単一GPUで動画・画像・音声・テキスト対応のマルチモーダルモデルを訓練して推論!?何を言ってるかわかねーと思うが、俺も何を見ているのかわからねえ

お正月なのですがAIは待ってはくれないので毎日「デイリーAIニュース」だけは続けている今日この頃。
中国のテンセントがとんでもないオープンソースをぶっ込んできた。
https://crypto-code.github.io/M2UGen-Demo/
動画、画像、音楽、テキストという四つのモードを学習させた「マルチモーダル」モデルで、しかもベースはllama-7Bということで、V100 32GB一つで推論可能(CPUのRAMは49GB以上必要)どころか学習も可能。ホントかよ!!
しかもしれっと日本語でも命令できるし。

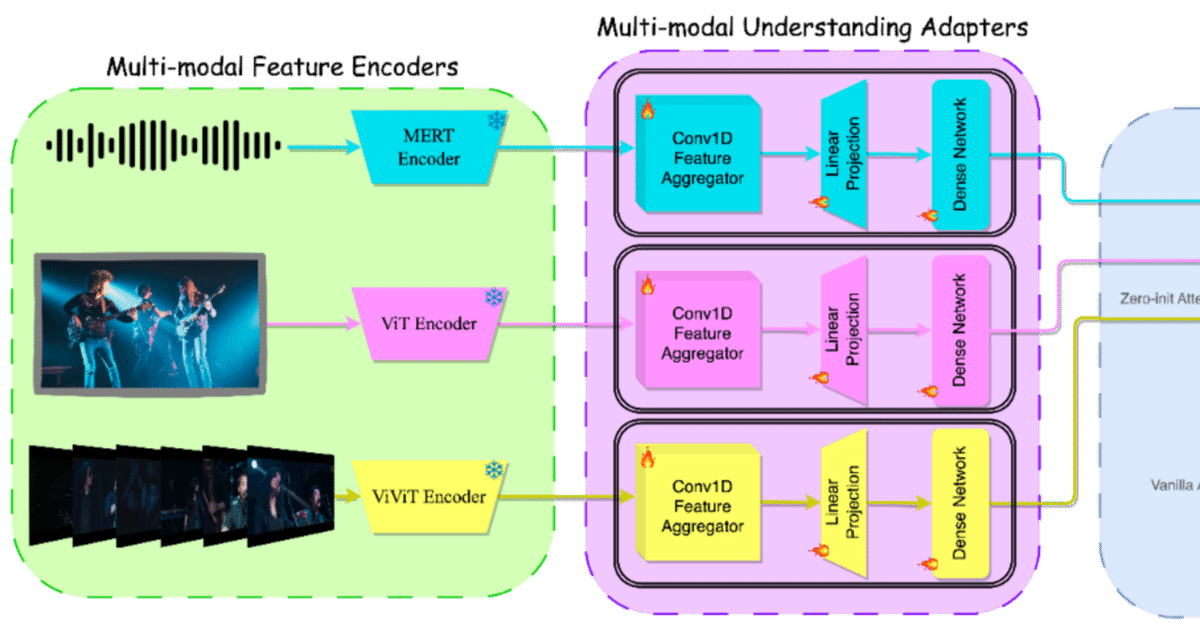
なんかこの研究の名前はかなり控えめに「音楽理解できるマルチモーダルモデル」みたいに書いてあるんだけど、とんでもない。実際にはこれは「どんな情報も入力できるマルチモーダルモデル」のプロトタイプである。

音声、画像、動画といった情報を図の紫の部分にある各種アダプターを学習させ、それを青い部分にある既存のLLM(ここではMPT-7Bを使用)にプロンプトと一緒に入力し、LLMからAudioLMへの入力ベクトルと応答出力(テキスト)を取り出している。ものすごくシンプルなのだ。ソースコードを見るとよくわかる。
Sunoに15000円くらい課金した僕としては微妙な心境だが、残念ながら歌詞を歌う機能はないのでまだSunoの方が上。でも時間の問題だな。たぶん。
これは現状は、音楽をインタラクティブに作ってくれるチャットボット的なものなのだが、このプログラムを応用すれば、音楽どころかいろんなことを同時に解決するようなモデルが作れるだろう。
2024年はテンセントの発するオープンソース・マルチモーダルの号砲と共に幕を開けたのだ!
ってかソースコード見るとほぼ全て力技なのも凄いが、ちゃんと動いてるのはもっと凄い。
再現実験する気力が失われるほどに凄いのだが、再現には32GB以上のVRAMを持つGPUが必要ということで少しハードルが高い。要はA6000クラスのGPUがあれば再現できる。
しかも大規模なクラスターではなく単一のV100 32GBで学習できたというのがもっと凄いのである。
MU2GENはその名の通り出力が音楽とテキストのみだが、当然のように動画を出力するようなものもすぐにでてくるだろう。
今年は色々と何がでてくるか楽しみだ。