合は、一般的なコピー機学習と違い、構図の指定はある程度反映された上で、踏み台の3Dデータのようなものがプロンプトに関わらず出てくるようになればOKです。
Lora学習そのものは説明しているとかなり長くなるので、今回は割愛させて頂きます。
パラメータとしては、こんな感じです。
ベースモデルはanyloraにしました。
※なんでもいいと思います。が、リアル系はちょっとむずかしいかも?
pretrained_model_name_or_path=hogehoge/anyloraCheckpoint_bakedvaeFtmseFp16NOT.safetensors
max_train_epochs=5
resolution=512,512
optimizer_type=AdamW8bit
learning_rate=1e-4
network_dim=128
network_alpha=64
clip_skip=2
(mixed_precision=bf16)
ここはグラボによります。私はRTX4070使ってるので、これにしています。
出来上がったLoraをSuperMagerでベースモデルにマージします。
参考:マージモデルでの出力

best quality,
solo, girl,
Negative prompt: EasyNegativeV2,
Steps: 60, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 2356118749, Size: 512x512, Model hash: 49925cca8f, Model: anyloraCheckpoint_bakedvaeFtmseFp16NOT+base02, TI hashes: "EasyNegativeV2: 339cc9210f70", Version: v1.6.0
こんな感じで、元の画像に近いものが出てきます。
また、3Dをレンダリングした感が出ていることが重要で、次の本番のLora学習の際に、モデルの出力が3Dっぽさを含むため、教師画像との3Dっぽさとの差分が少なくなり、学習されにくくなります。
※この辺が、ネタ元のエマノン氏が考えた原理。
踏み台マージモデルが準備できたら、そのマージモデルをベースモデルにして、本番の実際学習させる画像を使って学習を行います。
その結果がこちら。
※bluePencil_v10にLoraを適用

best quality,
solo, girl,
<lora:character005:1>
Negative prompt: EasyNegativeV2,
Steps: 60, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 172364617, Size: 512x512, Model hash: 3a105af1a6, Model: bluePencil_v10, VAE hash: ab33ad55c6, VAE: ClearVAE_V2.3.safetensors, Lora hashes: "character005: 41fdabc75f96", Version: v1.6.0

もうちょっと詰めたほうがいいかな、という気はしますが、特に指定しなくとも、髪が括られています。
また、3Dっぽさは感じられません。
私はネタ元のエマノン氏よりも、キャラクターの再現性が低いのは雰囲気が出ればいいやくらいでやっていて、いくつかの工程を省略したりしています。
私としてはおおよそ満足の行く結果が出ているかな、というところです。
また、これを応用して、表情や服装、ポーズなどのLoraが作れないか、考えているところです。
そちらも試してなにか結果が出れば、また記事にしたいと思います。
おまけ

best quality,
solo, girl,
<lora:character005:1>
Negative prompt: EasyNegativeV2,
Steps: 60, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 1684127384, Size: 512x512, Model hash: c1d3d52173, Model: bluePencilRealistic_v1, VAE hash: ab33ad55c6, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Lora hashes: "character005: 41fdabc75f96", Version: v1.6.0
2.5次元系なら多分いける。
この記事が気に入ったらサポートをしてみませんか?