
Lora学習で繰り返し数(dataset_repeats)をいじっても意味はない

繰り返し数(dataset_repeats)とは
これを勘違いしている人が多いです。デフォルトが10だか20だったりするのが原因かもしれません。
繰り返し数という名前も原因かもしれません。
『学習画像増幅倍数』と言った方が正確な気がします。
繰り返し数(dataset_repeats)とは、正則化画像や複数概念の学習時に使用される学習画像数の差を埋めるためのものです。
例えば、学習画像が10枚で正則化画像が100枚ある場合、学習画像の繰り返し数を10として100枚として扱います。
同様に、学習素材Aの学習画像が10枚、学習素材Bの学習画像が50枚の場合、学習素材Aの繰り返し数を5としてバランスを取ります。
パソコン上で学習画像を複製して10倍、100倍に増やすのと同じ行為です。それが大変だから自動で行っているだけです。
そうしないと学習素材Bの方が強く学習されてしまうからです。
つまり、単体学習や正則化画像を使用しない場合は、繰り返し数を1にします。
実質の学習画像数 = 用意した学習画像数 × 繰り返し数(dataset_repeats)
と考えればわかりやすいでしょう。
そして、下記で説明しますが、学習全体の繰り返し数を決めるのはエポック数です。
単体学習や正則化画像を使用しない場合は繰り返し数を1にしてエポック数のみを気にした方が学習の進捗を把握しやすくなります。
エポック数と繰り返し数の違い
どちらも同じ繰り返しとして書かれていることがありますが、対象が違います。
エポック数は学習全体を繰り返す回数を指し、繰り返し数(dataset_repeats)は各学習素材に対する繰り返し数(一番始めに書いたように正確には学習画像を増幅させる倍数)を表します。
そして、処理の順番としては繰り返し数(dataset_repeats)で学習画像を強制的に増やした後、エポック数で繰り返します。
学習の進捗はステップ数で決まる
学習の進捗はステップ数で決まります。
ステップ数 = 学習画像数 × 繰り返し数 × エポック数 × バッチ数 ÷ バッチ数
つまり
ステップ数 = 学習画像数 × 繰り返し数 × エポック数
となります。
仮に学習画像5枚で繰り返し数20、エポック数1とした場合はその時点で100ステップとなります。
エポック数10だと1000ステップということです。
さてここで、あと少しだけ学習させたら良い感じになりそうだとして、どうしましょう?
先程も書いた通り、処理の順番は繰り返し数(dataset_repeats)で学習画像を強制的に増やした後、エポック数で繰り返します。
繰り返し数1ならば微調整が効きますが、繰り返し数が多いと微調整が難しくなります。
用意した学習画像が多ければなおさらです。
学習時間短縮にはならない
学習時間短縮で繰り返し数を増やしてエポック数を下げるというアプローチをする人もいるようですが無意味です。
同じステップ数に到達する時間は変わらず、学習時間の短縮にはなりません。
この画像は、上が「繰り返し数1、エポック数250」で、下が「繰り返し数10、エポック数25」のログです。完了の500ステップに達した時間はほぼ同じ33分です。


当然、学習結果もほぼ同じような結果です。上が「繰り返し数1、エポック数250」で、下が「繰り返し数10、エポック数25」です。


学習時間を短縮したい場合は
では学習画像、繰り返し数、エポック数を変えずに学習時間の短縮には何が必要なのかと言えばバッチ数です。
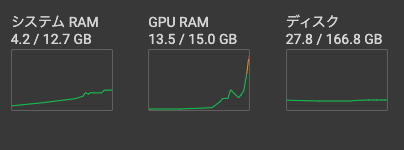
ただし、バッチ数を増やすとGPUの使用率も上がります。
そして、GPUの使用率が上がりすぎると学習が遅くなったり、学習損失が発生することがあるため無闇に増やすこともよくありません。
Google ColabではGPU使用率のグラフが出ますが、オレンジ色の後半や赤になるようならバッチ数を落とした方がいいです。
以上おわり
この記事が気に入ったらサポートをしてみませんか?