
複数のアングルを生成する画像生成AIの利用(1)

0. はじめに
shi3zさんの「無料作画AIサービスMemeplexの使い方」のnoteに複数のアングルを生成できるZero123+が紹介されており、Huggingface でも利用可能なようなので試してみました。
(私のレベルで使えるようになれば、Memeplexでも試してみたいと思ってます( ̄∀ ̄))
1. 条件
「Memeplexの利用(2) AIモデル依存性」で検討した(記事投稿現在)全17種類のAIモデルで生成した画像のうち、各AIモデルの「画像(1)」をZero123+(Huggingface)のinputとして与えて、複数のアングルからの画像を生成しました。
2023年10月29日現在のHuggingfaceでは、Advanced optionをいくつか設定できますが、今回はdefaultの設定:
・Input Image Processing: Background Removal
・Classifier Free Guidance Scale: 4
・Number of Diffusion Inference Steps : 75
・Seed : 42
で行いました。
この設定で実行すると、原画と同じアングルからの画像を含めて、合計7種類の画像が新規に生成されました。
2. 17種類のAIモデルの画像から生成した複数のアングルの画像
2.1. 結果1:StableDiffusion_v2.0

2.2. 結果2:StableDiffusion_v1.5/Inpainting

2.3. 結果3:BraV5

2.4. 結果4:SDHK
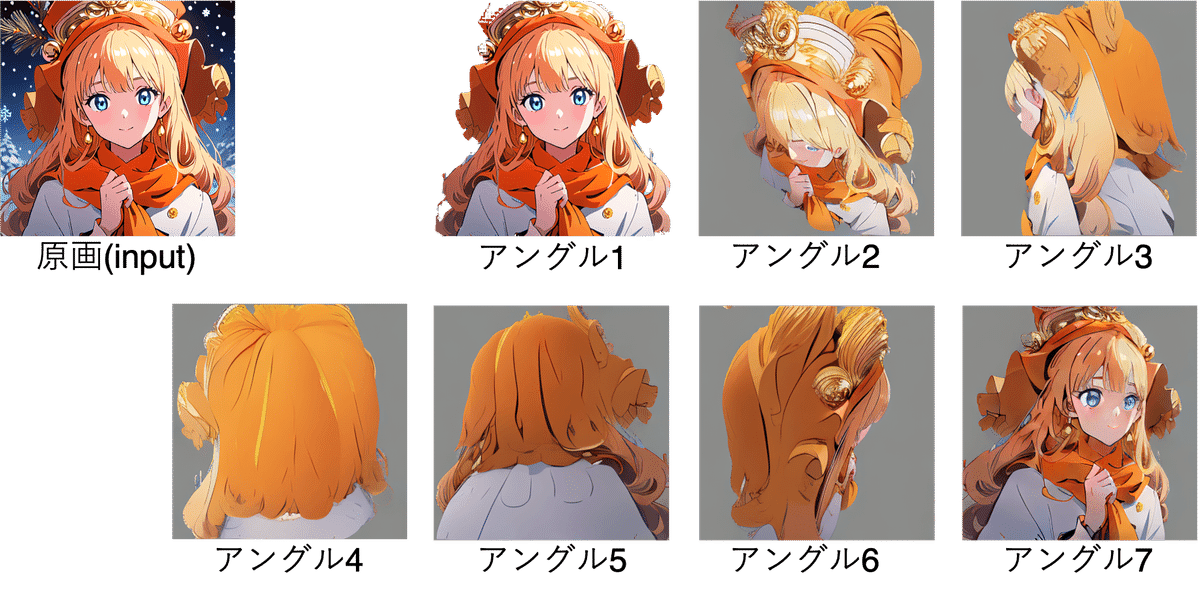
2.5. 結果5:Counterfeit-v2

2.6. 結果6:OpenJourney-v4

2.7. 結果7:Protogen_v5_Official_Release

2.8. 結果8:mitsua-diffusion

2.9. 結果9:vintedois-diffusion-v0-1

2.10. 結果10:trinart

2.11. 結果11:WaifuDiffusiion1.2

2.12. 結果12:Redshift

2.13. 結果13:photorealistic-fuen-v1

2.14. 結果14:StableDiffusion-Depth

2.15. 結果15:OpenJourney2

2.16. 結果16:Muse_v1

2.17. 結果17:SDXL1.0

3. 考察
各AIモデルにおける各アングルからの画像より、アングル1で原画から「人物」として認識された領域に応じて他のアングルからの画像の精度が変化していることがわかります。
特に、左斜め下からのアングル7の画像で顕著な差が生じており、高品質な二次元的なイラスト(trinat、StableDiffusion-Depth、SDXL1.0など)では、顔全体が平面的に表現されているように感じます。
それに対して、高品質な三次元的なイラスト(Muse_v1やRedshift)では、アングル7の画像は立体的に表現されているように感じます。
(ソースコードの詳細は存じ上げませんが…)Zero123+もDiffusionモデルのようなので、今回の結果は、偶然、三次元的なイラストの方が他のアングルからの画像を綺麗に生成できた可能性があります。
この点については、私のレベルでMemeplexのZero123+を利用できるようになってから詳しく検証してみようと思います。
最後に、7種類のアングルの画像サイズの平均値のAIモデル依存性をFigure 1に示します。
HuggingfaceのZero123+で生成した画像は全てpng形式で出力されますが、入力画像がpng形式のサイズの大きな画像を入力すると、jpeg形式の画像を入力するよりもやや大きなサイズの画像が出力されることがわかります。
これも、7枚の画像データの平均値で、統計誤差の可能性がありますので、Zero123+がMemeplexで使えるようになったときに再度調査してみようと思います。
