
驚異の1ビットLLMを試す。果たして本当に学習できるのか?

昨日話題になった「BitNet」という1ビットで推論するLLMがどうしても試したくなったので早速試してみた。
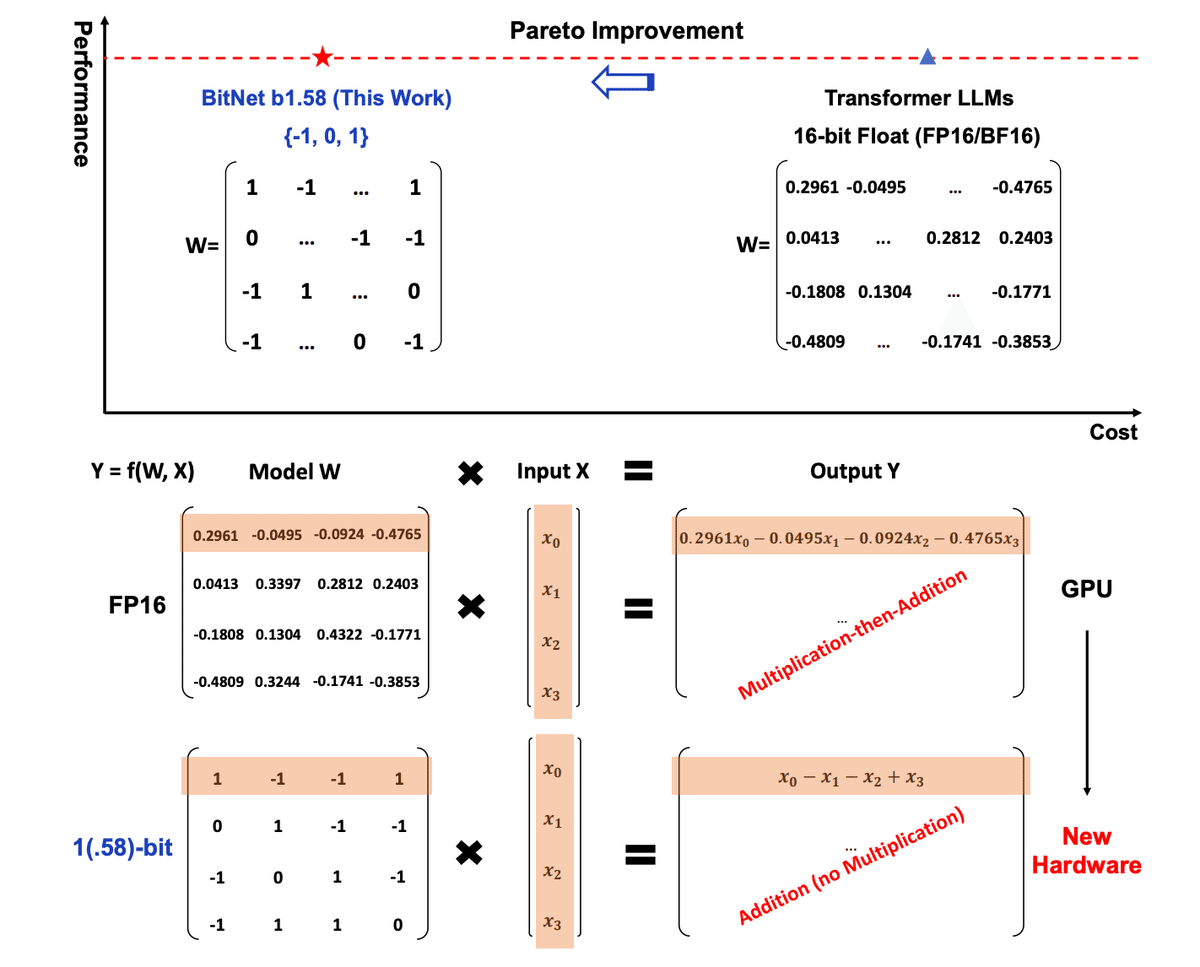
BitNetというのは、1ビット(-1,0,1の三状態を持つ)まで情報を削ぎ落とすことで高速に推論するというアルゴリズム。だから正確には0か1かではなく、-1か0か1ということ。
この手法の行き着くところは、GPUが不要になり新しいハードウェアが出現する世界であると予言されている。マジかよ。
https://arxiv.org/pdf/2402.17764.pdf
ということで早速試してみることにした。
オフィシャルの実装は公開されていないが、そもそも1ビット(と言っていいのかわからない,-1,0,1の三状態を持つからだ。 論文著者はlog2(3)で1.58ビットという主張をしている)量子化のアルゴリズム自体の研究の歴史は古いので、BitNetによるTransformerの野良実装はいくつか公開されていた。
いくつか実装を試したが、一番手っ取り早く動かせたのはこれだった。
相変わらず、この世界は本当にすごいことは本当に一瞬かつシンプルに記述される。
まず「本当に1ビットなのか」という疑問には、このコードのこの部分を見ればわかる。
def binarize_weights(self):
alpha = self.weight.mean()
binarized_weights = torch.sign(self.weight - alpha)
return binarized_weights
def forward(self, input):
# Binarize weights
binarized_weights = self.binarize_weights()
# Normal linear transformation with binarized weights
output = torch.nn.functional.linear(input, binarized_weights, self.bias)
# Quantize activations (before non-linear functions like ReLU)
output = self.quantize_activations(output)
# For the sake of demonstration, we'll also include the scaling step.
# In practice, this would be done before a non-linear function in a forward pass.
output = self.scale_activations(output)
return output
torch.signは、与えられたテンソルがプラスなら1,マイナスなら-1、ゼロなら0を返す。つまり本当にバイナリになっている。
それでも信じられない俺は、ひとまずwikitextを学習させるサンプルを走らせてみた。
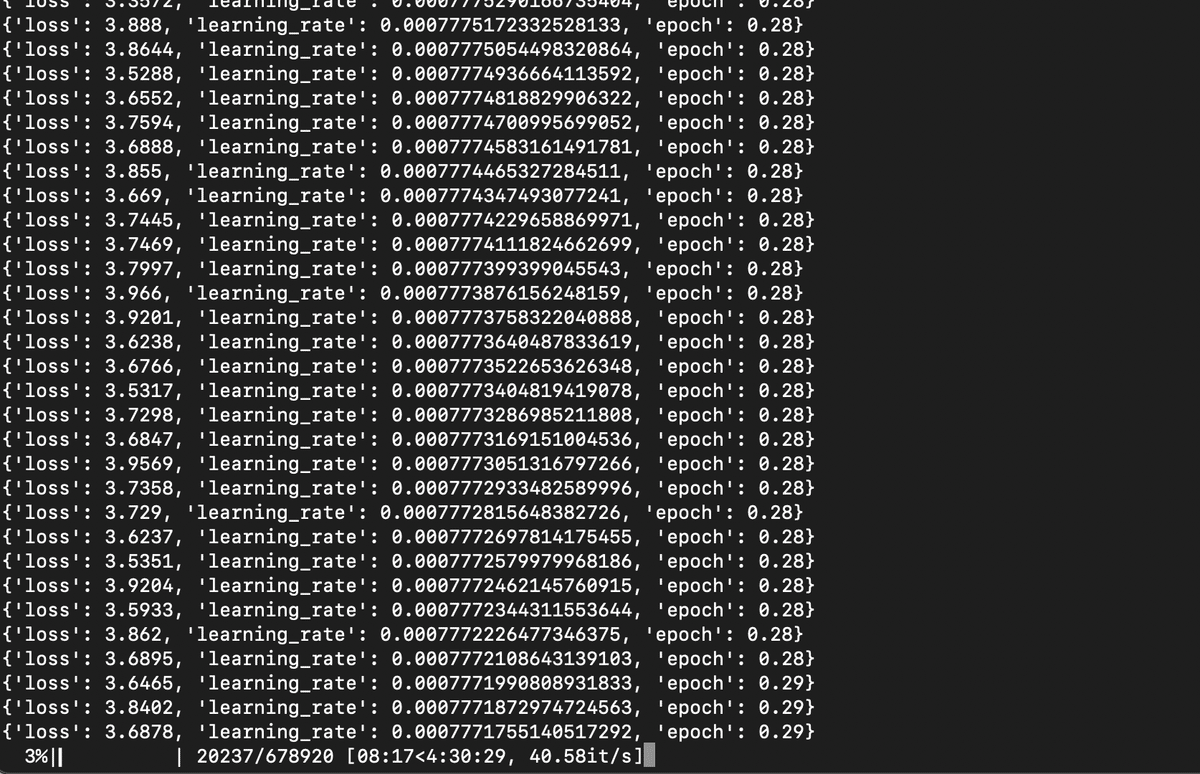
lossは4.9から始まり、最終的に2.78まで下がった。もっと回せばもっと下がりそうだ。
問題は果たしてこれでちゃんと学習できているかということだ。
>>> tokenizer = AutoTokenizer.from_pretrained("bitllama-wikitext")
>>> model = AutoModelForCausalLM.from_pretrained("bitllama-wikitext")
>>> t=tokenizer("Apple Inc.",return_tensors="pt")
>>> tokens = model.generate(**t,temperature=0.7, max_new_tokens=64,do_sample=True,)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
>>> print(tokenizer.decode(tokens[0]))
<s> Apple Inc. Inc. was launched in 1994 and was released in the United States in 2007 . It was a part of the Samsung Dreamer , which was released in a limited edition in 2007 and was released in 2008 .
>>> tokens = model.generate(**t,temperature=0.7, max_new_tokens=64,do_sample=True,)
>>> print(tokenizer.decode(tokens[0]))
<s> United States is the most widely owned commercial market , with over $ 129 million in 2000 . The largest share for the market is in Switzerland , where it is the largest in the world . The largest share of this is US $ 39 million . <unk> is the largest investment in theなんかそれっぽいこと言ってる!!!!!!
しかも小さいから当たり前なのだが推論は超速いのである。
モデルサイズは200MB。GBじゃないよ。
僕は小さい言語モデルも大きい言語モデルもそこそこ触って来た方だと思うが、このサイズでこの解答は驚異的だ。もっと出鱈目なことを言うのが常なのである。
内容は支離滅裂だとしても(実際に支離滅裂だ)、文法的に合ってるというのは普通このサイズの言語モデルではありえない。
この実装が公開されたのは4ヶ月前だが、なぜこれまで話題に登ってこなかったのか。
それは、BitNetが、その性質上、小さいモデルではtransformerに精度で勝てなかったからだ。
ところが今回の論文では、3B以上のパラメータサイズになるとBitNetは精度でも推論速度でもtransformerに勝つことがわかり、70Bモデルになるとその推論速度差は現行のハードウェアでさえ8.9倍になるという。
従って、BitNetはもともとすごい可能性を秘めていたのだが色々な人の直感に反していたためこれまで真に有望な技術とは考えられておらず追試があまりされていなかった。
しかし、今やBItNetは本当に機能することがわかった。しかもかなり手軽に学習できる。
今回は「とりあえず本当かよ」ということを試しただけなのでデータセットも規模も小さいが、わずか5時間でなんとなく意味ありげな答えを導くところまで持っていくことができた。
もっと大きな規模のネットで、もっと大きな規模のデータセットを学習させればもっと意味のある結果になるかもしれない。しかし僕は今はただただ驚いている。
とにかく何かが起きようとしていることは間違いない。
今回学習したモデルはここ