3.スイス銀行紙幣データ:LSD研究の重要なBGSを見つけた

自己紹介
1971年から種々の判別データで4つの問題を見つけ、3つの事実で最小誤分類数基準の最適線形判別関数のRIPを開発し。そして4種の普通の線形分離可能データ(LSD)と169の高次元のMicroarayがLSDである事を世界で初めて実証研究で示した。そして3冊のSpringerから出版し、革新的な判別理論の骨子を分かり安く説明する。
139文字
心電図診断、癌の疫学データ、30万例の丸山ワクチンとCPDデータ、大学入試センター試験の13教科データの判別研究。介護保険に分類木を用いることをアドバイス。2015年に正規分布を基礎とする判別理論の間違いを示す本[1]を出版。その技術で、簡単に169のMicroarrayデータが沢山の多変量の小変数のLSD(線形分離可能)に分割できることを示した[2]。2023年に6種の普通のデータを4つのProgramで再分析し、組み合わせ最適化技術で「ケースの選択法」と「変数選択法」という新しい判別分析の世界を切り開く革新的なTheory3を完成した。
誤分類のある医学診断、癌の遺伝子データ解析、試験問題の評価などの世界初の方法論の驚く結果を、4Programの結果で分かり易く紹介した世界初のLSDの判別理論を24年3月14に刊行する[3]。2024年からは視力の問題で、長くPCで実証研究ができないので、53年間の研究をやめることにした。そしてNOTE等で、筆者の開発した技術を日本で紹介普及したい。上記の3テーマのExcelデータがあれば、公開を原則として内容を見て分析したい。特に医学診断データを最優先としたい。単なる知識の習得で満足するのでなく、多くの人が身の回りのデータから有益な情報をえる「真のData Scientist」になってほしい。AIに無条件に迎合せず、組合わせ最適な解が得られるデータ解析との比較する視点をもってほしい。623
140
1971年から、大阪成人病センターで心電図診断と癌の疫学データを判別分析で研究。日本医科大学の30万例の丸山ワクチンとCPDデータの診断法を重回帰と判別で解決。3年間の大学入試センター試験の13教科データと筆者の統計入門の中間と期末の10択100問のデータの判別。介護保険に分類木を用いることをアドバイス。2015年に正規分布を基礎とする判別理論の間違いを示す本[1]を出版。その技術で、簡単に169のMicroarrayデータが沢山の多変量の小変数のLSD(線形分離可能)に分割できることを示した[2]。2023年に6種の普通のデータを4つのProgramで再分析し、組み合わせ最適化技術で「ケースの選択法」と「変数選択法」という新しい判別分析の世界を切り開く革新的なTheory3を完成した。誤分類のある医学診断、癌の遺伝子データ解析、試験問題の評価などの世界初の方法論の驚く結果を、4Programの結果で分かり易く紹介した世界初のLSDの判別理論を24年3月14に刊行する[3]。2024年からは視力の問題で、長くPCで実証研究ができないので、53年間の研究をやめることにした。そしてNOTE等で、筆者の開発した技術を日本で紹介普及したい。上記の3テーマのExcelデータがあれば、公開を原則として内容を見て分析したい。特に医学診断データを最優先としたい。単なる知識の習得で満足するのでなく、多くの人が身の回りのデータから有益な情報をえる「真のData Scientist」になってほしい。AIに無条件に迎合せず、組合わせ最適な解が得られるデータ解析との比較する視点をもってほしい。
目次
自己紹介
3.1 スイス銀行紙幣データ:LSD研究の重要なBGSを見つけた
3.2 大学院の落第で企業人へ
3.3 世界初のLSD研究
3.4 スイス銀行データの1組の2変量のBGSの役割
3.5 全ての判別データをLSDにする革新的なケース選択法
3.1 スイス銀行紙幣データ:LSD研究の重要なBGSを見つけた
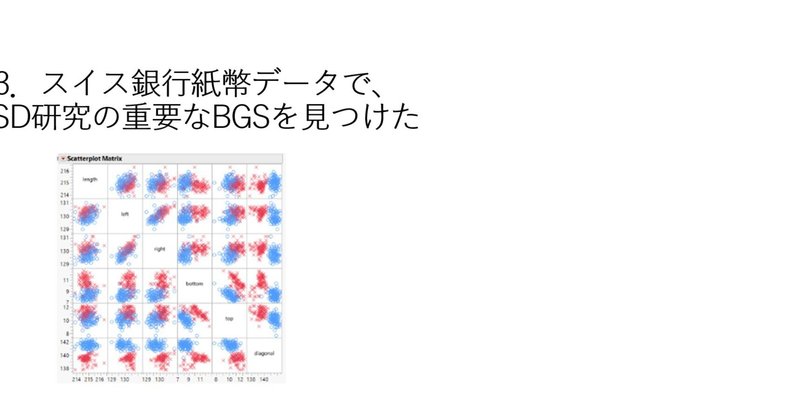
スイス銀行紙幣データ(200*6)は、各100枚の真札と偽札の6変数の左右の縦と横と対角線の長さのデータである。ドイツの統計学者のFluryとRieduyl (1989)が、プロジェクターで研究室の壁に拡大して計測し、判別分析の解説書に用いたデータである。筆者のようにFisherのIrisデータで物足りなさを感じて、「学生のアンケートデータ(40*6)」で、SAS、SPSS、StatisticaとJMPの解説書を書いたスタイルが似ていて日本語訳を読んでみた。最初の50頁は面白く読めたが、後は役に立たない著者の判別理論の紹介である。そしてこのデータの重要な2変数のX4とX6が、「最小次元のLSDである1組の二変量のBGS(Basic Gene Set)」になることを誰も見つけていない。
タイトル画像に、このデータの6変数の2群の行列散布図を示す。筆者の日科技連から出版した「最適線形判別関数(2010)」の竹内啓先生の書評で「何となく僕もLSDでないかと思っていた」に見るように、一部の研究者は漠然とLSDと疑っていたようだ。また竹内先生は、「統計研究者は栽培植物や経済学のように実際の応用分野を想定して研究する必要がある」という貴重な警句を残している。
3.2 大学院の落第で企業人へ
筆者は1971年に複素関数論で大学院を受けて断られ、10月に便宜上NECの大学院生の採用試験を受けさせられ白紙回答で採用され、できたばかりの住商情報システム(株)(現SCSK)に特別な役員面接で「優が少ない」と言われながら採用された。京大のプールに戻って優の意味を聞くと、経済学部の先輩部員から「評価は優良可で決まり、優が何個以上だと住友銀行や関西電力に入社できる」といわれ驚いた。数学科の評価は教員バラバラの評価で、点数、合否、その他雑多である。私の個人的なグループで、成績の話をする人間がいなかった。内2人は、九大と埼玉大学から同志社の教授になっている。
そこでSCSに断りに行くと、「優が少ない」といった伊庭貞剛の孫のNECから出向した津田直次専務に「君のような学生が秀才きらめくNECに入っても芽が出ない。情報処理産業がこれからの産業だ」と言われ、私がNECに断ってやると言われた。ナマ返事をしたが、断りの電話を聞かされ入社することにした。32人の新採用は、関西の有名私大が多い一期生である。仕事がないので10月まで新人研究があった。私は6月の初旬に大阪NEC出向になり、NECと大阪成人病センターの野村循環器医長の間で「心電図の自動解析診断システム」の開発に参加した。そして1月ほど数冊の心電図の専門書などを読んだ後、統計を使ってECGの診断論理の研究テーマを与えられた。そこで東大出版の「計量診断学(高橋編著)」を読み、多変量解析を修得することにした。この当時は、計量診断学、計量経済など統計の一次ブームで、人に注目すればData Scientistの走りである。ちなみに筆者は、オバマ大統領に先駆けて、「使いやすい最高品質の統計ソフトで現実のデータ解析を、MPソフトで数式で表される現象の分析を行う問題解決学を教育の基本にすべき」と統計とOR学会で主張したが受け入れられなかった。しかし米国でData Scientistが注目され、これまで筆者の意見に見向きもしなかった研究者が我先に紹介し始めた。
そして大阪科学技術センター主催の統計セミナーに参加した。講師は浅野先生(九大教授)、後藤先生(阪大教授)等の塩野義、田中先生(岡山大学)などである。彼らは日本初の統計システムNISANの開発を行っている。これらに北大の佐藤教授や水田教授らが加わり、日本統計学会(JSCS)を立ち上げた。私は日本にSASの計算センターを作り、SASの普及に務めた。実はSASの代理店契約の約束を取り付けたが担当の役員から1年ほど充分に検討するようにと言われた。Assist(株)のビル・トッテン社長と手を組みSAS社に乗り込んだが、日商岩井の子会社に先を越された。そこで、書籍や論文などで紹介普及することに努めた。企業において統計やMPを習得するためには、代理店として自分の食い扶持を得る必要があった。
浅野先生から「君のおかげで、製薬メーカーにNISANを売り込んでいたが悉く失敗した」といわれていたが、JSCSの発起人になるように言われ参加した。
3.3 世界初のLSD研究
空間の2群の対象あるいはデータがLSDであることは、科学技術上の重要な基本概念である。1985年以降に行われたMicroarrayのデータ解析の研究(Theory1)でも、ファッションとしてLSDの用語がある論文があるが、誰も真剣に取り組んでいない(判別分析のProblem2)。筆者が169のMicroarrayのデータ解析で簡単にLSDであることを示した。さらにそれらの横長データ(n<p)が、n個以下のLSDであるType-1のSMとBGSに排他的に分割できる。そして、高次元の横長のLSDは、その中にロジスティック回帰のDF遺伝子の組み(DF分割:Stracture1)とRIPのSM(SM分割:Stracture2)からBGS(BGS分割:Stracture4)までMatryoshka人形のように入れ子構造をもっているというデータ構造(Stracture1)を見つけた研究者は誰もいない。これは、統計や機械学習やAI等の研究者が、MPと統計ソフトの両方を自由に操る真のData Scientistでなければ、結果が出せないことを示す。
彼らは研究の初期で、高次元データ解析の3つの困難の言い訳のバズワードが論文で指摘した。
1) 高次元のデータ解析の手法がない。
2) 高次元の変数選択(Feature Selection:FS)はNPハードであり難しい。
3) 高次元の雑音に埋没した信号を見つけるのは困難である。
これらは困難でなく単なる無能の言い訳である。次の点に問題がある。
1) 横長データ(n<p)は、高校数学の「連立方定式の解」はp変数からn変数を選んで(n*n)の逆行列で計算できる。高校数学の基礎も自分の研究に生かせなかった。
2) LDF、重回帰、PCAは、p変数からn変数を選んだデータで計算できる。データ分析しておれば自然に体得できる。
3) Theory1のFact1は、誤分類数のNMとLDFの判別係数の関係を表す。誤分類数のNMは0から(n-1)のN個の整数値しかとらない。これは判別理論が正規分布でなく、「組み合わせ最適化の問題」として扱うことを示す。
4) 高次元の2群が正規分布であるような現実のデータには、出逢ったことがない。現実のデータを無視して、都合の良い理論分布の安易な判別理論で失敗に気づかなかった。さらに、LSDの研究はIPの最適化組合わせ技術がいる。
以上の事実を知らない理工学研究者が世界中に多いのは理工学研究最大の不祥事で、教育を見直す必要がある。この指摘が正しいことは、筆者が169のMicroarrayでFact3を見受けたことが正しさを裏付ける。一方、試験の合否判定ができない事は、面白くないとか判別分析する必要が無いテーマと言われ無視された。」
すなわち横長データのLSDの分析は、簡単にn個以下の小標本のLSDに分割でき容易である。これ迄開発されたFSはLSDには全く役に立たない。RIPで判別するだけでSMやBGSのLSDが求まり、効率的な変数選択ができる。
また山中教授は、3万以上の人の遺伝子から、遺伝子DBでラットのES細胞で活性化する24個の遺伝子を見つけた。そして24個で万能細胞の塊ができた。これはSMの発見と同じで、「高次元からLSDであるあるいは万能細胞ができる」という多変量の特性を持った変数の組が選択できた。169のMicroarrayでSMとBGSという「多くの多変量の癌遺伝子の候補」を見つけた。そして残りわずか1組か数組のLSDでないSMとBGSがある。発現量は信号の塊で、LSDでない雑音はほんの僅かである。ただし多くの多変量の癌遺伝子の候補から真に役立つ多変量の癌遺伝子は少ないと考えられる。彼らの信号と雑音の定義が示されていない。
3.4 スイス銀行データの1組の2変量のBGSの役割
各100枚の真札と偽札の6変数のデータには63(=26-1)組の6変数の組み合わせの判別モデルがある。Program1 でできるRIP、改定LP‐OLDF,H-SVM、S-SVMと、JMPでできるLDF,QDF、RDA(正則化判別関数)とロジスティック回帰で63モデルのNMの比較を行った。これから計算される100重CV(Method1:Program2)の100組の検証標本の平均ERが最小(M2)のモデルをBestモデルとして選ぶためである。そして、RIPが最善で、LDFが最悪であることを確かめた。
それ以上に、2変数の(X4,X6)が最小次元のLSDでBGSになる。このBGSを含むモデルは、残りの4変数の組み合わせの16(=24)組ありLSDになり判別に有効な信号である。残りの47モデルはMNMが1以上の雑音であり、判別には必要ないことが分かる。
Program2でRIPの63モデルのM2を今回Springer3で評価して昇順に並べ替えて驚いた。LSDの16モデルの範囲は[0%, 0.4%]で、残りの47の雑音モデルは[0.5%, 21.55%]である。そしてBGSだけが、16モデル中の最小の2変数の最小モデルで、M2=0%と判別成績の最も良い最善のモデルである。
統計モデルの良しあしを決める基準として、私が20代のころはスコラ哲学に起源のある「オッカムのカミソリ(けちの原理)」が統計書に記述してあった。しかし最近では、この具体例がないので自然消滅し若い人は知らないと考える。Program4で簡単にBGSが得られる。これほど見事で美しいOccam’s Razorの具体例はない。RIPの判別が、63モデルから2変数のBGSを選ぶので、他の理工学研究の開発した変数選択法は不要である。これがTheory3で開発した「新しい革新的な27の技術の中かで重要なRevolution25」である。全部で27の革新的な知識や技術を見つけた。
3.5 全ての判別データをLSDにする革新的なケース選択法
4回目は、Program1のRIPで判別すると帝王切開患者と自然分娩患者の2例が誤判別される。この2例を省いた238例の19変数を持つ児頭骨盤不均衡のCPD238は必ずLSDになる。これは全ての判別データをLSDにする革新的なケース選択法のRevolution24である。そして判別理論の全く新しい世界を開く福音になる。考えてみてほしい。この後、54万以上(=219-1)の判別モデルから、Occam’s Razorを満たすBGSが簡単に求まる。これはRIPでデータに一意に決まる誤分類例を特定できたから可能になる。判別分析の真の目的は、「2例の誤分類例の詳細を医師が検討すること」が可能になる。
この意見に賛同する読者は、日本中の医師にこの記事を拡散し、医学診断の質を上げることに協力してほしい。過去に行った医学診断のExcelの研究データがあれば、筆者が分析することも可能である。3万以上の遺伝子から最適なLSDになるBGSを見つけることは、AIではできない。これは個人が唯一AIより優れた結果が出せる組み合わせ最適技術の筆者の開発した4つのLINGOのProgramで可能になる。
ChatGptに、簡単な(3*10)のデータから、LDF、重回帰、決定木などの判別結果を求めた。国家資格試験などの正解率の高さが宣伝されている。しかし銀行紙幣データのような普通のデータであっても、LSDの結果は出せない。もし将来出せたとしたら、筆者の研究成果を引用しただけである。
即ち現時点では、MPを含んだデータ解析も、個人の努力がAIに勝るテーマである!!!!
この記事が気に入ったらサポートをしてみませんか?