
Kohya LoRA Trainer Dreambooth v14.6の使い方、学習方法解説

バージョン違いにご注意ください
この解説ページの解説はバージョン14.6です。
現在のバージョンはv15.0.0です。
最新バージョンの解説を書きました。
加筆箇所
前説項目の画像トリミング説明にエラーの原因となるZIP保存方法が書かれていたため修正しました。
5.4. Training Configでエラーになる場合がありそうな設定上の注意を追記しました。
前説
学習にあたって
ここでは正則化画像なしのLora学習方法を解説します。使うのはKohya LoRA Trainer Dreambooth v14.6です。超初心者でもわかります。
正則化画像がないと学習させたモデルが、呼出しトークンを使わなくても出てきてしまいますが、学習精度が上がり短時間で学習できるメリットもあります。そもそもLoraは適用させた時はその学習内容を出したい時なので、今回は正則化画像なしのLora学習方法を解説します。
画像収集
学習させたい画像を30枚ほど収集します。なるべく解像度の高いものを集めてください。学習させたい物が人物の場合、髪型、ポーズ、背景、服装をなるべくバラバラにしてください。例えば全部の画像に東京タワーが写ってると、東京タワーもその人物と認識して学習してしまいます。
画像収集には『画像ダウンローダー』というGoogle Chromeブラウザーのアドオンが便利です。
画像トリミング
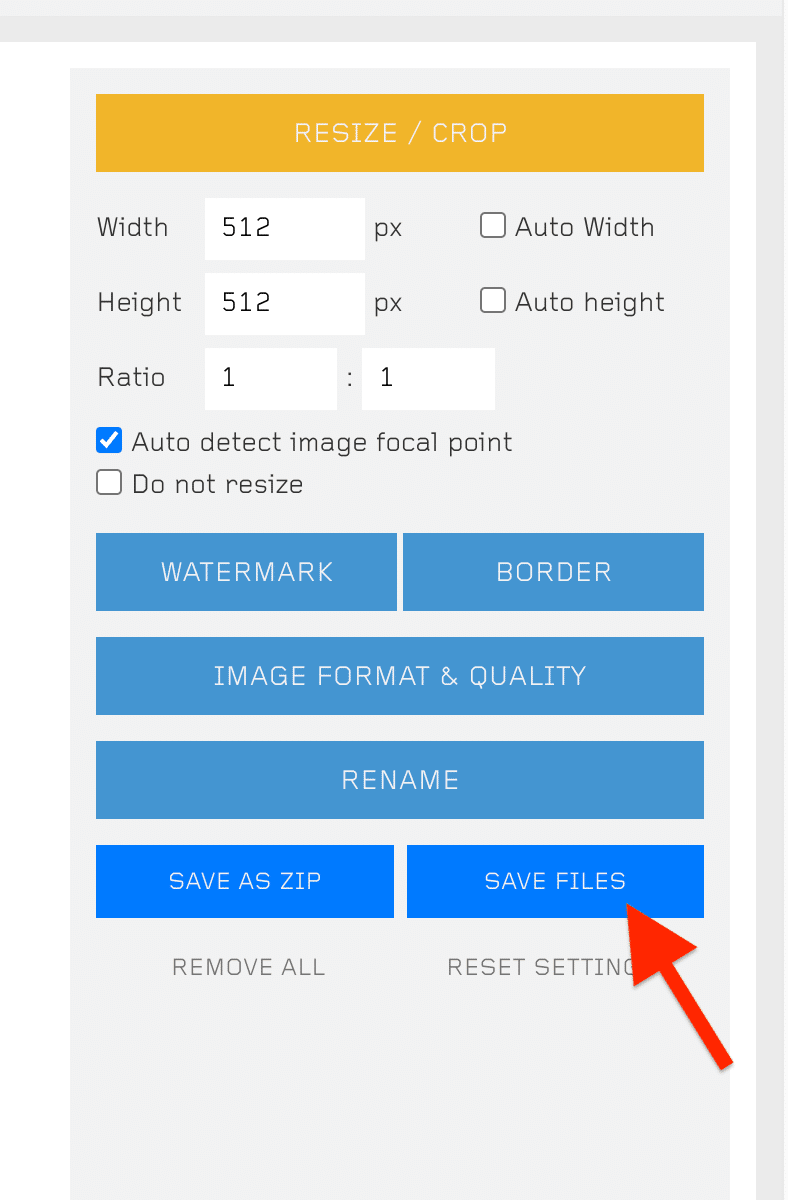
用意した画像を1024x1024の正方形にトリミングし、一つのフォルダーに入れてZIPに圧縮します。Macはキャッシュファイルごと圧縮してしまう仕様で学習時にエラーが出てしまうので注意が必要です。サードパーティのアプリ等を使ってZIPにしてください。
birme.netというサイトを使うと直感的にトリミングできます。
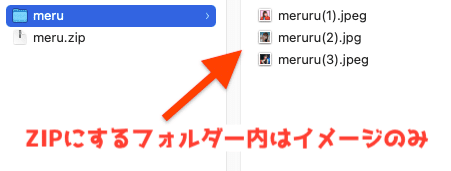
ZIPでダウンロードできるので便利ですが、ZIP/フォルダー/イメージとなってしまうので、SAVE FILESの方で画像を保存し、手動でZIPにして下さい。
グーグルドライブへアップロード
用意したZIPをグーグルドライブへアップロードしておきます。
解説開始
Colabで開く
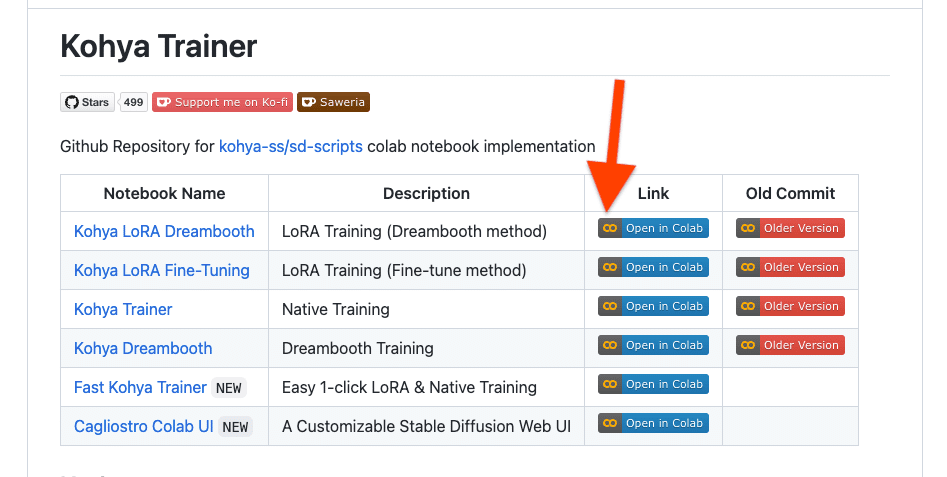
URLへアクセスしColabで読み込む
https://github.com/Linaqruf/kohya-trainer.git へアクセスしKohya LoRA DreamboothのOpen in Colabリンクをクリック
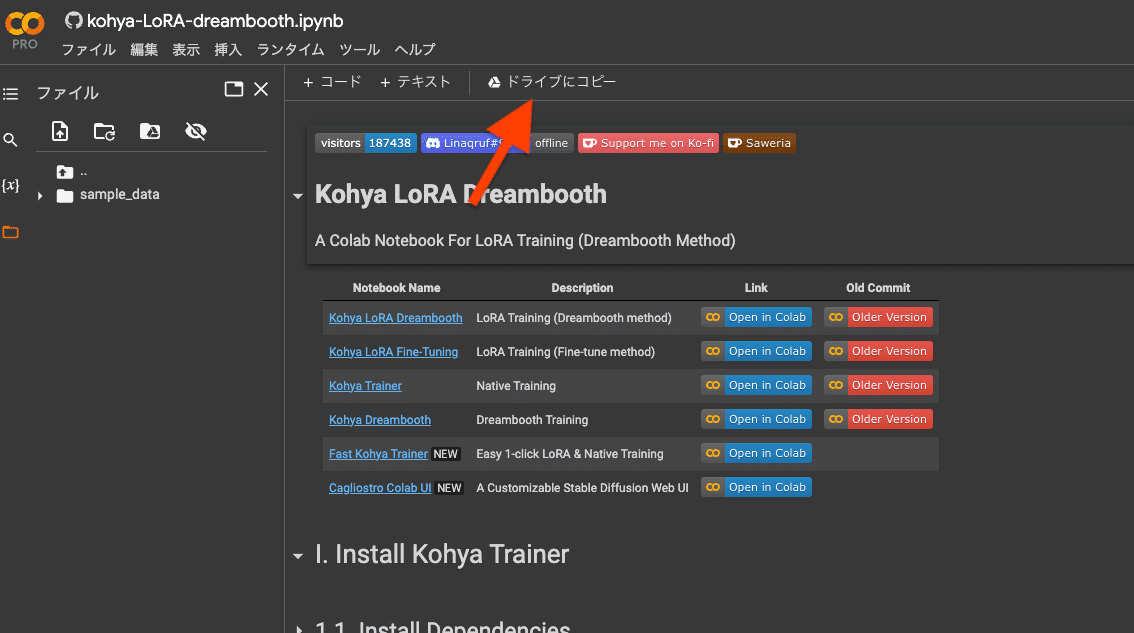
ドライブへコピーをクリック
I. Install Kohya Trainer項目解説
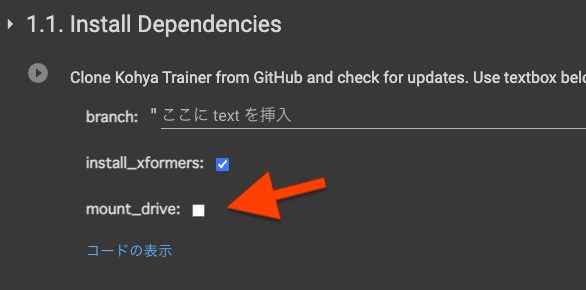
1.1. Install Dependencies
mount_driveの項目にチェックを入れます。これでGoogleドライブと連携されます。
1.2. Open Special File Explorer for Colab (Optional)
実行しません
II. Pretrained Model Selection項目解説
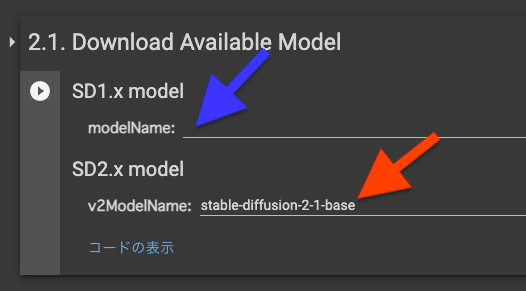
2.1. Download Available Model
ベースとなるモデルを選択します。
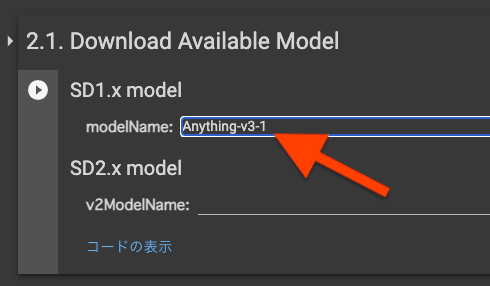
Stable Diffusion1.5を選択します。もしくは人間などを学習させる場合Stable Diffusion1.5、アニメを学習させる場合anythingなどという選び方もあります。しかし、多くの人はStable Diffusion1.5で学習させているのでStable Diffusion1.5を使うのが無難です。
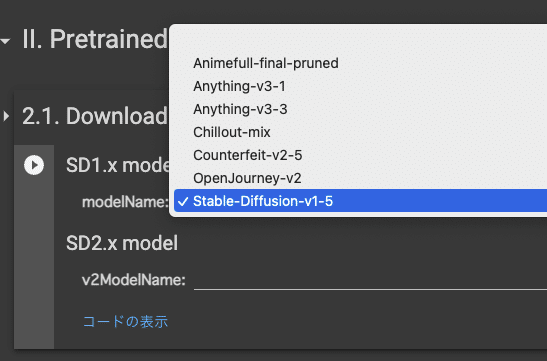
Stable Diffusion2.0系統を使いたい場合は上の段を空白にして、下の段で選択します。
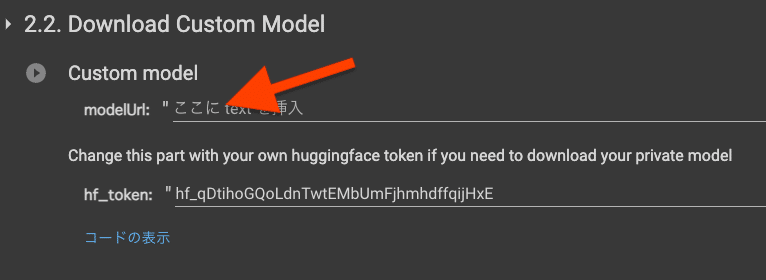
2.2. Download Custom Model
2.1を実行した人は不要の項目です。その他のモデルを使いたい人はこちらでURLを指定して実行します。
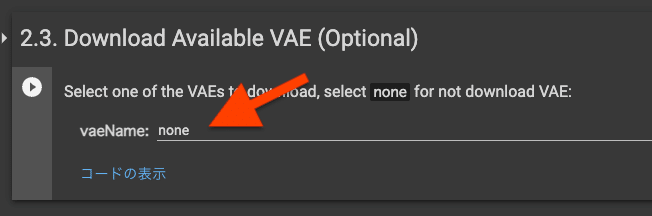
2.3. Download Available VAE (Optional)
実行しません。VAEをミックスさせたい人は実行させてもいいですが、Loraモデルの出来栄えを考慮すると実行しない方が無難です。
ここから先は
¥ 480
この記事が気に入ったらチップで応援してみませんか?