
画像生成AIの仕組みとAIアートの闇

はじめに
AIによる画像生成の仕組みについて、まったく分かっておられない方が多く、過剰な万能性を期待したり、空想的なイメージを裏切られて実態に勝手に失望したり批判する姿が多く見られました。そこで啓蒙のために画像生成AIの仕組みについて簡単に説明したいと思います。専門家ではないので間違っている部分も多々あると思いますし、そもそも全部説明できる訳ではないので簡略化されたものだと思ってください。
画像生成の仕組み
画像生成の仕組みは単純に言えば、画像認識AIの入力側と出力側を逆転させた仕組みです。見た画像から何が描かれているかテキストで表示する仕組みを逆転させれば、テキストからその言葉で表される画像を表示するという仕組みになるのは分かると思います。その表示する際に”覚えている画像のどれか”ではなく、”覚えている画像の特徴を合わせた新しい画像”を作って表示する事で、この世に存在しないものをテキストに書いても作る事が可能になります。
多くの人が勘違いしていますが、AIの生成した画像は学習データ内の画像をパッチワークしたもの、コラージュしたものではありません。あくまで、生成画像がお題に似ているかどうかを測る為の採点者として一部分に関わっているだけなのです。
基本の流れ
初めにAIに渡されるテキスト、いわゆる呪文と呼ばれるPromptから学習データを検索します。学習データはタグと画像で一組になったデータセットと言う形で収録されています。ここでPromptの内容に近いタグを持つデータセットから画像を受け取ります。これらを採点者として生成した画像と自身が似ているか採点する試験を行い、合格点が得られるまで改変をします。こういった事を繰り返す事で最終的に多くの採点者たちにある程度似た画像が作られます。
※分かりやすさの為にタグと称してます。
StableDiffusionでは更にPromptから選ばれた採点者の画像だけでなく、その採点者に似た、Promptで選ばれない画像も採点者にしています。この能力で、データセット内のちゃんとタグの設定されていない画像を採点者として有効なものに出来るのです。
※GuidanceScaleがこれを左右させる数値設定だと思います。違うかも。

ニューラルネットワーク
大まかな画像生成の流れが分かった所で次は大まかな構造を紹介します。リニアな試験の流れでは生成される画像は1パターンになってしまいます。そのため、実際には様々な画像が生まれるよう採点者が異なる試験を分岐しながら進めていきます。この構造が人間の神経網を模す事からニューラルネットワークと呼ばれます。

AIの分からないもの
おそらく、この2つの図を見れば誰でも「そりゃ覚えているものと同じような画像が作れるだろ!」と思うはずです。ですが、この図で既にAIが人間と致命的に異なる点も分かるはずです。AIはリンゴという物体を分かっていません。
現状の画像生成AIは物体そのものを認識してはいません。例えばリンゴと言われた時に生成される画像は、学習データの中のリンゴのタグが付いた画像で多く共通している部分でしかありません。リンゴの写真で背景が果樹園だったり、キッチンだったり、テーブルの上だったりするから背景が定まらず、共通する部分のリンゴだけが残る仕組みです。
つまり、AIは構造や機能、関係など一切分かっていません。未熟なリンゴも腐ったリンゴもそういう物体の画像で知っているだけであり、未熟なリンゴが熟してリンゴになり、時間が経つとリンゴが腐ってしまうという事は知りません。リンゴを切ると中身が露出してリンゴの断面が現れるという事も知りません、リンゴの断面を知っているだけです。リンゴの種を植えると芽が出て、リンゴの木になり、リンゴが実るなんて当然、分かっていません、すべて別のものを覚えているだけです。そもそも背景と物体とも分かっていません、共通しやすい部分とそうでない部分でしか無いです。AIにとってはすべてが画像上の模様と言っても過言ではありません。
当然、二次元の画像とテキストしか存在しない世界で考えているAIが、時間変化のある三次元空間で起きる物理的な挙動を想像する事は出来ません。人間ですらそれを理解するのに、それそのものを見るだけではなく文章という言語情報を必要とするのですから。
区別の付かないAI
もし、AIの学習データの中のリンゴの画像の多くが、果樹園を背景にしていたらどうなるでしょうか。AIは背景の果樹園も共通部分の為、リンゴとして果樹園にあるリンゴを生成する事になってしまいます。
実際にStableDiffusionにCosplayというPromptを渡すと展示会か公園にいる女性の写真が作られます。これは学習データのコスプレ写真の多くが展示会か公園を背景にコスプレをしている女性だから、それをコスプレと認識しているという事なのです。
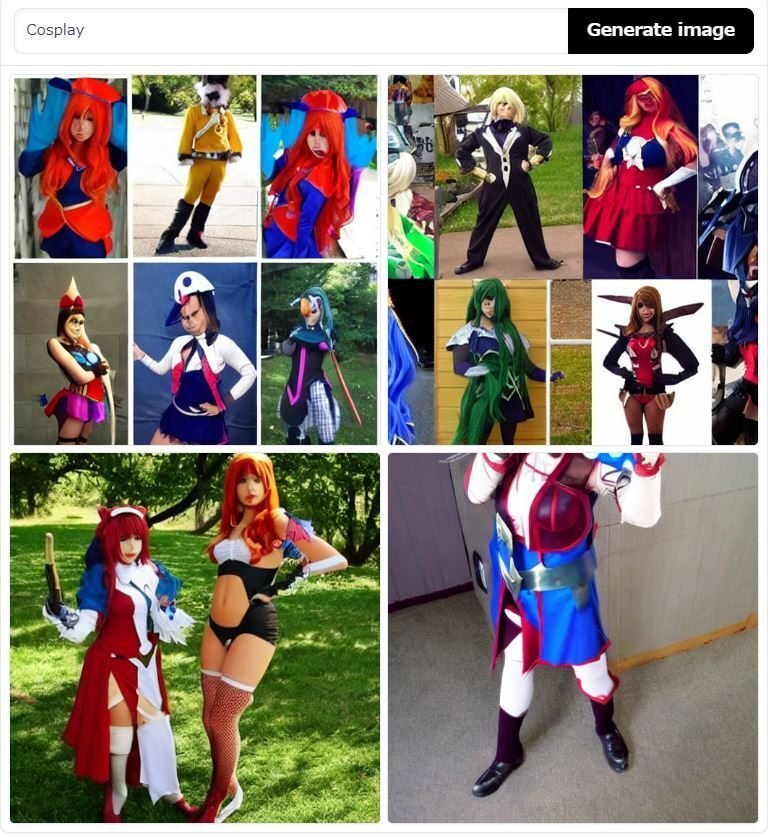
一見、人間がコスプレと言えば女性で、会場と言えば普通は展示会か公園だよねの感覚と似ていると思うかもしれませんが、我々はコスプレが行為で女性が実行者で背景が展示会か公園と区別出来ていますから、実は全然違うのです。
区別のさせ方
しかし、AIの学習データにはたくさんの画像があります。つまり、”キッチンでコスプレする男性”というPromptを渡されれば、学習データ上の”男性”の画像の中から”キッチンにいる男性の写真”、コスプレの画像の中から”男性のコスプレ写真”の共通部分を合わせる事で、共通しない部分の”キッチン以外”と”コスプレする女性”が消え、”キッチンでコスプレする男性の写真”を生成する事ができます。

こういった余計な関連性を使用者は考慮しないといけません。
例えばイヌ頭のスーツの男(Dog Head on Man Neck in Suit)ではイヌと男の関連性が弱いため、スーツ姿のイヌ人間になりますが、イヌ頭のスーツ姿のジョン・ウィック(Dog Head on John Wick Neck in Suit)では、ジョン・ウィックについてイヌと一緒に写る写真が学習されているので、ジョン・ウィックとイヌが分かれる画像が現れてしまいます。
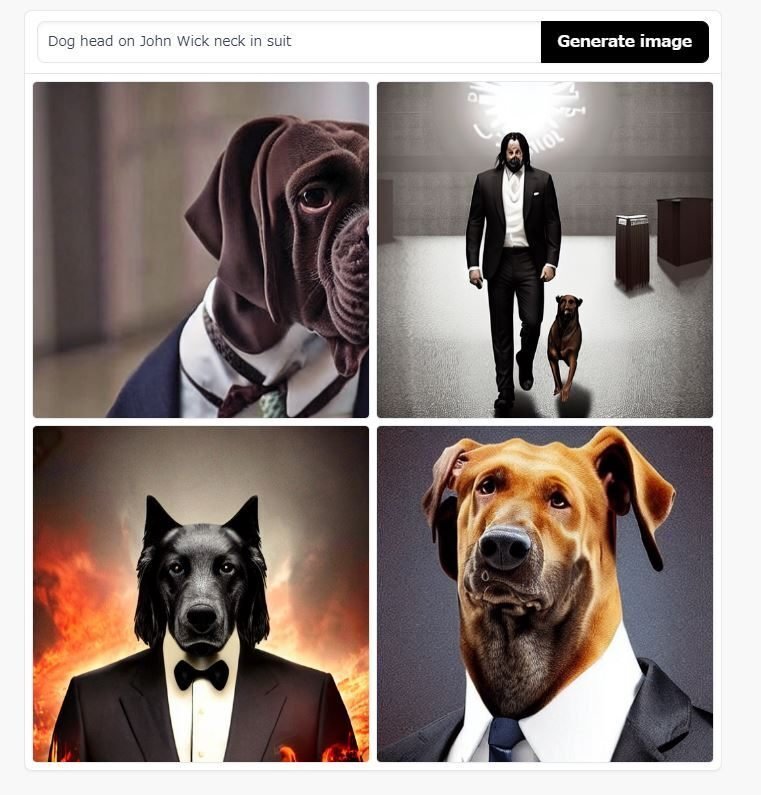
ここまでものが分からないにも関わらず、AIはテキストに従ってそう見えるものを生成する事が出来るのです。それがAIのすごい所なのです。
キャラの顔が苦手な理由
キャラクターの顔が苦手な理由はたくさんあります。第一に実際の人間の顔よりも多様性に富む事があります。例えアニメキャラの目と一言に言っても大きなものから小さなものもまでたくさんあります。共通部分を正解とする仕組みですから、採点者がバラバラでは正解が定まりません。当然、構造や構成を知っている訳でもないので瞳や白目、ハイライトを別々のものとして組み合わせることも出来ません。そのため、簡単に崩れてしまいます。
※でもStableDiffusionは写真っぽい人間の顔も割りとすぐ崩れます。
同じような顔の描き方なので、AIには
人間のキャラクターとそうでないキャラクターの区別は付かない。
もともと人間には他の物体の認知に使う機能に加えて更に顔認知特化の機能があります。いわゆるシミュラクラ現象と呼ばれるものはその敏感さの現れで、失顔症なんて障がいはその顔特化認知機能へのダメージの現れなのです。※おそらく
AIによる顔認証システムなんてのはそれに近い仕組みで、目鼻口の存在が予めプラグラムされた上で学習しています。デジカメやスマホのカメラでの撮影時に何もない所を顔と誤認する時は、人間でいうところのシミュラクラ現象状態の場合もあるでしょう。
StableDiffusionの学習データ上のイラストの数は人間的な目で見れば豊富ですが、写真や芸術作品と比べれば多いとは言えないでしょう。また、画像と英語のテキストのデータセットという都合上、英語の伴う海外のイラストの方が詳細なテキストを伴った有効性の高い画像となっていて、おそらく日本のイラストの有効性が低くなっている気がします。
また、原因の一つには英語の目に関する語彙の少なさもあるのではとも思っています。日本のイラストに対して英語のテキストが用意されていたとしても言葉として表現の難しいものが多々あります。日本語では一般的なツリ目やジト目、タレ目と言ったものは英語ではしっかりと定まった言葉がなく、アニメキャラの目に関して細かいテキストが組み合わされていないため、英語で考える以上AIがブレてしまう気がします。このようなキャラクターデザインに対する日本語の造語の多様性に追いつかない部分は目以外にもあります。もし、日本語のデータセットやアニメキャラ専用のデータセットを作るならばこの問題は解決されるかもしれません。
実際、中国製画像生成AIであるERNIE-ViLGはデータセットの数が1億4500万とStableDiffusionやMidjourneyに比べて1桁少ないにも関わらずアニメイラストが得意です。元々アニメキャラの顔が得意なGANという仕組みを使っている事もありますが、数が大きく違うのですからデータセット自体にも大きな違いがありあそうです。
AIとプログラムの(一般的な)違い
さて、実際に画像生成AIを動かした方はお気づきでしょうが、AIは間違えます。ミスをします。指示に対して完璧ではありません。そして、それがプログラムとの違いです。
プログラムは間違えない代わりに、知らない問題には回答できません。想定外の処理は行えません。出来ませんとエラーを吐くか、何も起きません。一方でAIは知らない答えであっても、知っている情報(データ)から自ら考えて回答する事が出来ます。それが人工”知能”たるところです。そして、それは完璧ではなく、むしろ、間違ってもいいから答える事が出来るのが特徴なのです。
(まとめ)AIの賢さとは
かなりざっくりした説明ですが、画像生成AIの基本的な仕組みとAIが考慮できない情報については説明しました。これだけの情報が無いにも関わらず、ものが分かり、写実的でも絵画的でも画像が生成出来るのがAIのすごさです。そしてそれは、コンピュータの演算速度と優れたアルゴリズムによって人間とは比べ物にならない回数考える事が出来る為です。言ってしまえば現状のAIの賢さと言うのは、質ではなく量で攻めている賢さなのです。
現状のAIの賢さと言うのは、一般的に考えられるようなスマートさではなく、単純な考え方を人間とは段違いの速さで行える事で、短い時間の間に莫大な回数繰り返す事が出来るという事です。
人間のお絵描きをどこまで再現したか
人間との比較
画像生成AIの生成した画像を見て驚いた人たちがシンギュラリティ!と騒いでいましたが、AIの画像生成がどれほど人間のお絵描きを再現しているのか、AIの持つ機能と情報、人間の持つ機能と情報を並べてプロセスを図化して簡単に比較してみました。
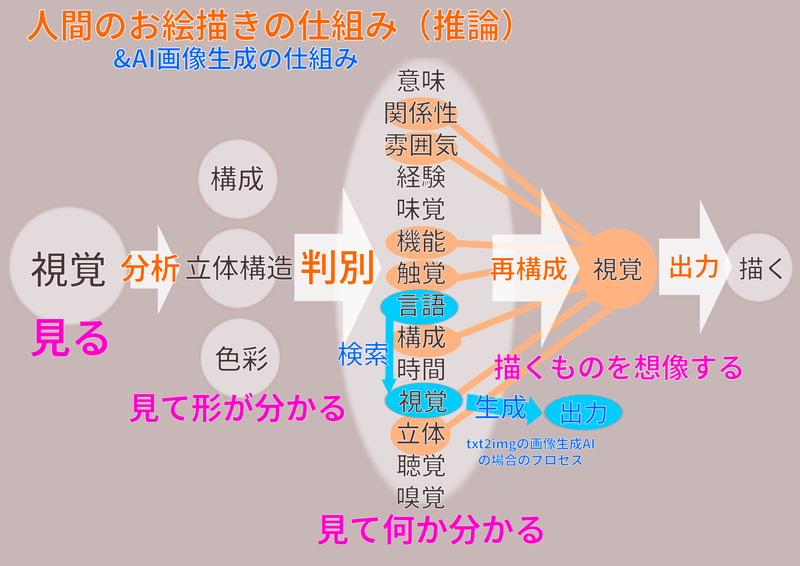
実際には言語も人間のような”意味”を理解していないので、別物の単なる識別パターンに近い。
図化してみるとあまりに再現していません。何故ならAIは静止画とテキストのデータセットしか持たず、そこから分からない事は学習出来ないからです。仕組みで説明したようにそれ以外は知りません。時間や空間、立体構造、機能、パーツの構成、他の概念との関係性・・・etc、静止画とテキストでは分からないものは分かりません。
この画像生成AIは上の図で示す、ものを見て何か(覚えている別の画像のものと同じ被写体か)を判別するAI(実用化され生活に浸透している画像認証AI)の流れを逆転させたようなものです。同様に画像生成も人間のお絵かきのプロセスよりも、人間の視覚認知の仕組みを逆転させたものの方が近いかもしれません。
我々人間はものを見る時、まず静止画で見ておらず、時間的に連続した視覚情報、動画のような形態で観察しています。そして、そこに自身の移動や手足の接触を伴うことで、同時に立体としての形状の変化も把握しています。現状のAIにはそんな機能はありません。また、物体についてもAI同様にどの名称がどの物体を指すのかという事は静止画的に理解しているケースは少ないと思います。我々が知らない物体の名称を伝える時は指を指したり、直接持って動かすなどどこからどこまでがソレかを伝え、判断するのに様々なアプローチが出来るからです。
しかし、人間と比較してあまりに多くの情報が無いにも関わらず、人間が驚くような画像が生成できてしまう。立体も空間も時間も何も分かってないにも関わらず写実的なものを生成できてしまう。それが人間よりも多くのものを精確に記憶し、早くたくさん考える事が出来るAIのすごさなのです。
絵心の無い絵はまだ描けない
某トークの絵心のない人の絵はまだ、AIには描けません。厳密にはああいう絵を生成させようとしない限り自然に生成できません。何故ならあの絵はAIには無い静止画の視覚情報以外の情報から作られた絵なのです。

絵の下手な人の絵には共通した特徴があります。それは識別に使う抽出された特徴以外を汎用的な情報で補完している所、顔が正面を向きやすい所、数上の部品構成を現実の視覚的な状態よりも優先する所です。
抽出された特徴は物体そのものを識別している故であり、写実性が失われるほど高度に記号化する事はAIには出来ません。AIはそれを実例の視覚情報を得る事で擬似的に再現しています。逆に、この特徴以外の情報を欠損させる事が絵心の無い絵へ大きく変貌させています。
顔が正面を向くのは人間の認知機能が顔に特化している故であり、生物的な個を強調した擬人化だと考えています。これがデフォームに満たずコラージュ的になり、人面化するのも絵心の無い絵と呼ばれる一因になるでしょう。
そして視覚情報しか持たいないAIにまったく不可能な部品構成の表現は絵をコミュニケーションツールとして情報伝達に使う人間ならではと言えます。AIは指の本数が分かりませんが、絵心のない人間はどんな状態でも指の本数や手足の数に執着します。(時にはしないものもありますが、AIのように最初から分からないわけではありません。)これは姿勢によって視覚的に見え隠れするものでも実際の数は増減せず、構成は変わらないから、識別上すべて見えている状態を伝えるという事を優先しているからでしょう。
結果的にわずかに残った特徴と基本的な構成を曖昧な線で補完しつなげた軟体的な構造や立体に破綻を起こした下手な絵であっても、見た人間は下手くそな”何か”と分かる事が多いのです。コミュニケーションを優先したこの絵はある意味文字的です。
今後、物体の構成や機能を学習する能力を持った画像生成AIが現れれば、こういった人間的な破綻した構成的に正しい画像の生成も再現されると思います。
※私の推論
でたらめはやれない
AIが人間に及ばない最大の点は、何か分からないものを描く事、知らないものを描く事は出来ないというところです。AIにPromptを渡す事で実在しない光景を描かせる事は出来ますが、PromptにAIの知らない言葉が入っていた場合、似た言葉のものと処理されたり、スルーされます。知ってる言葉で出来た実在しない光景を再現するだけです。何を描くか言語と視覚で分かっていないと描けません。
しかし、人間はそうではありません。人間は気分で筆を動かし、感情的に表現できます。それは言語的に表せないものや視覚的に分からない形態になる事もあります。何を描いたのか分からないものを描く事が出来るのです。AIには出来ません。意味のない線や気分で色塗る事もありません。人間の表現に対して、今のAIの生成画像はPromptに対する受け身でしか無いのです。
それでもこんなに人間にとって見れるものになってしまうと言うのが今のAIの凄い所なんです。
AIアートの闇
イラスト無断使用img2imgの危険
StableDiffusionにはテキストから画像を生成するtxt2img以外の機能もあります。それがimg2img機能です。これは簡単なイラストを渡すとテキストと合わせて画像を生成する仕組みです。
もし、これで他人のイラストを無断で使用して作品を作られた場合、作者が見てもその作品が自分の作品を使ったものと分からない可能性が高いです。しかし、この仕組でAIに渡す画像は学習データとして使われるものではなく、下絵として使われる為、加筆、編集された画像と見做される可能性が十分にあります。また、下絵とPrompt次第で理論上は全身画でも風景でもどんなイラスト形式の画像でも生成する事が可能です。SNSアイコンに使える程度の顔アップしか描けないMimicに比べれば、出力できる画像の汎用性は遥かに高いものです。

逆に写真からイラストへも加工が出来る為、写真も無断使用される可能性がある。
この機能でも構図や塗りなどがある程度出来ている画像の方が最終的な生成画像も良い出来になりやすく、絵の描けない人間が自分で描かずに、他人の絵を無断で利用する事は大きな利益になります。他人のラフ画を勝手に仕上げた画像にするという人も出てきてもおかしくありません。悪意が無くとも、好きな漫画の1コマを抜き取ってAIにイラストにしてもらうぐらいの事は自然に行われるでしょう。生成された画像が個人利用の範疇であれば問題ないでしょうが、これを販売したりすれば犯罪になる可能性は大きいです。
また、この機能で生成される画像は下絵にされるイラストと一緒に使用されたPromptとSeed値があれば誰でも生成できるものです。つまり、そこに無断使用した人間の独創性は含まれず、誰がやっても同じ結果が得られるほど再現性も高いものです。単純に変換しただけと言っても良いでしょう。そのため、本来のイラストの作者にも生成する事が出来たもの、本来のイラストの作者が得られるはずだった利益と考えられる可能性もあるかもしれません。ここらへんは法律の専門家に聞かないとわからないですが・・・
この機能で生成される画像の大きさに制限はなく、本人に見られても気づかれにくいものとなれば、生成した画像を販売して大きな利益を得ることは十分に可能です。
成り済ましは相手にダメージを与える為の行動なので大きな損害となれば自ずと判明しますが、この方法は作者の知らない所で、作品を利用して、作者が得られるはずだった利益を勝手に盗むことが出来るのです。法的にはイラストを勝手にグッズ化してお金を稼ぐのと同じになるでしょう。

何故、この危険性を危惧するイラストレーターがほとんどおらず、企業に管理され、第三者も監視可能で、ログが残り、本人にも分かる形態でアイコン程度の顔イラストしか生成できないようなMimicが槍玉に挙げられたのか、私にはよく分かりません。
野犬が野に放たれたのにも関わらず、鎖に繋がれたチワワをタコ殴りにしたようなものです。野犬がそのチワワを産む事が出来るにも関わらず。
著作権が守るものと守らないもの
著作権が守るものは作品で得られる作者の利益です。人間の場合においても絵柄を模倣した作品が著作権の侵害ではないように、AIにおいても絵柄を真似された別の画像も著作権の侵害になりません。前述のようにコラージュする訳ではないので、真似される作品は画像自体に含まれない仕組みだからです。
なりすましは模倣作品を伴ってもそれ自体は著作権の侵害ではなく、名誉毀損や詐欺と言った事で犯罪行為になります。そして、それは作品ではなく、人間の問題です。
オマケ:Mimicの仕組み(推測)
Mimicの仕組みですが、画像生成AIの仕組みについての項目を読んである前提で説明します。
これは基本を単純に言うと、画像生成の後半の採点者となる画像に絵柄を真似して欲しい15枚を差し込む、優先度を高めて混ぜる仕組みだと思います。顔イラスト風画像生成AIであるWaifuLabsを知っている方は想像がつくと思いますが、これの操作で絵柄を決めていく手順を、手動ではなく参照する15枚を元に自動化したようなものだと思います。
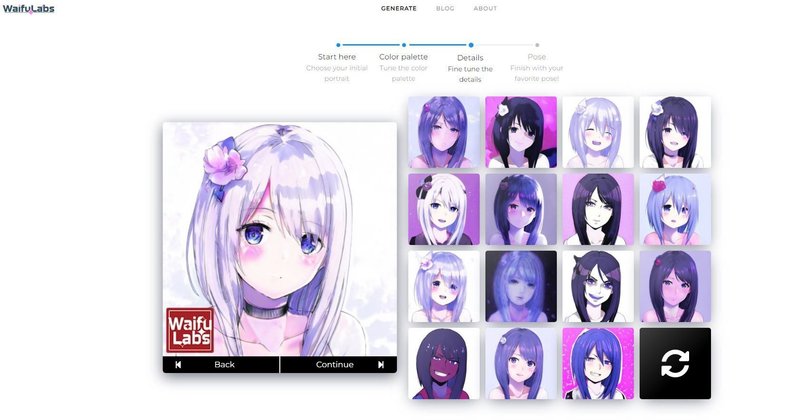
WaifuLabsでもそうですが、絵柄の元になる画像をコラージュしたり、パッチワークして生成していません。そして、十分に絵柄は変わります。WaifuLabsでは、この手順のあとに顔の向きや表情も変わります。それぐらいの応用が出来る既存の仕組みです。
つまり、一部の方が日本製の優れた画像生成AIうんたら~と擁護していましたが、実際にはこのパートを15枚の画像ベースにしただけのようなもので、画像生成AIとしてのエポックメイキングな機能は何もない、新しいサービスであって、新しい技術ではなかったと思います。
Mimicに関しては多くの否定者や肯定者が技術を分からないあまり、現実離れをした過剰な評価をしていたと思います。そして、その結果は特に意味のないものでした。オープンソースの画像生成AIが公開された以上、知識のある誰かが本当に同じようなものを作ることは可能です。次もMimicのように、公に見える場所で、利用者を制限し、国内の法律に則って、ログの残し、言葉の通じる相手とは限りません。
前々段の鎖に繋がれたチワワと野犬の例えはこういう意味です。
AIは道具である
AIはあくまで道具で使用する人間次第で、武器にも筆にもなるものだと思います。少なくとも現状の画像生成AIは人間のお絵描きのプロセスのほとんどを再現できていませんから、人間に取って替わるなんて不可能な状態です。
しかし、人間がお絵かきのために使う事には大きな利点があります。構造や構成、空間的な情報を下絵に描いてimg2imgで渡せばAIの足りない情報(構造や構成等)を補ってより人間のイラストに近い画像を出力しますし、それを人間がリタッチすればより優れたものになります。AIの得意とする写実的な風景ならじっくり見る風景画は無理とも、主役の添え物としての背景であればそのままでも割りと平気です。
AIと人間が競争したらいつか抜かれるかもしれませんが、実際には人間がAIを使うのですから、AIの進んだ分だけ人も進みます。AIが良い絵のような画像を出力出来たなら、それを芸術に昇華させるのも人間の手あってだと思います。
能力差は埋められたか?
正直な話、AIの登場は絵の描けない人と描ける人の差を更に大きくしただけのように感じています。前述している通りAIには足りない情報が多くあり、それを補えるimg2img機能は絵を描けない人間が不利です。他人の絵を無断利用しない場合、AIは絵の描ける人間の絵をより上手くし、絵の描けない人間には生成ガチャを強いるだけです。絵の描ける人間はAIの画像をリタッチ出来ますが、絵の描けない人間は当たりが出るまでAIを動かし続けるだけです。
絵が描ければ描けるだけ☆4の画像や☆3の画像を☆5のイラストに限界突破出来るのに、絵が描けない人はガチャで出るまで☆5は手に入らないので・・・。
この記事が気に入ったらサポートをしてみませんか?