No.008 ヤクルト村上の本塁打偏差値は?(2022/9/1現在)

1.今回の目的
スポーツナビのサイトからセリーグ打撃成績をスクレイビングし、
セリーグ規定打席到達メンバーの本塁打偏差値を集計します。
2.Reference
スクレイビングに関してこちらを参考にしました。
たった数行のPythonコードで打者大谷翔平がどれだけ凄いのかを見てみる - Lean Baseball (hatenablog.com)
標準偏差の算出に関してこちらを参考にしました。
列行指定のData抽出に関してこちらを参考にしました。
pandas DataFrameの行・列を抽出|loc, iloc, at, iatわかりやすく解説! - YutaKaのPython教室 (yutaka-note.com)
ObjectからInt型へのDataタイプ変更に関してこちらを参考にしました。
3.Pythonでのコード
下記のサイトから打撃成績のスクレイビングをします。
%matplotlib inline
import pandas as pd
url = 'https://baseball.yahoo.co.jp/npb/stats/batter?gameKindId=1&type=avg'
df = pandas.io.html.read_html(url,encoding='utf-8')Dataの確認
df[0]無事に読み込めました。しかし、27行目は不要です。

26行目までと選手名、本塁打のみのデータとします。
df2=df.iloc[0:27,[1,9]]
df2df2.info()
両方ともobject型になっています。本塁打をInt型に変更します。
df2["本塁打"] = df2["本塁打"].astype(int)ヒストグラムを見てみると、村上君は完全に外れ値です。
df2.hist()
標準偏差計算のため対象のカラムを指定してdf_homerunという名前のSeriesを作ります。
そして、標準偏差を求めますが、引数に何も指定しない場合(デフォルト)は不偏分散・不偏標準偏差の計算になります。そこで ddof=0 という引数を指定して母分散・母標準偏差の計算にする必要があります。
次に平均値を求めます。
#Seriesの作成
df_homerun = df2['本塁打']
#標準偏差を求める
df_homerun_std = df_homerun.std(ddof=0)
#平均値を求める
df_homerun_mean = df_homerun.mean()#偏差値の求め方は下記となります
#偏差値 = (得点 − 平均点) ÷ 標準偏差 × 10 + 50
df2['DeviationValue'] = df_homerun.map(lambda x: round((x - df_homerun_mean) / df_homerun_std * 10 + 50)).astype(int)df2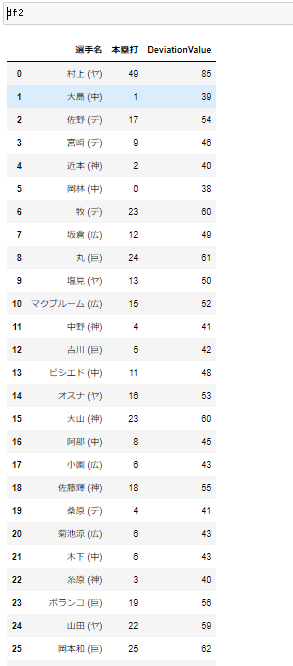
村上君のセリーグ本塁打偏差値は驚異の85をたたき出しました。
セリーグのTop27名の中での偏差値85なのでとにかくすごいということですね!野球をわからない人にもすごさが伝わると思います。
この記事が気に入ったらサポートをしてみませんか?