
Stable Diffusion高速化技術TensorRTインストール方法(第二版)

tensorrtの最新安定版10.0.1正式リリース
Stable DiffusionでTensorRTを使う拡張機能「Stable-Diffusion-WebUI-TensorRT」のインストール方法を4月24日に長々と書いたばかりですが、なんと4月25日にtensorrtがバージョンアップしました。
9.xはすべてdevがついている開発版だったため、8.6.1以来1年ぶりとなる安定版です。
そこで、Stable-Diffusion-WebUI-TensorRTを広めるためにnoteを始めた私としても、最新の安定版で動くのかどうかを検証しました。
しかし、4月24日の投稿は私の実験結果の記録という形になってしまっており、要点がぼやけてしまったように思います。
今回は、インストール方法に絞った投稿にします!
動作要件とCUDAの互換性
NVIDIAはStable-Diffusion-WebUI-TensorRTの動作要件として下記のスペックを挙げています。
8GB以上のVRAMを搭載したNVIDIA製GPU
16GB以上のメインメモリ
NVIDIA Studio Driver 537.58 以降、Game Ready Driver 537.58 以降、
NVIDIA Enterprise Driver 537.58 以降
インターネット接続
さらに、CUDA Toolkit と cuDNN も必要ですので、CUDAと互換性のあるGPUとドライバが入っていなければなりません。
CUDAの互換性リストを見てもよくわからないと思うので、ものすごく雑に言うと、GeForce GTX 900シリーズかGeForce GTX 10xxシリーズ以降のグラフィックカードを使っており、CUDA Toolkit 11.8か12.0以降がインストールされていなければならないとお考え下さい。
(仕様上はGTX 700シリーズでも可能のはずですが、GTX 780 TiでもVRAM3GBですのであまり実用的ではないかと思います)
こちらは、はかな鳥さん(https://note.com/hcanadli12345)が詳しく解説なさっておられますので、参考にさせて頂きましょう。
diffusionらぼさんのTensorRT紹介回
pipのアップデートとxformersのインストール
それではインストールを行っていきます。
前回と同様に新規インストールをしましたので、stable-diffusion-webuiをインストールしたフォルダの下にある\venv\Scriptsフォルダに行って、Shiftキーを押しながら右クリックして「PowerShellウィンドウをここで開く」でPowerShellを開きます。

venvというのはpythonの仮想環境で、要するにこの場所はPCにインストールされているWindowsとは切り離された仮想環境です。
まずactivateでここを使うために有効にします。
activate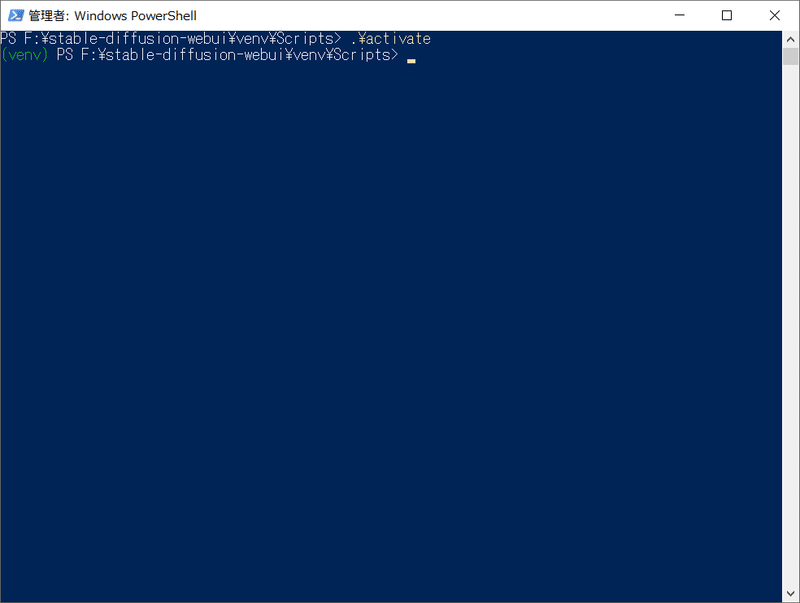
前回も書いたのですが、stable-diffusion-webuiを新規にインストールした際のpipのバージョンが少し古く、そのままだと起動するたびにいちいち警告されるためバージョンアップしておきます。
たぶん、TensorRTだけで画像生成する人はいないと思うので、切り替えて利用できるようにxformersも入れておきます。
python.exe -m pip install --upgrade pip
python.exe -m pip install xformers==0.0.23.post1cudnnのインストール
次に、はかな鳥さんが解説なさっているように、非常に重要なライブラリのパッケージであるcudnnをインストールします。
本来は、Windowsにインストールしたcudnnのバージョンに合わせて入れなければならないのですが、11と12を一度にインストールすればどちらかが入るはずなので、いっぺんにインストールします(適当)。
python.exe -m pip install nvidia-cudnn-cu11==9.1.0.70 nvidia-cudnn-cu12==9.1.0.70 --no-cache-dirその他の必要パッケージもいっしょにインストールされるので、ダウンロードする容量は2GBを超えます。

CUDAランタイムのインストール
前回の記事では、tensorrtをインストールしようとした時に「CUDAが使えねーよ!」と怒られたため、今回は先にCUDAランタイムをインストールしておきます。
これはtensorrtをインストールするために必要なだけです。
インストールされていないとtensorrtのパッケージがビルドできません。
python.exe -m pip install nvidia-cuda-runtime-cu11 nvidia-cuda-runtime-cu12 --no-cache-dir
tensorrtのインストール
次はこの拡張機能の中核になるtensorrtです。
前回は、インストールに必要となるtensorrt-bindingsとtensorrt-libsとのバージョンが違っていたためバージョンを指定していましたが、tensorrtがバージョンアップしたためバージョン指定が不要になりました。
tensorrtはパッケージをビルドしてからインストールしますので、インスタント食品を作って食べるくらい待たされます。
python.exe -m pip install --extra-index-url https://pypi.nvidia.com/ tensorrt tensorrt-bindings tensorrt-libs --no-cache-dir
protobufのインストール
次にprotobufをインストールします。
protobufは、Googleが開発している「Protocol Buffers」という構造データのシリアライズをする技術なのだそうですが、難しくてよくわかりません(笑)。
最新版は5.26.1なのですが、open-clip-torchというパッケージがprotobufの3.x系までしか対応しておらず、単純にpipでインストールすると互換性がないと怒られます。
PyPIにあるopen-clip-torchのプロジェクトページに行くと、LAION-2Bがどうのこうのと書いてあり、なんだか画像生成に極めて重要なパッケージだという気がします。
ここはprotobufの3.x系の最後のバージョンである3.20.3を入れましょう。
python.exe -m pip install protobuf==3.20.3 --prefer-binaryその他の必須パッケージのインストール
そのほかに、ディープラーニングによく使われる(らしい)パッケージがいくつか必要になります。
これはまとめてインストールしても問題はありません。
python.exe -m pip install onnxruntime
python.exe -m pip install colored
python.exe -m pip install polygraphy --extra-index-url https://pypi.ngc.nvidia.com/
python.exe -m pip install onnx-graphsurgeon --extra-index-url https://pypi.ngc.nvidia.com/
deactivateで仮想環境の変更を終了
これでパッケージのインストールは終了です。
deactivateと入力して、仮想環境から抜けましょう。
deactivateStable-Diffusion-WebUI-TensorRTのインストール
他の拡張機能と同じように、リポジトリのURLを入力してStable-Diffusion-WebUI-TensorRTをインストールします。
ここで一度webUIを再起動すると、webUIにTensorRTのタブが現れてTensorRTが利用可能になります。


TensorRTエンジンの作成
webui-user.batのカスタマイズ
さて、一度webUIを終了して再起動するのですが、その前にwebui-user.batを編集して、以下の2行を加えます。
set POLYGRAPHY_AUTOINSTALL_DEPS=1
set CUDA_MODULE_LOADING=LAZY

POLYGRAPHY_AUTOINSTALL_DEPS=1 と書いておくと、もしonnxかtensorrt関係で不足しているパッケージがあった場合、polygraphy が自動的にインストールしてくれるようになります。
CUDA_MODULE_LOADING=LAZY は、CUDAが全モジュールを読み込まずに必要時に適宜読み込むようになるそうです。
設定で「sd_unet」「sd_vae」を表示させる
まず、設定からユーザーインターフェースを開き、「クイック設定」に「sd_unet」「sd_vae」を追加します。
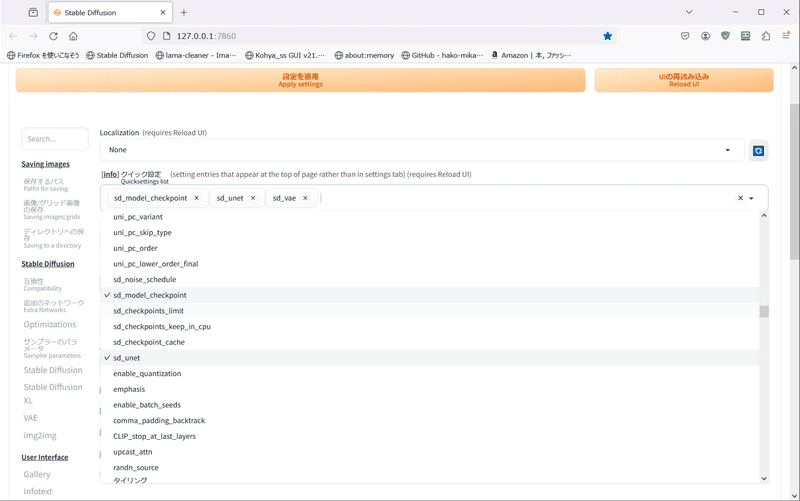
これでcheckpoint(現在のモデル)の隣に「sd_unet」「sd_vae」が表示されます。
checkpointを切り替えてDefaultエンジンを作る
リアル系の画像生成をしている方はLCM_LoRAなどを使って高速で生成するのが流行っていると耳にしましたので、リアル系のモデルは全く知らないのですが「yayoi_mix 2.5とかいいよー」と聞いてさっそくcivitaiでダウンロードしてきました(無謀)。
TensorRTエンジンを作りたいモデルを選択して、TensorRTタブの「プリセット」をDefaultにして「Export Default Engine」を押すと、SD1.5のデフォルト設定でTensorRTエンジンの作成が始まります。
デフォルトのエンジンは必ず作らなければなりません。

けっこう時間がかかることと、VRAMに負荷がかかるためそれなりに熱くなります。
なんかエラーが出ているのですが、どうもモデルのバージョンが合わないと言われているようです。
でもエンジンはできました。バージョンが合わずともできるようですね。


高解像度用のプロファイルを作る
続けて、高解像度用のプロファイルを作成します。
高解像度化する場合の注意点が、「TensorRTを使う場合は64で割り切れる解像度でなければならない」という制約です。
アップスケーラーを使う場合、最終的に生成される画像が64で割り切れる解像度でなければなりません。
スライダーの目盛りも、64ずつしか動きません。
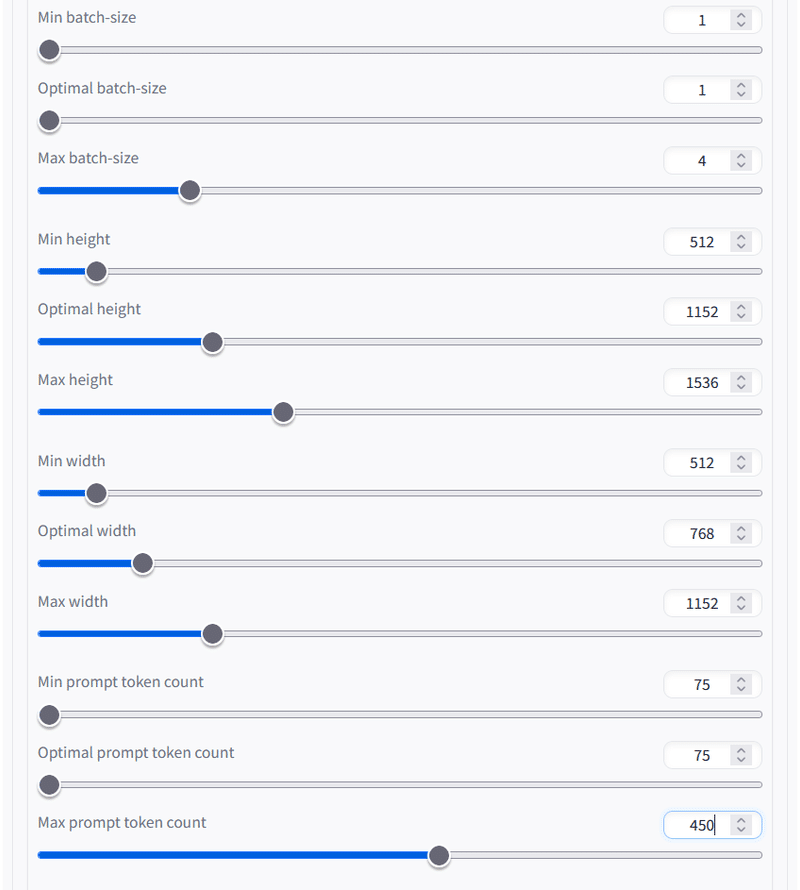
前回、スタティックプロファイルでは失敗することがわかりましたので、ダイナミックプロファイルを作成します。
「Batch Size 1-4」と書かれているものがダイナミックプロファイルになります。

また、生成画像の解像度の最低値と最大値に注意して下さい。
今回も、512x768の生成画像をアップスケーリングすることを想定していますので、最低値は縦・横ともに512pxとし、3対2でアップスケールして最終的な生成画像は1024x1536にしようと思います。
さらに、「TensorRTをアップスケールに使う場合、出力サイズを決め打ちにしたほうがいい」と言われていることと、「512の倍数だと失敗しやすい」という情報があるので、縦のOptimal heightと横のMax widthを1152pxにしています(真偽は不明ですが…)。

webui-user.batをTensorRT用に書き換える
もう一度webui-user.batを編集して、COMMANDLINE_ARGSの「--xformers」に替えて「--opt-sdp-attention」か「--opt-sdp-no-mem-attention」のどちらかを書きます。
これでSPDAが有効になります。
xFormersもPytorch 2.0に対応しているため、やろうと思えば併用することも可能です。
速度が速くなるかどうかは環境次第なので一概には言えないのですが、今のところTensorRTを利用する場合はxFormersを使わないほうが速かったという事例が多いようです。
2つのオプションがどう違うのかについては少し難しいのですが、--opt-sdp-attentionは絵柄の変化が大きく、--opt-sdp-no-mem-attentionは速度がわずかに劣るけど絵柄の変化が小さいと言われています。
また、同じシード値では--opt-sdp-no-mem-attentionのほうが同じ生成画像になりやすいという情報もあります。
ただし、--opt-sdp-attentionのほうがメモリ消費が大きいため、そこまでVRAMを搭載していない場合は--opt-sdp-no-mem-attentionのほうがいいようです。
リアル系モデルで女の子を描いてみる
リアル系モデルの作法がわからない…(汗)
作法というか、プロンプトのテクニックなどですね。
ワタクシ、二次元アニメモデルしか使ってこなかったため、リアル系モデルで日本人風の女の子を生成するプロンプトがよくわかりません。
仕方がないのでcivitaiから丸パクリしてきました(笑)。
今回の設定は下記の通りです。
アニメ系イラスト向きのアップスケーラーしかなかったので、「4x-UltraSharp」ををダウンロードして、512x768から1024x1536にアップスケールします。

10枚の生成時間は4分16秒
1024x1536を10枚生成して4分16秒かかりました。
勧められただけあって大きな破綻なく生成できたのではないでしょうか。
いいモデルですね。

私がリアル系のプロンプトに詳しくないため、civitaiからそのままコピペして若干変えました。
全員黒髪ロングなのはコピペ元がそういうプロンプトだったからで、私の趣味ではありません(笑)。

リアル系のプロンプトに詳しい方ならもっと可愛い子を生成できると思います。
私はAmpereアーキテクチャのRTX A4000を使っているため、グラフィックカードの性能としてはたぶん同じAmpereアーキテクチャのRTX3080と同じくらいではないかと思います。
単純な比較はできないのですが、高速化という観点ではけっこう向上したと思うのですがいかがでしょうか。
TensorRTエンジンを作成する時の注意事項
最後に注意事項です。
SPDAが有効の状態だとエンジン作成に失敗しやすい
どうもSPDAが有効になっている状態で高解像度用のTensorRTエンジンを作ると、うまくいかないことが多いらしいのです。
理由はよくわかりません…。
これは、今のところwebui-user.batを使い分けるしかなさそうです。
TensorRTエンジン作成時…「--xformers --no-half-vae」
TensorRTエンジン使用時…「--opt-sdp-attention --no-half-vae」
私はwebui-user.batにはどちらも書いておき、使用するもの以外はREMをつけてコメントアウトしています。

とにかくストレージ容量を食う
TensorRTは、その生成画像の解像度ごとにエンジンを作るのですが、ONNX形式とTensorRT形式をそれぞれ作るので、プロファイルごとに1.6GBものファイルが作られます。
今回、AOM3A1Bとyayoi_mix 2.5のデフォルトと高解像度のTensorRTエンジンを作成したのですが、ONNX形式が2つで3.2GB、TensorRT形式が4つで6.7GB、合計9.1GBというサイズになります。
もともとのモデルデータがsafetensors形式の場合は多くが1.98GBなので、この2モデルだけで13.88GBものストレージを消費していることになります。
作り過ぎには注意しましょう。
次はLoRAを試してみようと思っています。
この記事が気に入ったらサポートをしてみませんか?