

性能比較のためにdocker-composeでMroonga(MySQL)のセットアップをしたら結構時間がかかった話

はじめに
こんにちは、SHIFT の開発部門に所属している Katayama です。
キャッシュの効果を体感してみる!~MySQLのクエリーキャッシュ~では MySQL のクエリーキャッシュについてみていき、キャッシュを使う事でクエリーの速度が速くなる事を確認してみました。そこで同じ速度向上という側面から、今度は MySQL における全文検索の性能比較をしてみる事にしました。
ところが、その性能比較をするための前準備で結構時間がかかったので、今回は docker-compose で Mroonga(MySQL)の環境をセットアップする方法についてみていきたいと思います。今回の Mroonga セットアップの話がどなたかのお役に立てれば幸いです。
Mroonga とは?
Mroonga とは?というのは公式に書かれているので、ここでは詳細を割愛するが、MySQL のプラグインとして利用できる全文検索を高速化するもの(以下、公式からの引用)。
Mroonga は MySQL 用のストレージエンジンです。すべての MySQL ユーザーに高速な日本語全文検索機能を提供します。Mroonga は以前は Groonga ストレージエンジンと呼ばれていました。
Mroonga 自体は MySQL のプラグインなので、実際に起動するサーバーとしては MySQL サーバーになる。
docker-compose で Mroonga(MySQL)のセットアップをする
セットアップとしては、以下の事を行う。
・プラグインとして Mroonga を利用できる MySQL サーバーを docker-compose で立ち上げる
・ストレージエンジンが Mroonga のテーブルを作成する
・速度を確かめるための大量のデータをテーブルに登録する
・クエリーの速度を確認できるようにするために Performance Schema を有効にする
以下で具体的にその内容を見ていく。
Mroonga を docker-compose で立ち上げる
Mroonga(MySQL)を立てるには docker-compose を利用する。
単に MySQL サーバーを docker-compose で立ち上げる方法は■docker-compose で MySQL Server を起動し操作するでやったように簡単にできる。ただ、Mroonga のプラグインが使える MySQL サーバを立ち上げる際に、以下のような事をやろうとすると少し工夫が必要になる。
① 自前の MySQL に対する設定を反映する("my.cnf"による設定)
② 初期化用の SQL で最初に起動した時にデータベースを構築する
③ データを永続化する
④mysql のターミナルで日本語を入力できるようにする
上記の 4 つ事が少なくともできるようにするために何が必要か?を 1 つずつ見ていく。
※④ については GUI ツール(NavicatやMySQL Workbenchなど)があれば不要になるが、ターミナルで SQL をサクッと実行したい時には必要になると思うので取り上げる。
Docker イメージからとりあえずサーバを起動してみる
まずは何も設定しないでプレーンな Mroonga プラグイン入りの MySQL を立ち上げてみる。
Mroonga のイメージはDocker Hubから手に入れられるのでこれ使う。docker-compose.yaml は以下のようになる(検証なので root ユーザで MySQL サーバーにログインし、その際のパスワードは省略できるように設定している)。
# docker-compose.yaml
version: "3.9"
services:
mroonga:
image: groonga/mroonga:mysql5734_mroonga1103
container_name: mroonga
environment:
MYSQL_ROOT_PASSWORD: ""
MYSQL_ALLOW_EMPTY_PASSWORD: "yes"
TZ: "Asia/Tokyo"
ports:
- 3306:3306
"docker-compose up"でサーバーを起動すると、ちゃんと起動している事が確かめられる。
[root@localhost learn-cache]# docker-compose up -d
Starting mroonga ... done
[root@localhost learn-cache]# docker exec -it mroonga mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)
...
mysql>
...
mysql> SELECT * FROM `test`;
+----+------+
| id | name |
+----+------+
| 1 | ??? |
+----+------+
1 row in set (0.00 sec)
ただ、今のままだと以下のように SQL でデータベース・テーブルを作成してデータを入れたとしてもサーバーを止めてしまえばそのデータベース・テーブル・データは消えてしまい面倒である。また、SELECT 文で日本語が文字化けしているのでこれも困る。そこで次の章では MySQL の設定を反映させ、データの永続化もできるように追加で設定していく。
①・③ の対応 データを永続化し MySQL の設定を反映させる
変更すべき部分としては多くはなく、新しく"volumes"を定義する事で対応ができる(この volumes については公式(日本語はここ)に詳しく書かれているが、永続的に保持する仕組みでやってくれる事としては Docker コンテナ内にホストマシンのファイルをマウントしたり、コンテナ内のファイルをホストマシンに保存したりする)。
この volumes を設定する事でコンテナ内にファイルをマウントできるので、それを利用して MySQL の設定("my.conf")をコンテナ内の MySQL サーバーに対して反映できる。さらに、MySQL のデータベースの情報(テーブル・データ)はホストマシン側に保存され、それが docker-compose で起動する際にコンテナにマウントされるので前回の作業時の状態から再開できるようになる。
# 省略
TZ: 'Asia/Tokyo'
volumes:
- ./data/mysql:/var/lib/mysql
- ./config/my.cnf:/etc/my.cnf
ports:
- 3306:3306
# my.conf
[mysqld]
character-set-server = utf8mb4
[client]
default-character-set = utf8mb4
実際にサーバーを起動してみると、データベース・テーブル・データが何もしなくても存在している事が確認できる。また、SELECT 文を実行した時に日本語が文字化けせずに表示できるようにもなっている。

続いて、上記の動画では MySQL Workbench を利用してデータを作成していたが、これは mysql のターミナルで日本語を入力しようとしても入力できないという事象があったため。そこで次の章では mysql のターミナルで日本語を入力できるように設定していく。
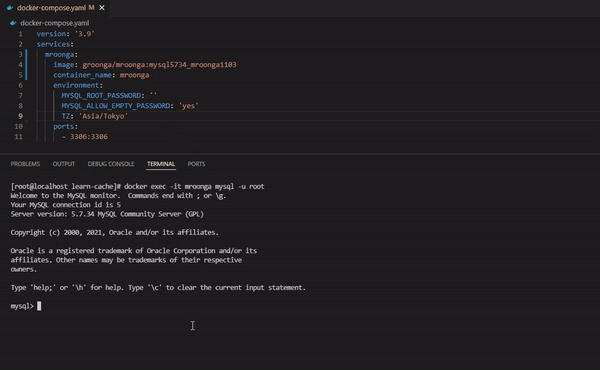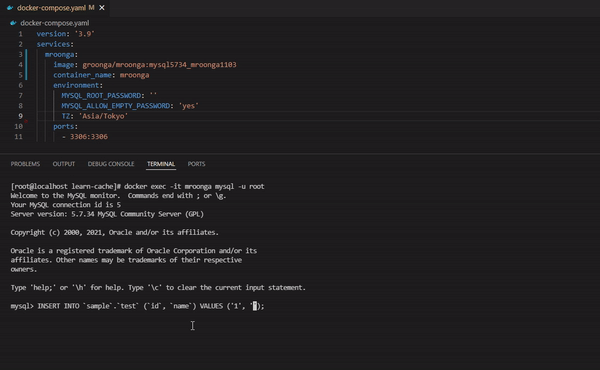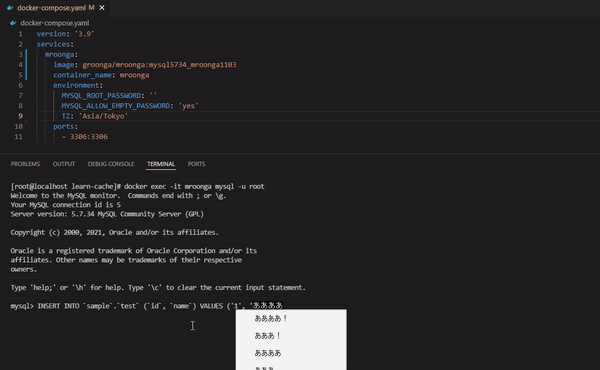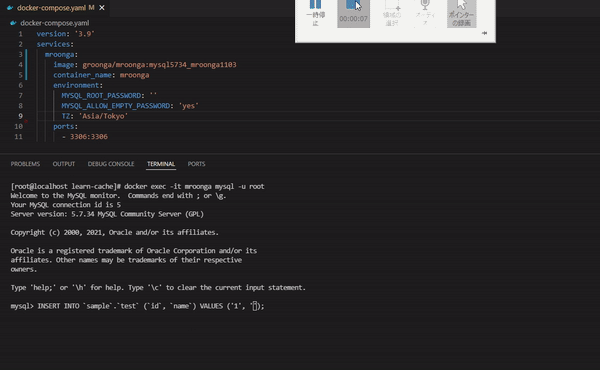
④ の対応 mysql のターミナルで日本語を入力できるようにする
そもそもなぜ mysql のターミナルで日本語が入力できないのか?だが、これは mroonga のイメージで起動したコンテナに問題があるため。具体的には、以下のように"locale"を出力してみても"ja_JP.utf8"がなく、日本語が使える状況にない状態になっている事が問題。
[root@localhost learn-cache]# docker exec -it mroonga locale
LANG=
LC_CTYPE="POSIX"
LC_NUMERIC="POSIX"
LC_TIME="POSIX"
LC_COLLATE="POSIX"
LC_MONETARY="POSIX"
LC_MESSAGES="POSIX"
LC_PAPER="POSIX"
LC_NAME="POSIX"
LC_ADDRESS="POSIX"
LC_TELEPHONE="POSIX"
LC_MEASUREMENT="POSIX"
LC_IDENTIFICATION="POSIX"
LC_ALL=
というわけで日本語も使えるように設定をすればいいという事になる。まずは mroonga のベースが何か?という話だがmysql5734_mroonga1103なのでcentos:7である事が分かる。
# mysql5734_mroonga1103のDockerfileより抜粋
FROM centos:7
MAINTAINER groonga
...
では CentOS(7.9)で locale の設定をすればいい!となるが、Docker なので"systemctl"同様に"localectl"コマンドは使えない(正確には"systemctl"は CentOS7.9 では工夫をすれば実行できる。それについてはDocker コンテナで systemctl を使うを参照)。
[root@localhost learn-cache]# docker exec -it mroonga localectl
Error response from daemon: Container 8f806a111044b73c1ad6aa62cc17823c52fa845a12d37ebebf01d28c8d7ce858 is not running
というわけで以下のように"mysql5734_mroonga1103"をベースにオリジナルでイメージを作成しそれでコンテナを起動するという手法を取る。具体的には、以下のような Dockerfile を作成し、docker-compose.yaml も修正する。
FROM groonga/mroonga:mysql5734_mroonga1103
RUN yum -y reinstall glibc-common; \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8;
ENV LANG="ja_JP.UTF-8" \
LANGUAGE="ja_JP:ja" \
LC_ALL="ja_JP.UTF-8"
version: "3.9"
services:
mroonga:
build:
context: ./build
dockerfile: Dockerfile
image: mymroonga:latest
container_name: mroonga
# 省略
上記について一部補足をする。
・"yum -y reinstall glibc-common;"
centos のイメージではデフォルトだと、"locale -a | grep -c ja_JP"でヒットするものがないので glibc-common パッケージを再インストールする事で、日本語の言語ファイルを落としてきて locale が設定できるようにしている
・"localedef -f UTF-8 -i ja_JP ja_JP.UTF-8;"
日本語ロケールの定義を追加している(詳細は公式を参照)
・"ENV LANG="ja_JP.UTF-8"~ LC_ALL="ja_JP.UTF-8""
環境変数として LANG・LANGUAGE・LC_ALL を設定している(この設定により日本語環境のコンテナができあがる)
・"build:"
ビルド(docker build)を実行する際に適用される設定を記述している。これを設定する事で Dockerfile の内容でイメージが作成されそのイメージでコンテナを起動する事ができる。ちなみに image が指定されている時はその名前で Docker イメージが作成される(詳細は公式(日本語はここ)を参照)。
あとは以下のように doecker-compose up でコンテナを起動すればよく、日本語が入力できるようになっている事が確認できる("locale -a | grep ja"で ja_JP.utf8 が存在する事が確認できる)。
[root@localhost learn-cache]# docker exec -it mroonga mysql -u root
...
mysql> INSERT INTO `sample`.`test` (`id`, `name`) VALUES ('1', 'あああ');
Query OK, 1 row affected (0.01 sec)
[root@localhost learn-cache]# docker exec -it mroonga locale -a | grep ja
ja_JP.utf8
[root@localhost learn-cache]# docker exec -it mroonga locale
LANG=ja_JP.UTF-8
LC_CTYPE="ja_JP.UTF-8"
LC_NUMERIC="ja_JP.UTF-8"
LC_TIME="ja_JP.UTF-8"
LC_COLLATE="ja_JP.UTF-8"
LC_MONETARY="ja_JP.UTF-8"
LC_MESSAGES="ja_JP.UTF-8"
LC_PAPER="ja_JP.UTF-8"
LC_NAME="ja_JP.UTF-8"
LC_ADDRESS="ja_JP.UTF-8"
LC_TELEPHONE="ja_JP.UTF-8"
LC_MEASUREMENT="ja_JP.UTF-8"
LC_IDENTIFICATION="ja_JP.UTF-8"
LC_ALL=ja_JP.UTF-8
最後に、初期化用の SQL で最初に起動した時にデータベースを構築できるようにする方法を見ていく。
・参考:CentOS 7 の mysql コマンドでの日本語入力
・参考:Dockerfile で日本語ロケールを設定する方法。およびロケールエラーの回避方法。
・参考:CentOS 7 コンテナに消えない日本語ロケールを追加する
② の対応 初期化用の SQL で最初に起動した時にデータベースを構築する
Docker Hub のMySQL のイメージであれば、"Initializing a fresh instance"に書かれているように、/docker-entrypoint-initdb.d 以下に初期化用の SQL をホストからマウントする事で、最初にコンテナを起動した時にデータベースの初期構築をしてくれる便利な機能があるが、これは MySQL の Docker イメージを作成する際にRUN mkdir /docker-entrypoint-initdb.dやdocker_process_init_files /docker-entrypoint-initdb.d/*が設定されているから。
今回利用している mroonga では特にそのような設定はないので自分でその設定を行う必要がある。とは言え MySQL の公式イメージでやっている事を真似すればいいので以下のように設定すればうまくいく(以下のシェルのベースはmysql5734_mroonga1103にある"entrypoint.sh"で、そこに初期 SQL を実行できるようにするためのコマンドを追記するようにしたもの。追記した部分だけを書いているので省略部分についてはmysql5734_mroonga1103にある"entrypoint.sh"を参照)。
# 省略
RUN mkdir /docker-entrypoint-initdb.d
COPY entrypoint.sh /root/entrypoint.sh
RUN chmod +x /root/entrypoint.sh
ENTRYPOINT ["/root/entrypoint.sh"]
#!/bin/bash
## 省略
if [ ! -e /var/lib/mysql/ibdata1 ] ; then
## 省略
mysql < /usr/share/mroonga/install.sql
## 追記ここから(docker-entrypoint-initdb.dの真似)
if [ -d /docker-entrypoint-initdb.d ]; then
for f in /docker-entrypoint-initdb.d/*.sql; do
if [[ -f $f ]]; then
echo $f
mysql < $f
fi
done
fi
## 追記ここまで
mysqladmin shutdown
## 省略
fi
## 省略
上記について一部補足をする。
・"RUN mkdir /docker-entrypoint-initdb.d"
デフォルトは CentOS7.9 なので"/docker-entrypoint-initdb.d"というディレクトリは存在しない。MySQL の Dockerfile と同じように"/docker-entrypoint-initdb.d"ディレクトリを作成し、コンテナ起動時に流したい初期 SQL の置き場所を作成している(MySQL の Dockerfile についてはRUN mkdir /docker-entrypoint-initdb.dを参照)。
・"COPY entrypoint.sh /root/entrypoint.sh ~ ENTRYPOINT ["/root/entrypoint.sh"]"
groonga/mroonga:mysql5734_mroonga1103 のイメージの ENTRYPOINT の処理に追加で初期 SQL を流す処理を加えたいので、独自に entrypoint.sh を作成し、コンテナ起動時に自身で作成したシェルを実行するようにしている(Dockerfile の ENTRYPOINT とは?など Dockerfile に関しては後でリンク張るを参照)
・"if [ -d /docker-entrypoint-initdb.d ]; then ~ fi"
MySQL の docker-entrypoint.shを参考に、コンテナ起動時に初期 SQL を実行できるようにした部分
このように設定を行った後、ホスト側の"./data"を削除して、docker-compose up を実行してみる。すると./data/mysql が作成され、さらに初期 SQL が流れているので"sample"というデータベースに"groups"などのテーブルが存在する事が確認できる。また、初期データとして"groups"などにデータが存在する事も確認できる。
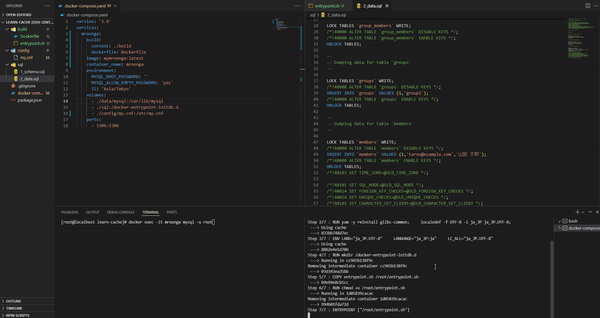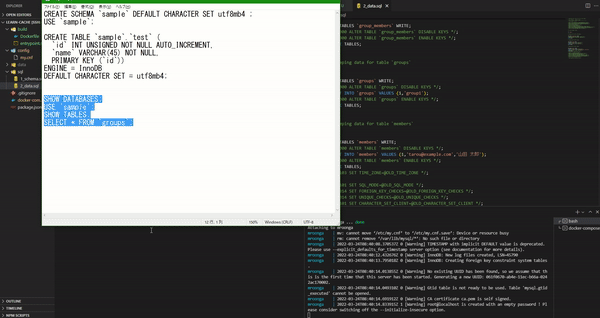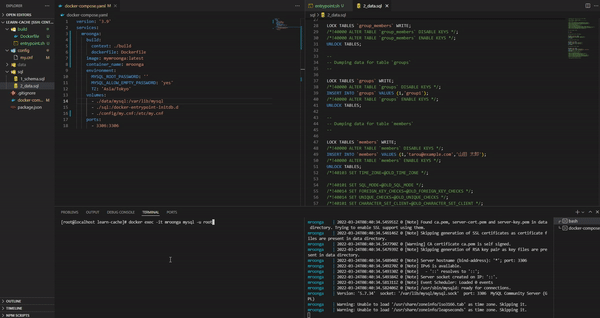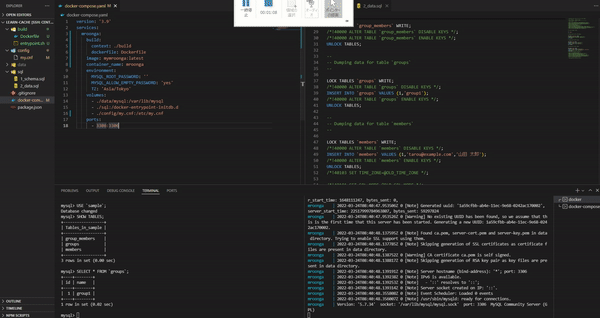
・参考:Laradock で任意データベース作成・追加 - Laradock mysql - 少し docker
・参考:Bash scripting cheatsheet
速度比較用にテーブルを作成する
mroonga は InnoDB などと同じ STORAGE ENGINE として指定できるものになる。
mysql> SHOW PLUGINS;
+----------------------------+----------+--------------------+---------------+---------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+---------------+---------+
...
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
...
| Mroonga | ACTIVE | STORAGE ENGINE | ha_mroonga.so | GPL |
+----------------------------+----------+--------------------+---------------+---------+
45 rows in set (0.00 sec)
というわけでストレージエンジンが Mroonga であるテーブルを作成する(速度比較のために InnoDB でも同じスキーマのテーブルを作成する)。
CREATE TABLE `full_text_search_innodb` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`text` varchar(255) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
FULLTEXT KEY `text_idx` (`text`) /*!50100 WITH PARSER `ngram` */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `full_text_search_mroonga` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`text` varchar(255) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
FULLTEXT KEY `text_idx` (`text`) /*!50100 WITH PARSER `ngram` */
) ENGINE=Mroonga DEFAULT CHARSET=utf8mb4;
上記の SQL について一部補足をする。
・"FULLTEXT KEY"
全文検索(カラムの値を部分一致で検索)を高速に行うには FULLTEXT インデックスを作成する必要がある(LIKE でも全文検索をしようと思えばできるが TEXT 型や VARCHAR 型ではパフォーマンスが悪くなる)(詳細は14.6.2.4 InnoDB Full-Text Indexesを参照)。
・"WITH PARSER `ngram`"
FULLTEXT インデックスはカラムの文字がそのままインデックスになるのではなく、パーサーによって文字分割されてインデックスが作成される(実際のインデックスの中身は「おまけ」の「FULLTEXT インデックスの中身を見てみる」を参照)。文字分割はデフォルトだと単語間の空白で行われるが、日本語や中国語などのように空白が関係のない言語もある。そこで ngram というパーサーを使って文字を分割する事で FULLTEXT インデックスが作成できるようにする(詳細は12.10.8 ngram Full-Text Parserを参照)。
・"/_!50100 WITH PARSER `ngram` _/"
MySQL 5.6.10 以前のバージョンで構文エラーが発生するオプションを無視するようにするための書き方で、mysqldump で dump するとこうなる(以下、公式からの引用)。
This causes MySQL 5.6.10 and earlier servers to ignore the option, which would otherwise cause a syntax error in those versions.(これにより、MySQL 5.6.10 およびそれ以前のバージョンでは構文エラーが発生するオプションを無視するようになりました)
※カラム型について、TEXT 型だと Index を張る際にインデックスプリフィクス長を指定する必要があり(For indexes on BLOB and TEXT columns, you must specify an index prefix length)、結局最初の何文字か(最大でも 255 文字)でしか有効にならないので今回は"VARCHAR(255)"にしている(255 文字というのは 1 文字 3 バイトと計算した時の MySQL5.7 での話)(以下、公式からの引用)。
Prefixes can be up to 1000 bytes long (767 bytes for InnoDB tables, unless you have innodb_large_prefix set).(プリフィックスの長さは最大 1000 バイト(InnoDB テーブルでは、innodb_large_prefix が設定されていない限り 767 バイト)です。)
・参考:世界一わかりやすい FULLTEXT INDEX の説明と気を付けるべきポイント
データの用意
大量にデータを登録する必要があるが、これについてはデータの用意に書かれている通りのやり方でやる。
mysql> INSERT INTO `full_text_search_innodb` VALUES (1,'親譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰を抜かした事がある。'),(2,'この文章はダミーです。文字の大きさ、量、字間、行間等を確認するために入れています。'),(3,'つれづれなるまゝに、日暮らし、硯にむかひて、心にうつりゆくよしなし事を、そこはかとなく書きつくれば、あやしうこそものぐるほしけれ。'),(4,'ダミーテキスト。ダミー テキスト。ダミーテキスト。ダミーテキスト。'),(5,'後ろで大きな音がした。俺は驚いて振り返った。'),(6,'こんにちは。こんばんは。こんにちは。こんばんは。'),(7,'吾輩は猫である。吾輩は猫である。吾輩は猫である。'),(8,'速度 検証のテスト。速度検証のテスト。速度検証のテスト。'),(9,'Mroongaは全文検索エンジンであるGroongaをベースとしたMySQLのストレージエンジンです。'),(10,'Dockerイメージを作成してみる。Dockerイメージを作成してみる。');
Query OK, 10 rows affected (0.01 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> INSERT INTO `full_text_search_mroonga` VALUES (1,'親譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰を抜かした事がある。'),(2,'この文章はダミーです。文字の大き さ、量、字間、行間等を確認するために入れています。'),(3,'つれづれなるまゝに、日暮らし、硯にむかひて、心にうつりゆくよしなし事を、そこはかとなく書きつくれば、あやしうこそものぐるほしけれ。'),(4,'ダミーテキスト。ダミ ーテキスト。ダミーテキスト。ダミーテキスト。'),(5,'後ろで大きな音がした。俺は驚いて振り返った。'),(6,'こんにちは。こんばんは。こんにちは。こんばんは。'),(7,'吾輩は猫である。吾輩は猫である。吾輩は猫である。'),(8,'速 度検証のテスト。速度検証のテスト。速度検証のテスト。'),(9,'Mroongaは全文検索エンジンであるGroongaをベースとしたMySQLのストレージエンジンです。'),(10,'Dockerイメージを作成してみる。Dockerイメージを作成してみる。');
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> INSERT INTO full_text_search_innodb(SELECT full_text_search_innodb.id = NULL, full_text_search_innodb.text FROM full_text_search_innodb, full_text_search_innodb full_text_search_innodb2, full_text_search_innodb full_text_search_innodb3, full_text_search_innodb full_text_search_innodb4, full_text_search_innodb full_text_search_innodb5, full_text_search_innodb full_text_search_innodb6);
Query OK, 1000000 rows affected (1 min 37.75 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
mysql> INSERT INTO full_text_search_mroonga(SELECT full_text_search_mroonga.id = NULL, full_text_search_mroonga.text FROM full_text_search_mroonga, full_text_search_mroonga full_text_search_mroonga2, full_text_search_mroonga full_text_search_mroonga3, full_text_search_mroonga full_text_search_mroonga4, full_text_search_mroonga full_text_search_mroonga5, full_text_search_mroonga full_text_search_mroonga6);
Query OK, 1000000 rows affected (1 min 9.14 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
この状態でデータの行数を確認すると以下の通り 100 万と 10 行になる。
mysql> SELECT COUNT(*) FROM `full_text_search_innodb`;
+----------+
| COUNT(*) |
+----------+
| 1000010 |
+----------+
1 row in set (0.23 sec)
mysql> SELECT COUNT(*) FROM `full_text_search_mroonga`;
+----------+
| COUNT(*) |
+----------+
| 1000010 |
+----------+
1 row in set (0.00 sec)
最後に速度を計測するための追加設定を行っていく。
速度計測のために Performance Schema を有効にする
これについてはPerformance Schema の有効化に書かれている通りのやり方でやる。以下のようにクエリーの実行速度が見れるようになっていれば OK。
mysql> SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%COUNT%';
+----------+----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EVENT_ID | Duration | SQL_TEXT |
+----------+----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 41 | 0.320546 | SELECT COUNT(*) FROM `full_text_search_innodb` |
| 57 | 0.000476 | SELECT COUNT(*) FROM `full_text_search_mroonga` |
+----------+----------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
まとめとして
今回は MySQL において全文検索の性能比較を行うために、Mroonga のセットアップをする手順をみてきた。以前 docker-compose で MySQL をセットアップした際にはすごく簡単だったので Mroonga でも同じだろうと思っていたら、そうでもなかった…。
次回は実際に上記でセットアップした Mroonga(MySQL)を使って、全文検索の性能比較をやってみたいと思います。
参考文献
おまけ
Docker コンテナ内の locale の設定について
この辺り、Ubuntu(Debian 系)と CentOS(RHEL 系)で違うようなので注意が必要。詳細は先人がいるのでそちらを参照。ちなみに、CentOS7.9 では環境変数を設定しただけでは以下のように warn が出力され、サーバーが起動しない。
[root@localhost learn-cache]# docker-compose up
Starting mroonga ... done
Attaching to mroonga
mroonga | /bin/bash: warning: setlocale: LC_ALL: cannot change locale (ja_JP.utf8): No such file or directory
・参考:Docker: コンテナの locale を設定したい
FULLTEXT インデックスの中身を見てみる
mysql> SET GLOBAL innodb_ft_aux_table = 'sample/full_text_search_innodb';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
+--------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+--------+--------------+-------------+-----------+--------+----------+
| ck | 11 | 11 | 1 | 11 | 2 |
| ck | 11 | 11 | 1 | 11 | 42 |
| do | 11 | 11 | 1 | 11 | 0 |
| do | 11 | 11 | 1 | 11 | 42 |
| er | 11 | 11 | 1 | 11 | 4 |
...
| 、あ | 4 | 4 | 1 | 4 | 147 |
| 、そ | 4 | 4 | 1 | 4 | 105 |
| 、字 | 3 | 3 | 1 | 3 | 57 |
| 、心 | 4 | 4 | 1 | 4 | 63 |
| 、日 | 4 | 4 | 1 | 4 | 27 |
...
| 全文 | 10 | 10 | 1 | 10 | 10 |
| 分学 | 2 | 2 | 1 | 2 | 90 |
| 吾輩 | 8 | 8 | 1 | 8 | 0 |
| 吾輩 | 8 | 8 | 1 | 8 | 24 |
| 吾輩 | 8 | 8 | 1 | 8 | 24 |
...
+--------+--------------+-------------+-----------+--------+----------+
365 rows in set (0.00 sec)
《この公式ブロガーの記事一覧》
__________________________________
執筆者プロフィール:Katayama Yuta
SaaS ERPパッケージベンダーにて開発を2年経験。 SHIFTでは、GUIテストの自動化やUnitテストの実装などテスト関係の案件に従事したり、DevOpsの一環でCICD導入支援をする案件にも従事。 昨年に開発部門へ異動し、再び開発エンジニアに。フロントエンド・バックエンドの両方を担当。座学で読み物を読むより、色々手を動かして試したり学んだりするのが好きなタイプ。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/