
これぞ革命!?ゼロから大規模言語モデルを学習できるReLORA登場(7/18追記あり)

導入 本当に革命的な技術なのか?
「君たちはどう生きるか」で驚いている間にすごい論文が世界の話題を掻っ攫っていた。
その名も「ReLORA」簡単に言えば、「事前学習にLoRAを使う」というものである。
これは本当に革命的な発見かもしれないので、僕の仮説も含めて丁寧に説明する。
まず、大前提として、「LoRA」という技術について
LoRAは、「Low Rank Adaptation(日本語で言うとすれば低階適応)」という技術で、これまでは主にファインチューニングに使われてきた。
ファインチューニングとは、あらかじめ学習されたニューラルネットワークに対して追加で学習させ、概念を強調させたり新しく覚えさせたりする。
たとえば、僕の顔でStableDiffusionをファインチューニングすれば、僕みたいな顔の絵がどんどん出てくる。
言語モデルにおけるLoRAも同様で、新しい概念や「こういうやりとりが欲しい」という目的に適用するときに効果を発揮する。
GPT-3にもファインチューニングするオプションがあり、医学的な専門知識や金融的な専門知識を加えるのに使われている。
LoRAは、ファインチューニングをさらに効率的に行うためのもので、通常のファインチューニングはネットワーク全体に対して行う。
たとえば、10B(100億)パラメータあるとしたら、それを通常のファインチューニングするにはその十倍くらいのパラメータを収容するメモリー(VRAM)が必要になる。人工知能においてVRAMは最も高価な資源なので、最も高価なA100(80GB)とか日本にまだ何台入ってくるかわからないH100(80GB)を何個も確保する必要がある。
そうすると、そんなことができるマシンは4000万円から一億以上するので、普通の人は滅多なことでは手が出せないし、企業だって二の足を踏んでしまう。
ところがLoRAは、パラメータ全てに対して学習するのではなく、全パラメータのわずか数パーセントに対してのみ学習をかける。その場合、学習に使うメモリ量を大幅に抑えることができる。
たとえば、僕が自宅にあるドスパラ製A6000x2(48GBx2=96GB)マシンで7BモデルをLoRAでファインチューニングしようとすると、60GBくらいのVRAMで足りることになる。A6000x2のマシンは200万円くらいで作れるし、一世代前の3090(24GB)x4のマシンは60万円くらいでも作れるかもしれない。3090は中古で10万円くらいで買えるので、10x4=40万円+本体分20万円=60万円で挑戦できる。一気に身近になるのだ。
そこでここ数ヶ月(といっても4月からまだ3ヶ月経ったばかりだが)はLLMをLoRAでなんとか自分の欲しい出力を学習できないか試す人があちこちに現れたわけだ。
しかし、実際問題として、日本語を扱う上ではCyberAgentが作ったOpenCALMや、rinnaが作ったrinna-3Bとかが断然うまく動いていた。やはり最初に何を学習したかはすごく大事で、世界各国の言語を同時に学習するようなやり方でやると、どうしてもとっ散らかってしまうのが我々、日本人のLLM愛好者の悩みだった。
ところが、そこに登場したのがReLoRAという革命的な手法である。
簡単に言えば、「最初の学習(事前学習)の段階からLoRA的に学習すればいいじゃん」というコロンブスの卵のようなアイデアだ。
TL;DR
— Vlad Lialin (@guitaricet) July 13, 2023
ReLoRA recipe:
1. LoRA with resets
1. Partial optimizer reset
1. Jagged LR scheduler
1. Short full-rank training warmup
It starts working at roughly 250M scale and, at 1B scale, improves RAM consumption and speed by 50% ⚡️. Larger gains for larger networks. pic.twitter.com/01rNbFKCAi
しかもすごいのは、学習するパラメータを少なくしても、学習結果全体はそれほど変化がないという事実が指摘されたことにある。さらに、巨大になればなるほど効果が高くなると言われている。
これを使えば、先ほど示したようなLoRA用に使える低価格帯のマシンであっても、大規模言語モデルをゼロから学習できてしまうのだ。
実際に実装も公開され、僕も今さくらインターネットのサーバーと自宅のドスパラの特注マシンとで7Bモデルと1Bモデルの学習を実験している。今のところ、学習はうまく行っているようだ。

学習に使ったパラメータなどはforkしてgithubに置いてある
train7B.shとtrain3B.shがそれで、7BはA6000x2用、1BはV100x4用となっている。ご家庭(会社)に似た環境があればすぐ試せる。
(7/16 7:01 追記)
さくらの高火力サーバーで学習させた1B版(3Bは間違い)の学習結果を掲載する。ReLORAでも驚くほど綺麗にeval_lossが下がっている。

ウェイトは公開するほどでもないと思う(C4の高々2万ステップなので)今回はレポートだけ。引き続き色々実験してみたい。ドスパラのサーバーで動かしているA6000x2の7Bモデルの方はネットが大きいのでまだ学習中だが、こちらも学習が終了すれば追記で報告する。
検証 本当はどうなのか?(※7/18追記)
ReLoRAの論文の擬似コードを見るとこうなっている。

最初の数千ステップはwarm startステップと呼ばれており、「通常のトレーニングを行う」と書いてある。これだと全パラメータを一旦は学習しなければならないことになり、このタイミングでは相当な規模のパラメータ数が必要なことになって辻褄が合わない。VRAMが少なくても大規模言語モデルが学習できるというのは僕の勘違いかもしれない。でもだとすると、これは学習のごく初期でとめてLoRAだけで学習を回していけば精度が上げられるという意味で、学習全体が劇的に高速化できるという話なのかもしれない。実際、今公開されている実装では、ひとつのVRAMに乗り切らないモデルは学習できないようだ。(V100なら3Bまで、A6000なら7Bまで)
ただ、もしも最初のwarmステップでフルトレーニングしてるとすると辻褄が合わない

もしも最初のWarmステップでフルトレーニングしているなら、最初はGPUメモリを大量に消費して、Warm後は消費しなくなるはずだ(普通に考えると)。
もしくはWarmステップからずっとGPUメモリを確保しっぱなしなのかもしれないが・・・。もうちょっと踏み込んでソースを読む必要があるが、本来全く学習できないはずのV100での3BモデルやA6000での7Bモデルの学習ができてしまう理由が何かあるのかもしれない(たとえばbf16だからできるとか)
(7/18 10:47 さらに追記)
どうしても納得がいかなかったので、ソースコードから実際にどのくらいのパラメータを学習しているのか調べてみた。
まず、PEFT_PreTrainingのソースコードをgit cloneする
PythonのREPLでモデルを作ってみる。
>>> import os
>>> import time
>>> import json
>>> import random
>>> import argparse
>>> from datetime import datetime
>>> from typing import Union
>>> from pprint import pformat
>>>
>>> import numpy as np
>>>
>>> import torch
>>> import torch.nn as nn
>>>
>>>
>>> import transformers
>>> from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM, LlamaForCausalLM
>>>
>>> import datasets
>>> import wandb
>>>
>>> from tqdm import tqdm
>>> from loguru import logger
>>>
>>> import peft_pretraining.training_utils as training_utils
>>> from peft_pretraining.relora import ReLoRaModel
>>> model_config = AutoConfig.from_pretrained("configs/llama_7b.json")
>>> model: Union[LlamaForCausalLM, nn.Module] = AutoModelForCausalLM.from_config(model_config)
>>> model.parameters()
>>> params_before = sum(p.numel() for p in model.parameters())
>>> print(params_before)
6738415616
>>> trainable_before = sum(p.numel() for p in model.parameters() if p.requires_grad)
>>> trainable_before
6738415616
この段階では、まだ全パラメータが6.7B(約7B)で、学習可能なパラメータ数も6.7Bになっている。
しかしこのコードでは、まずReLoRAをやる場合、全てのパラメータを一旦学習しないことにしている。
>>> for p in model.parameters():
... p.requires_grad = False
...
>>> need_linear_weight =Trueその後、ReLoRaモデルを作り直している
>>> model = ReLoRaModel(
... model,
... r=128,
... lora_alpha=32,
... lora_dropout=0.1,
... target_modules=["attn", "mlp"],
... trainable_scaling=False,
... keep_original_weights=False,
... lora_only=not need_linear_weight,
... )さらに、必要な場所にだけ勾配をつけて学習できるようにしている。
>>> for name, param in model.named_parameters():
... # LLaMa: model.norm, model.layers.input_layernorm, model.layers.post_attention_layernorm
... if "norm" in name:
... param.requires_grad = True
... elif "lm_head" in name:
... param.requires_grad = True
... elif "embed_tokens" in name:
... param.requires_grad = True
... elif "bias" in name:
... param.requires_grad = True
... elif "lora_" in name:
... param.requires_grad = True
... else:
... param.requires_grad = False
... すると、トータルのパラメータ数は増えるが、学習するパラメータ数は激減している。
>>> params_after = sum(p.numel() for p in model.parameters())
>>> trainable_after = sum(p.numel() for p in model.parameters() if p.requires_grad)
>>> params_after
7058231296
>>> trainable_after
582225920トータルのパラメータ数は7Bだが、学習するパラメータ数は582Mまで減っている。つまり論文ではウォームアップ中は全パラメータ学習するように見えるのだが、実装ではそうはなっていない。だから、貧乏仕様のご家庭PC(A6000x2)で曲がりなりにも7Bが学習できてしまったのである。
どうしてこういう誤解が広まったのか考えてみると、論文の後半の方の記述を読んで疑問が氷解した。
ReLoRAで導入されるテクニックは4つある。
Restarts
Jagged Schedule
Optimizer Reset
Warm Start
これらを組み合わせた時の性能(perplexity)についてTable3にまとまっている。

ちなみにこのコードでは、Jagged Schedule、Warm Startは主に学習率のスケジューラの中で実行されている。つまり、後半で主張されている手法「Warm Start」は、前半のAlgorithm 1で示されている「Warm start」とは関係なさそうだ。
def _get_cyclical_cosine_schedule_with_min_lr_lambda(current_step, *, num_warmup_steps, cycle_length, min_lr_ratio):
assert 0 < min_lr_ratio <= 1.0, "min_lr_ratio must be in (0,1]"
# compute where we are in the current cycle
cycle_step = current_step % cycle_length
if cycle_step < num_warmup_steps:
if current_step != cycle_step:
if cycle_step < 2:
return 1e-7
return float(cycle_step) / float(max(1, num_warmup_steps))
progress = float(cycle_step - num_warmup_steps) / float(max(1, cycle_length - num_warmup_steps))
cosine_decay = 0.5 * (1.0 + math.cos(math.pi * progress))
return min_lr_ratio + (1.0 - min_lr_ratio) * cosine_decay
Optimizer Resetはmain.py(torchrun_main.py)のなかで行われている。
# restart model after we modify the learning rate, so on the next step after the relora frequency
if args.relora and update_step > args.relora and update_step % args.relora == 1:
copy_of_opt_state = list(optimizer.state.values())[1]["exp_avg"].clone()
if not args.reset_optimizer_on_relora:
logger.info("Saving optimizer states")
tmp_optimizer_path = os.path.join(args.save_dir, "tmp_optimizer", "optimizer.pt")
os.makedirs(os.path.dirname(tmp_optimizer_path), exist_ok=True)
torch.save(optimizer.state_dict(), tmp_optimizer_path)
logger.info(f"Performing lora reset. Current lr is {optimizer.param_groups[0]['lr']}")
n_lora_restarts += 1
model.merge_and_reinit()
if args.reset_optimizer_on_relora:
logger.info("Resetting optimizer states to zeros")
for group in optimizer.param_groups:
for p in group["params"]:
param_state = optimizer.state[p]
param_state["exp_avg"] = torch.zeros_like(p.data)
param_state["exp_avg_sq"] = torch.zeros_like(p.data)
else:
assert torch.all(copy_of_opt_state == list(optimizer.state.values())[1]["exp_avg"]), "Optimizer states are not the same after lora reset"
logger.info("Loading optimizer states")
optimizer.load_state_dict(torch.load(tmp_optimizer_path))
assert torch.all(copy_of_opt_state == list(optimizer.state.values())[1]["exp_avg"]), "Optimizer states are not the same after loading"
もう一度、セクション4を読み直してみると、確かにこの実験では最初に5000ステップのフルランク学習を行った後で、それぞれのサイズで3回ずつReLoRAを回している。が、これが必ずしもReLoRAにはフルランクの事前学習が必須であることを意味しない(そうだとすればReLoRAは事前学習の新手法というよりもLoRAの改善というものにしかならない)。どちらかというと時間を節約する目的でフルランク学習をして比較したと解釈すべきだろう。
実際、実装にはフルランク学習に関するコードが一切含まれていない。
にもかかわらず、学習はうまく進んでいるので重要なのはフルランク学習よりも学習率のウォームアップだということではないだろうか。

セクション7のまとめでは、今回の実験では使用できる計算資源に限界があったことが示されている。
そもそもReLoRAは小規模な言語モデルではあまり威力を発揮できず、1.3B以上の大規模なモデルで実験したところ、メモリ消費が30%減り、トレーニングのスループットが52%上がったという。おそらくもっと大きなモデルではさらに効果があるだろうと予測されている。
RedPajama-1Tを20Kステップ学習させてみた
ソースコードを見るとRedPajama-1Tを学習させるつもりだったらしいので、こちらで一足先に試してみた。V100x4で4時間ほどの途中経過
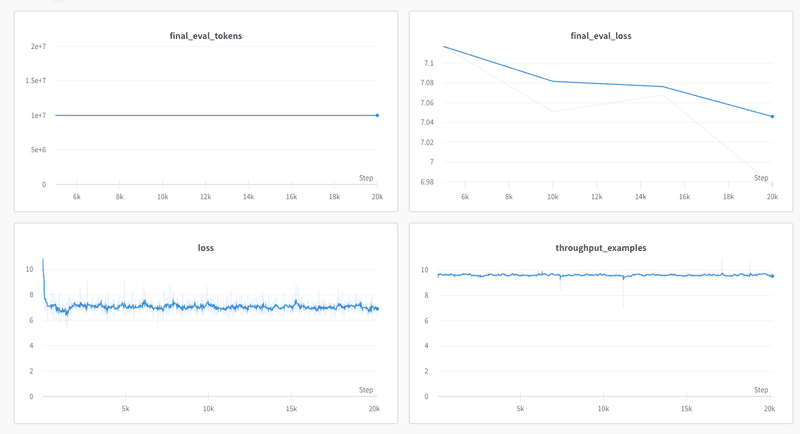
lossの下りが悪いのは、RedPajamaのデータが巨大すぎて1エポックにもなかなか到達しないからだろう。スループットは悪くない。
ウォームアップで学習率をゼロから1まで上げていく過程で一度激しく落ち、その後は停滞を続けている。もっと長い時間回してみないとわからないかな。

GPU利用率はRestartが入るたびにガクッと落ちているのがわかる。
(7/21追記)
1Bモデルを6万ステップほど学習させてみた。

Final Eval lossが綺麗に下がっている。まだ高いけど。
学習率はこんな感じ

有望な方法に見えるが、LLaMA2をQLoRAのほうが簡単なのでどっちをやるべきかは考えどころ
考察 一体どう言うことなのか?
さて、ここまでが今明らかになっているファクトだ。
以下に僕の考察を述べる
深層学習に関する論文やコードは星の数ほどあるので僕もとても全部を追いきれてない。それぞれの論文が示している結論はわかるものの、その過程については作ってる人も完全に理解しているとは言い切れないことが多い。その前提で、僕はこれから「なぜこうなっているのか」を妄想してみる。科学的な論文ではないのでツッコミは要りません。
この方式でうまくいくのはなぜなのか。
そこでもういちど「Transformer」というモデルについて考えてみる。
Transformerのコアにあるアイデアの一つは「Attention」というモジュールだ。
Attensionモジュールはどういう構造になっているかというと、下図のようになっている。

Attentionモジュールの目指すところは、入力されたデータ列(たとえば文章)に対して、どの単語に注目するべきか、どの単語とどの単語が関係しているのかを学習する。
ここから先は
¥ 1,000