
PyCaretの基本的使用方法とその活用例(BitCoinの将来価格予測)

PyCaretはローコードで機械学習を自動化するライブラリで、scikit-learnだけでなく、LightGBMやOptunaなどのライブラリをまとめたPythonラッパーです。データセットと数行の命令を与えるだけで、前処理、モデルのトレーニング、評価、比較モデルの保存まで可能で大変便利です。
この記事ではまずPycaretの基本的な使用法を示し、そのあとビットコインの価格予測をテーマに少し応用的な使い方まで踏み込みます。
公式ドキュメントのチュートリアルはこちらをチェック
大まかな使い方は下記のステップです
必要なライブラリをインポートする
データセットを読み込む
PyCaretの環境を設定する
モデルを比較する
モデルを選択し、チューニングを行う
モデルを評価する
未知のデータに対して予測を行う
モデルの保存
まずはpipコマンドでライブラリをインストールしてください。
(以前はここで少しつまずいたのですが、PyCaret3.0になりスムーズにpipできるようになりました。)

基本的な使い方(irisデータとbostonデータを用いて
1.まずは必要なライブラリをインポートします。ここではirisデータの分類を取り上げます。データセットはpycaret.datasetsのget_data内に格納されています。
import pandas as pd # pandasモジュールをインポート
from pycaret.datasets import get_data # PyCaretのデータセットを取得する関数をインポート
from pycaret.classification import * # PyCaretのclassificationモジュールをインポート2.データセットを読み込みます。
data = get_data('iris') # PyCaretからIrisデータセットを読み込む
3.setup関数でトレーニング環境を初期化します。この関数は、データとターゲットという2つの必須パラメータです。ここで必要な前処理を行っています。
exp = setup(data=data, target='Class', session_id=123)
# data:データセット, target:予測対象のカラム名(class), session_id:再現性のためのランダムシード
4.モデルを比較します。
compare_models()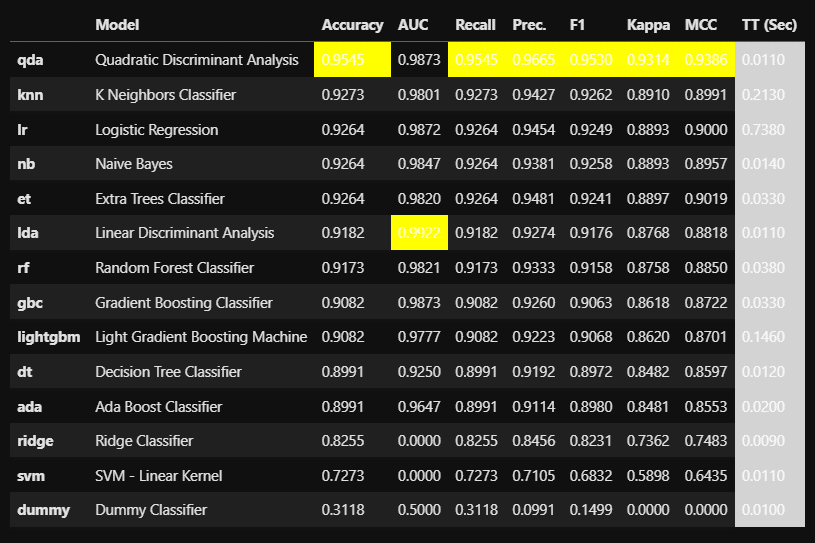
5.モデルを選択し、ハイパーパラメータチューニングを行います。(実行環境によっては少し時間がかかります)
ここではrf(random forest)を選択し、パラメータ探索回数(n_iter)を50としました。(デフォルトは10)また、otimizeには最適化する指標を指定します。ここではAccuracyとしました。
tuned_model = tune_model(create_model('rf'), n_iter=50, optimize='Accuracy')
# ランダムフォレストモデルをチューニング
6.モデルを評価します。
evaluate_model(tuned_model)

7.未知のデータに対して予測を行います。
train_data, test_data = data.sample(frac=0.8, random_state=123), data.drop(data.sample(frac=0.8, random_state=123).index)
predictions = predict_model(tuned_model, data=test_data)8.モデルを保存します。
save_model(tuned_model, 'random_forest_regression_model')モデルは.pklデータで保存され、保存ディレクトリも表示されます。
回帰タスクも同様の表記で記載できます。
回帰の場合はインポートの際にpycaret.regressionから全てをインポートしてください。
# 必要なライブラリをインポート
import pandas as pd
from pycaret.datasets import get_data
from pycaret.regression import *
# データセットを読み込む
data = get_data('boston')
# PyCaretの環境を設定する
exp = setup(data=data, target='medv', session_id=123)
# モデルを比較する
compare_models()
# モデルを選択し、チューニングを行う
tuned_model = tune_model(create_model('rf'), n_iter=50, optimize='R2')
# モデルを評価する
evaluate_model(tuned_model)
# 未知のデータに対して予測を行う
train_data, test_data = data.sample(frac=0.8, random_state=123), data.drop(data.sample(frac=0.8, random_state=123).index)
predictions = predict_model(tuned_model, data=test_data)
# モデルを保存する
save_model(tuned_model, 'random_forest_regression_model')
このように分類でも回帰でも同じようなコードで一連の流れを記載することができます。
Bitcoinの将来価格予測に挑戦
ここではより実践的なタスクとして、ビットコインの過去のデータを取得し、将来の価格を予測するスクリプトを記述します。
import yfinance as yf
import pandas as pd
from pycaret.regression import *
from ta import add_all_ta_features
from ta.utils import dropna
# ビットコインの価格データを取得(BTC-USD)
ticker = "BTC-USD"
start_date = "2020-01-01"
end_date = "2023-03-01"
# yfinanceを使ってデータを取得
btc_data = yf.download(ticker, start=start_date, end=end_date)
# 結果をデータフレームに変換
btc_df = pd.DataFrame(btc_data)
btc_df.reset_index(inplace=True)
# テクニカル指標を計算し、特徴量として追加する
btc_df_ta = add_all_ta_features(
btc_df, open="Open", high="High", low="Low", close="Close", volume="Volume", fillna=True)
# 価格変化率を計算し、特徴量として追加する
btc_df_ta['price_change_rate'] = btc_df_ta['Close'].pct_change()
btc_df_ta.fillna(0, inplace=True)
# PyCaretの環境を設定する
# 'Close' を予測対象とする
exp = setup(data=btc_df_ta, target='Close', session_id=123)
# モデルを比較する
compare_models()
# モデルを選択し、チューニングを行う
tuned_model = tune_model(create_model('rf'), n_iter=50, optimize='R2')
# モデルを評価する
evaluate_model(tuned_model)
# 元のデータセットから最後の30行を抽出
btc_df_tail = btc_df_ta.tail(30)
# 新しいデータを取得し、元のデータセットの最後の部分と連結する
end_date_new = "2023-03-25"
btc_data_new = yf.download(ticker, start=end_date, end=end_date_new)
btc_df_new = pd.DataFrame(btc_data_new)
btc_df_new.reset_index(inplace=True)
btc_df_concat = pd.concat([btc_df_tail, btc_df_new], ignore_index=True)
# 連結したデータセットでテクニカル指標を計算する
btc_df_new_ta = add_all_ta_features(
btc_df_concat, open="Open", high="High", low="Low", close="Close", volume="Volume", fillna=True
)
btc_df_new_ta['price_change_rate'] = btc_df_new_ta['Close'].pct_change()
btc_df_new_ta.fillna(0, inplace=True)
# 予測に使用する部分のみ抽出
btc_df_new_ta = btc_df_new_ta.tail(len(btc_df_new))
# 将来価格を予測する。
predictions = predict_model(tuned_model, data=btc_df_new_ta)
# モデルを保存する
save_model(tuned_model, 'bitcoin_price_regression_model')スクリプトの内容を簡単に説明します
1.必要なライブラリをインポートします。
yfinance: Yahoo Financeから株価や暗号通貨価格データをダウンロードするために使用されます。
pycaret.regression: PyCaretの回帰モジュールで、回帰タスクに関連する機能が含まれています。
ta: テクニカル指標を計算するためのライブラリです。
2.ビットコインの価格データを取得します。
yf.download()を使用して、指定された期間のビットコインの価格データをダウンロードした後、データフレームに変換し、インデックスをリセットします。
3.pd.DataFrame()を使用して、ダウンロードしたデータをデータフレーム形式に変換した後、reset_index()を使って、データフレームのインデックスをリセットします。
4.テクニカル指標を計算し、特徴量として追加します。
add_all_ta_features()を使用して、テクニカル指標を計算し、データフレームに追加します。
5.価格変化率を計算し、特徴量として追加します。
pct_change()を使用して、価格変化率を計算し、データフレームに追加します。fillna()を使用して、欠損値を0で埋めます。
ここまでが前処理で、ビットコインデータの整備と特徴量の追加を行いました。ここからは先ほどまでとほとんど同じです。
6.PyCaretの環境を設定します。
setup()を使用して、データフレームと予測対象(この場合はClose)を指定し、PyCaretの環境を設定します。
7.モデルを比較します。
compare_models()を使用して、PyCaretが提供するさまざまな回帰モデルを比較し、性能を評価します。
8.モデルを選択し、チューニングを行います。
create_model()を使用して、特定のモデル(この場合はランダムフォレスト)を作成し、tune_model()を使用してハイパーパラメータチューニングを行います。
9.モデルを評価します。
evaluate_model()を使用して、チューニングされたモデルの性能を評価します。
10.未知のデータに対して予測を行います。
predict_model()を使用して、新しいデータ(data_new)に対して価格予測を行います。予測用のdfを新たに作成しています。
11.save_model()を使用して、トレーニング済みのモデルをファイルに保存します。
このほかにスタッキングやバギングなどの応用的な活用も可能で簡単にモデルの比較、ハイパーパラメータチューニングができるのでぜひ一度使ってみてください。
この記事が気に入ったらサポートをしてみませんか?